

Em março, Willem Berroubache apresentou no KubeCon + CloudNativeCon Europe 2026, em Amsterdam. Após a sessão, as mesmas perguntas surgiram no CNCF Slack e presencialmente: por que construir IA agentica sobre fundamentos cloud native? Quais projetos CNCF realmente fazem o trabalho pesado? Onde o humano se encaixa e como organizar as equipes? O que segue é a resposta curta, extraída de um sistema em desenvolvimento ativo na Orange Innovation.
O contexto: uma plataforma interna de segurança em tempo real, protegendo um ambiente de produção regulado, atualmente em desenvolvimento ativo com rollout em andamento. O protocolo A2A (open-source em 2025, agora sob a Linux Foundation) coordena os agentes. O MCP (hospedado na Agentic AI Foundation) integra os ambientes. O Falco com eBPF intercepta cada syscall nos workloads monitorados; os eventos fluem pelo Kafka para um modelo clássico de anomalia (Isolation Forest) que pré-filtra antes dos agentes baseados em LLM. O objetivo é encurtar materialmente o Mean Time to Detect e Respond, e transferir a autoria de regras dos analistas humanos para a camada de agentes.
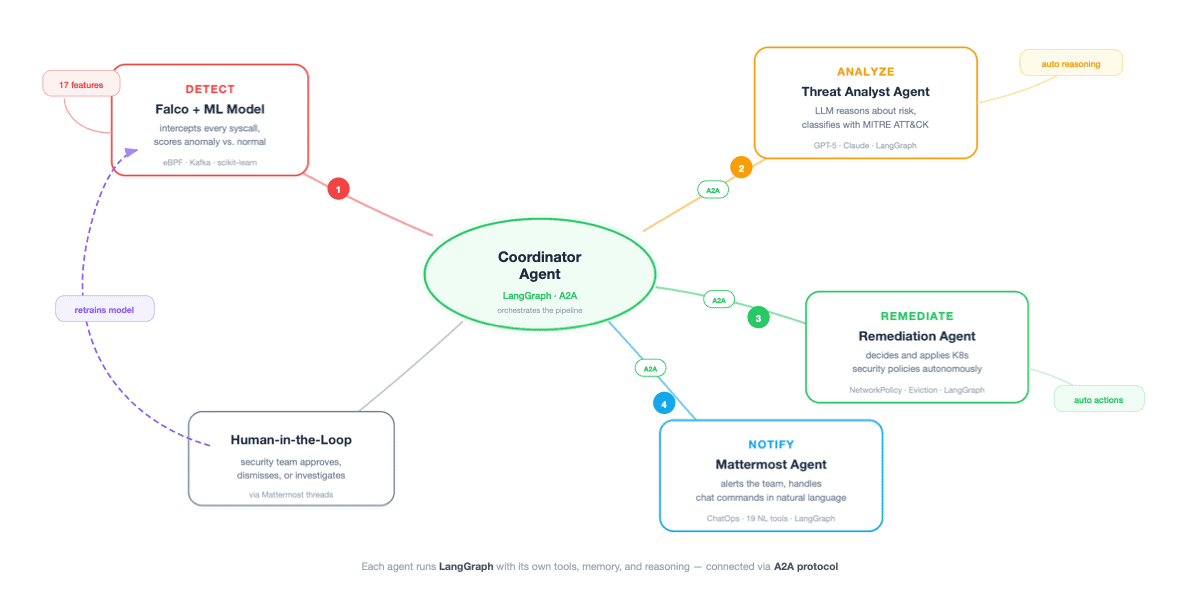
Figura 1: Visão geral do sistema. Um agente Coordenador (LangGraph + A2A) orquestra quatro agentes especializados: Detect (Falco + ML), Analyse (Threat Analyst), Remediate, e Notify (Mattermost), além de um ramo Human-in-the-Loop e um loop de feedback que retreina o modelo de anomalia. Adaptado da palestra no KubeCon + CloudNativeCon Europe 2026.
Abaixo, cinco lições técnicas que se sustentam até agora, e uma nota final sobre por que o stack CNCF e LF é o substrato certo para esse tipo de sistema.
