

TL;DR — O Microsoft Foundry lançou um sampler de diversidade (MinHash farthest-first) que substitui a amostragem uniforme ao criar datasets de traces de agentes. Nos testes, o método produziu ganhos de +29,1% em diversidade lexical e +44,8% em vocabulário, com preferência de 78% dos LLM judges para avaliação e 71% para treino. A técnica prioriza cobertura de comportamento sobre representatividade da distribuição de produção — ideal para workloads de avaliação e fine-tuning.
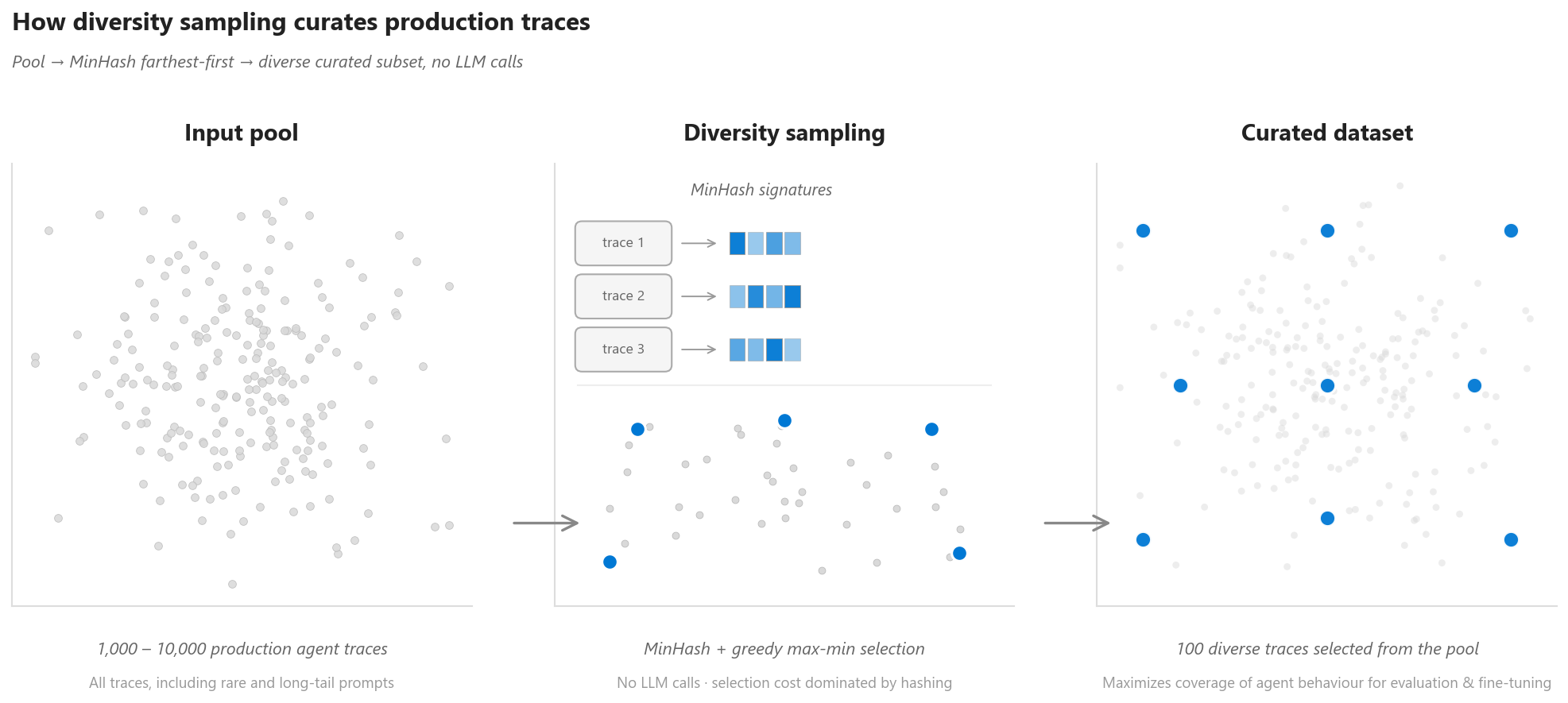
Figura 1. Visão geral do fluxo de amostragem inteligente: pool de traces de agente, etapa de seleção MinHash farthest-first e o subconjunto curado que maximiza a cobertura do comportamento do agente.
Por que a seleção de traces importa?