Como cada agente é um workload Kubernetes, não um módulo in-process?
Cada agente é seu próprio Deployment, com seus próprios limites de recurso, identidade e política de restart. A maioria dos agentes usa LangGraph internamente para seu loop de raciocínio e uso de ferramentas; alguns poucos são escritos à mão sem framework, para controle mais fino (veja "Por que este stack" abaixo). A camada de agente se comporta como qualquer mesh de microserviços: canary rollouts, HPA, isolamento de namespace se aplicam sem invenção. O padrão oposto (todos os agentes em um único processo) é mais rápido de demonstrar em um laptop, mas estaria errado em produção: um agente preso em um timeout de modelo-API arrasta os outros para baixo.
O tráfego entre agentes precisa de mTLS, não de um service mesh?
As mensagens A2A carregam regras de detecção propostas e ações de resposta. O modelo de ameaça diz que são tão sensíveis quanto o data plane.
Não rodamos um service mesh. O cert-manager emite identidades por agente; os agentes realizam mTLS diretamente no seu transporte gRPC/HTTP, sem sidecar. O Cilium fornece o substrato de rede e o CiliumNetworkPolicy restringe quais identidades de agente podem alcançar qual servidor MCP. A combinação (cert-manager + mTLS em nível de agente + CiliumNetworkPolicy) é materialmente mais simples que um mesh e nos dá o que um mesh daria.
De todas as nossas escolhas até agora, o A2A é o que repetiria sem hesitação. Open-source em 2025, governado sob a Linux Foundation, não vinculado a um único framework, permitindo que operadores planejem um deployment de 3 a 5 anos. Parear o A2A (LF) com o stack CNCF (LF) coloca todo o substrato sob um guarda-chuva de governança open-source única, o que em indústrias reguladas é um argumento de procurement tanto quanto técnico.
Como as restrições de segurança dos agentes são policy-as-code, não raciocínio de prompt de LLM?
Na nossa arquitetura, um agente revisor decide se uma ação proposta é segura de executar (deploy de regra de detecção, contenção, mudança de firewall). O instinto é colocar as restrições de segurança no system prompt do revisor. Não faça isso.
Acima do revisor, um agente de análise de ameaça classifica cada escalada contra o framework MITRE ATT&CK, dando ao revisor uma entrada estruturada em vez de prosa LLM livre. Codificamos as restrições do revisor como políticas OPA e regras de admissão Kyverno. O revisor chama o OPA via MCP, obtém um veredito determinístico e age. O prompt do revisor é curto e, francamente, chato. A política é versionada, testada e revisada como qualquer outro artefato. Se há uma mudança a fazer antes de qualquer outra, é esta.
A observabilidade segue o trace_id do A2A, o GitOps controla a configuração?
O envelope A2A carrega um trace_id com cada tarefa; esse trace_id é o que mantém nossa observabilidade coesa. Os agentes emitem logs JSON estruturados com o trace_id, a identidade do agente, as chamadas MCP feitas e o uso de tokens LLM. O Prometheus coleta métricas por agente (taxas de requisição, latência de chamada MCP, proporções de auto-executar / auto-rejeitar / escalar). O Cilium Hubble fornece a visão de fluxo quando a pergunta é "o pod certo alcançou o serviço certo?".
A primeira vez que apresentamos uma decisão automatizada específica a um stakeholder durante o desenvolvimento, puxamos todas as entradas para aquele trace_id e as alinhamos. A cadeia de raciocínio inteira foi percorrida em cerca de 15 minutos. Sem a propagação do trace_id via A2A, teria sido um dia.
O system prompt, a lista de ferramentas e o schema de saída de cada agente são um Custom Resource do Kubernetes, reconciliado pelo Argo CD a partir do Git. O pacote de política do revisor vive no mesmo repositório. Promover uma mudança é um pull request: revisado, auditado, reversível. É aqui que a maioria dos deployments multi-agente iniciais cai: prompts espalhados por notebooks e arquivos de configuração até o dia em que um agente surpreende alguém.
Como um modelo clássico de anomalia faz o gate do LLM?