A abordagem mais simples é a amostragem uniforme aleatória. Ela é não-viesada e preserva a distribuição real do tráfego de produção — a escolha certa quando espelhar frequências de produção é crucial. Mas a amostragem uniforme tem uma fraqueza conhecida: quando o tráfego real é dominado por poucos padrões comuns, a amostra uniforme é dominada por esses mesmos padrões. Prompts raros, sequências incomuns de tool-call e edge cases são sistematicamente sub-representados — exatamente os casos que a avaliação deve testar e que o fine-tuning precisa aprender.
A amostragem por diversidade ataca esse problema explicitamente. O objetivo é selecionar um subconjunto que cubra o máximo possível do espaço de entrada — incluindo as regiões menos frequentes que uma amostra uniforme perderia. Por design, ela prioriza cobertura sobre representatividade, tornando-se particularmente adequada para fluxos de avaliação e fine-tuning onde a amplitude de comportamento é o que importa.
A técnica: MinHash + travessia farthest-first
A amostragem inteligente roda server-side no Foundry sem chamadas a LLM e sem dependências externas de modelos de embedding — a seleção é puramente baseada em hashing, custo zero por token e leva de segundos a minutos. Ela combina dois componentes clássicos:
Assinaturas MinHash. O texto de cada trace é tokenizado em shingles e hasheado com 128 permutações. A assinatura resultante permite estimar a similaridade de Jaccard entre qualquer par de traces em tempo constante, sem armazenar ou comparar o texto original. É o mesmo truque usado na detecção de quase-duplicatas em mecanismos de busca.
Travessia farthest-first. A partir de um trace semente, seleciona-se repetidamente o trace cuja similaridade mínima com qualquer trace já selecionado é a menor — ou seja, o trace mais diferente de tudo que já foi escolhido. Esse algoritmo guloso é uma aproximação padrão para o problema de seleção de subconjunto de máxima diversidade.
A amostragem por diversidade — o algoritmo MinHash farthest-first — é o mecanismo central usado ao criar um dataset a partir de traces. Ele é executado após etapas de suporte: deduplicação exata para remover traces redundantes, filtros rígidos para descartar traces malformados ou triviais, e agregação entre execuções do agente. O custo de seleção é independente do conteúdo dos traces, escala linearmente com o tamanho do pool e é dominado pela hashing — insignificante comparado ao custo de rodar a avaliação ou o fine-tuning que consome o resultado.
Como validamos o método
Dividimos a validação em quatro estudos complementares:
Métricas intrínsecas de diversidade. Diversidade unigrama (tokens únicos divididos por tokens totais, medida normalizada por comprimento) e tamanho do vocabulário. Agregados em 5 seeds aleatórias e comparados via testes t pareados.
Preferência LLM-as-judge. Um juiz cego GPT-4.1 avaliou comparações pareadas (subset diversity vs. uniform-random, cada um com 10 exemplos) em 268 julgamentos, três tamanhos de dataset (1k/5k/10k) e cinco seeds. O juiz respondeu qual subset geraria melhor dataset de avaliação e melhor dataset de treino. Um segundo juiz (GPT-5.2) replicou o resultado em 50 comparações para testar robustez.
Fine-tuning supervisionado downstream. Fine-tuning do GPT-4.1 via API padrão OpenAI em dois subsets de 80 exemplos do WildChat (um diversity-sampled, um aleatório), com 20 exemplos de validação e 3 épocas cada. Medimos convergência (train loss, validation loss, token accuracy) e qualidade de geração em 48 prompts não vistos, julgados por um GPT-4.1 cego.
Qualidade em datasets com anotação humana. Reexecutamos o sampler em três datasets com anotações humanas genuínas — HelpSteer2 (profissionais Scale AI), OASST2 (13,5 mil voluntários) e Summarize from Feedback (crowd workers) — para verificar se a seleção por diversidade escolhe sistematicamente itens de menor qualidade.
Todos os experimentos usam cinco seeds determinísticas para a baseline aleatória, testes t pareados para significância e a mesma configuração do sampler (num_perm=128, alpha=0.35, target=100). O dataset principal é WildChat (subsets de 1k, 5k e 10k de conversas reais), complementado por cinco estudos cross-dataset: Dolly, No Robots, OASST2, ShareGPT-GPT4 e UltraChat. A validação de qualidade usa HelpSteer2, OASST2 e Summarize from Feedback.
O que os dados mostram
Antes dos números agregados, vejamos o que a amostragem por diversidade realmente faz em traces reais de produção. Incorporamos todos os 5.000 prompts do WildChat com um modelo sentence-transformer e projetamos em 2D — cada ponto cinza é um trace, e os marcadores coloridos são os 100 traces selecionados por cada método:
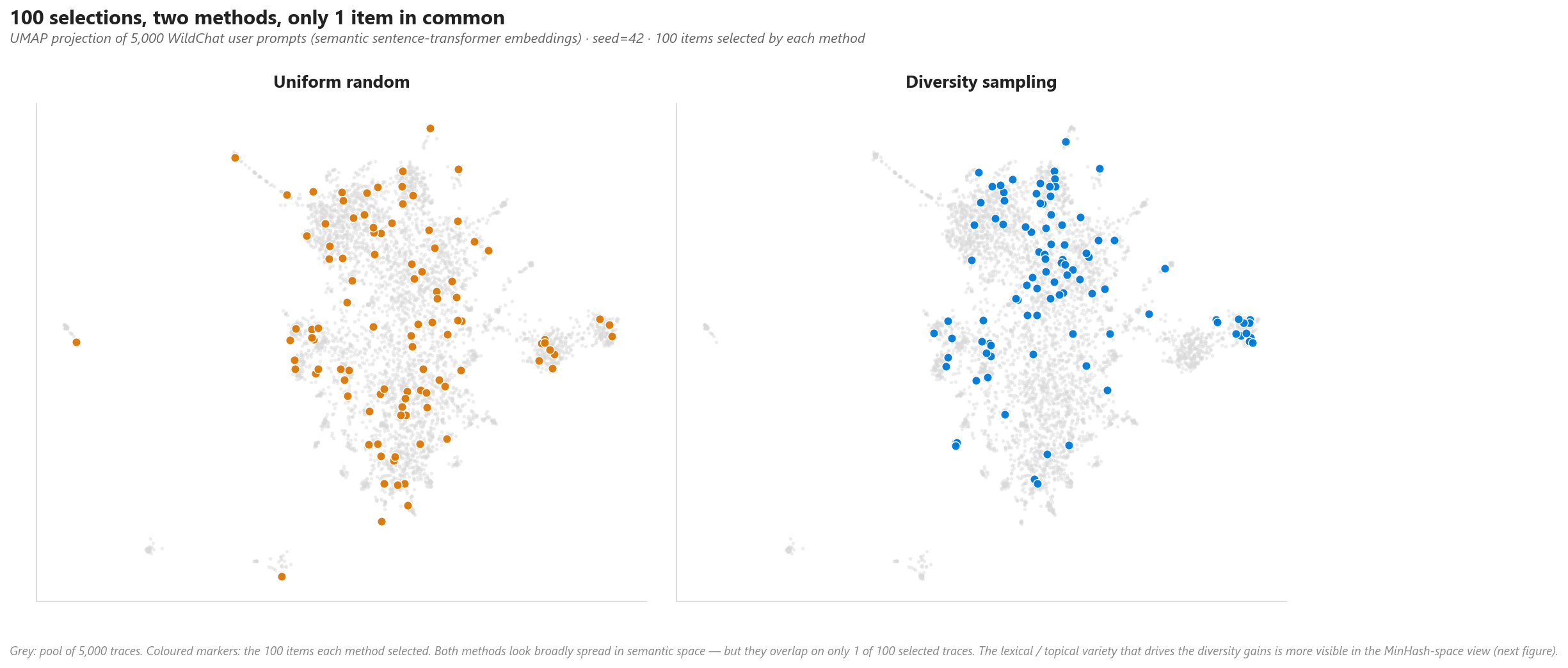
Figura 2. Visão semântica — UMAP dos embeddings. Cada ponto cinza é um trace; marcadores coloridos são os 100 traces de cada método. Ambos parecem espalhados no espaço semântico, mas compartilham apenas 1 dos 100 traces selecionados — os métodos atingem conteúdo genuinamente diferente.