Se cada evento acionasse o fan-out completo dos agentes, o custo do LLM dominaria a economia da plataforma. Um Isolation Forest (scikit-learn) fica na frente dos agentes, pontuando cada amostra em microssegundos em 17 features; apenas amostras acima de um limiar calibrado alcançam o fan-out dos agentes. O LLM é invocado na pequena fração que parece genuinamente nova: exatamente o trabalho que um engenheiro de detecção humano costumava fazer. A latência por evento e o custo de tokens permanecem contidos, e o dimensionamento da camada LLM se torna planejamento de capacidade normal.
O Isolation Forest retreina semanalmente por design, e a deriva de distribuição de features é ela mesma uma métrica do Prometheus que gera páginas. O limiar de anomalia não é uma constante estática. É um parâmetro de política que o revisor consulta no momento da decisão. Podemos apertá-lo sob carga sem redeploy de agentes.
Como manter o humano no loop, por protocolo, não por cultura?
Toda decisão consequente tem três estados finais: Auto-executar. Auto-rejeitar. Ou escalar para um analista humano SOC no Mattermost, com a cadeia de raciocínio completa anexada e comandos ChatOps para aprovar, rejeitar ou investigar inline. O terceiro não é um caminho de erro; é uma saída normal do revisor. É projetado para disparar em três casos: a confiança do revisor cai abaixo do limiar; o ativo está em uma lista de sempre-escalar (componentes do data plane, lojas de identidade, qualquer coisa voltada ao cliente ou sensível à compliance); ou a ação proposta excederia um blast radius configurado.
"Este caso deve escalar?" é um veredito de política determinístico, versionado no Git, com seu próprio SLO e dashboards. Não é uma questão de qual analista está de plantão. Se sua história de HITL é "vamos adicionar um passo de aprovação depois", ou "o analista sempre pode intervir", você ainda não tem um.
Como o desenvolvimento e rollout realmente acontecem?
Conforme avançamos do desenvolvimento para o rollout, o modelo operacional já se parece com qualquer plataforma Kubernetes que rodamos antes. Alertas são estruturais: pacote de política falhou na admissão, latência p99 do servidor MCP, deriva do pré-filtro de anomalia, profundidade da fila A2A acima da marca d'água. Não "agente X deu uma resposta estranha". Quando um agente regride durante iteração, tratamos como qualquer regressão de microserviço em produção: rollback do Custom Resource via Argo CD, abrimos um ticket, enviamos um fix via GitOps. Nenhum runbook especial de incidente de agente para inventar, e esse é o ponto.
O que muda para o time SOC é a natureza do trabalho. A autoria de regras tem sido o gargalo estrutural por anos; transferi-la para a camada de agente é o objetivo explícito. Os engenheiros irão curar a política de segurança do revisor e auditar as regras deployadas no lugar de escrevê-las. Os artefatos do dia a dia (CRDs, políticas, pull requests do GitOps) são aqueles que o SOC e os times de plataforma já sabem como tratar juntos.
Como o trabalho é organizado entre times e comunidade?
Nada disso funciona sem times integrados. Três grupos tocam este sistema toda semana: o SOC, dono dos outcomes de detecção e da política de segurança do revisor; o time de plataforma, dono do cluster, pipeline de GitOps e runtime dos agentes; e um pequeno grupo de engenharia de IA, dono dos contratos de agente e do modelo de anomalia. Mantivemos deliberadamente os contratos entre eles estreitos e legíveis por máquina (CRDs, pacotes OPA, schemas A2A), para que uma mudança em uma área nunca dependa de uma reunião em outra.
O ganho operacional que buscamos não é apenas velocidade; é capacidade. Escalar cobertura de detecção costumava significar contratar mais analistas para escrever mais regras. Com a camada de agente, significa deployar mais réplicas de agente e apertar o pacote de política do revisor — uma alavanca significativa em um problema que era limitado por headcount, e tempo de volta para analistas em casos que realmente precisam de um humano.
Externamente, o sistema também existe em uma comunidade. O CNCF Landscape e os sinais de maturidade associados (Sandbox, Incubating, Graduated, além de dados de adoção e governança) moldam ativamente nossas escolhas técnicas: quando avaliamos ferramentas de policy enforcement de rede, emissão de identidade ou detecção de anomalias, o Landscape nos deu um ponto de partida vendor-neutral e a maturidade do projeto nos disse o que podemos rodar responsavelmente em um ambiente de produção regulado. A mesma lente decide onde contribuímos de volta. Rastreamos issues upstream nos repositórios A2A e MCP, reportamos o que encontramos, e alimentamos lições de volta nos working groups do CNCF. KubeCon talks e threads no CNCF Slack são parte do loop, não reflexões tardias. Escolher protocolos cloud native e governados pela LF significa que não somos os únicos a melhorar o substrato.
Por que este stack?
Se algo parece tratável no papel, é porque os projetos CNCF e da Linux Foundation em que nos baseamos são simplesmente bons. Eles nos permitem tratar IA agentica como um workload cloud native normal, não como um caso especial. Kubernetes torna deployment chato da melhor forma. Falco nos dá um substrato de detecção em nível de syscall que não precisamos escrever. Cilium e Hubble levam a sério a identidade em políticas de rede. cert-manager transforma mTLS por agente em configuração. OPA e Kyverno tornam policy-as-code o padrão. Argo CD torna GitOps para CRDs de agentes uma implementação de um dia. Prometheus é a camada de métricas na qual o mundo cloud native roda.
No lado da IA agentica, AAIF dá ao MCP um lar neutro e o A2A é governado sob a Linux Foundation. LangGraph é o runtime de agente que escolhemos após testar alternativas, mas não é o único caminho: frameworks como CrewAI, AutoGen e LlamaIndex ocupam o mesmo espaço, e para alguns de nossos agentes mantemos a lógica escrita à mão sem framework algum, para controle total sobre máquinas de estado, semânticas de retry e sequenciamento de chamadas de ferramentas. Os protocolos (A2A, MCP) são o que tratamos como as interfaces duráveis; o runtime é uma escolha que podemos revisitar.
O que fica claro: a IA agentica herda todos os problemas operacionais que o cloud native já resolveu (identidade, isolamento, política, observabilidade, GitOps). Inventar substratos paralelos é desperdício de movimento. E o caminho humano e os contratos de equipe precisam ser saídas normais do sistema, não exceções acopladas.
Perguntas Frequentes
- Qual é o principal erro ao projetar agentes de segurança nessa arquitetura?
- Colocar todas as restrições de segurança no prompt do LLM do revisor. O artigo mostra que isso deve ser substituído por política-as-código (OPA + Kyverno), que é determinística, versionada e testável, evitando o risco de decisões imprevisíveis baseadas em raciocínio probabilístico.
- Como saber se seu sistema agentico está pronto para produção?
- Quando os alertas são estruturais (ex: falha de admissão de pacote de política) e não ad-hoc (ex: "resposta estranha do agente"). Quando um rollback é feito via GitOps de um Custom Resource, não via script de recuperação especial. A repetibilidade operacional é o indicador-chave.
- Por que usar mTLS direto entre agentes em vez de service mesh?
- O artigo demonstra que, para tráfego A2A (que carrega dados tão sensíveis quanto o data plane), a combinação de cert-manager + mTLS no nível do agente + CiliumNetworkPolicy é materialmente mais simples, mais segura e mais alinhada com a necessidade de isolamento em ambientes regulados, sem a complexidade adicional de um mesh.
- Como evitar que o custo do LLM domine a plataforma?
- Implementando um modelo clássico de pré-filtro (Isolation Forest) que avalia todos os eventos em microssegundos. Apenas eventos acima de um limiar calibrado acionam o LLM. Isso mantém a latência e o custo de tokens previsíveis, transformando o dimensionamento em planejamento de capacidade normal.
- Quando escalar para um humano é um sinal de falha do sistema?
- Nunca. O artigo descreve o escalonamento como um resultado normal e projetado do revisor, baseado em três critérios determinísticos (confiança, criticidade do ativo, blast radius). O caminho de escalada humano não é um erro; é uma saída esperada, governada por política e SLAs.
Artigo originalmente publicado por Willem Berroubache, Lead Security Architect (Orange Innovation) and CNCF Golden Kubestronaut. em Cloud Native Computing Foundation.