Em segundo lugar, o espaço MinHash–Jaccard que o algoritmo de fato otimiza. Em vez de uma projeção 2D (que perde informação de distância fina), plotamos as distribuições de distância diretamente:
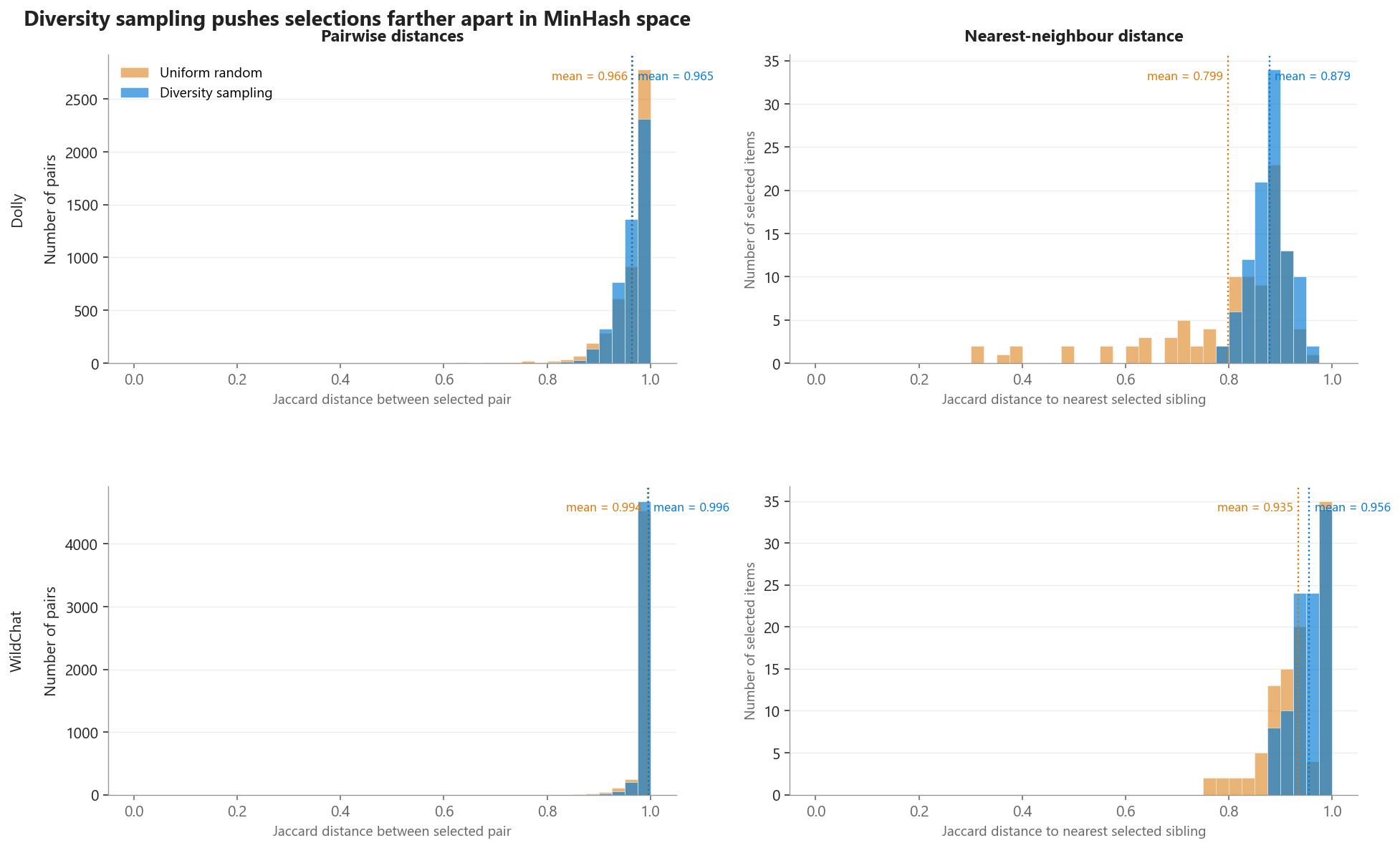
Figura 3. Distribuições de distância Jaccard par a par (esquerda) e vizinho mais próximo (direita) entre os 100 itens selecionados, nos datasets Dolly e WildChat. A amostragem aleatória produz uma longa cauda esquerda na distância do vizinho mais próximo — alguns picks aleatórios têm irmãos quase duplicados no conjunto. A amostragem por diversidade maximiza explicitamente a distância mínima de cada seleção, deslocando toda a distribuição para a direita.
Os dois métodos selecionam traces quase totalmente diferentes (99 únicos cada, 1 em comum). A diferença visual já antecipa o que as métricas agregadas mostrarão. O resto desta seção quantifica o gap em quatro eixos independentes.
Ganhos de diversidade são grandes e consistentes
No dataset principal WildChat (pool de 5k, 100 selecionados, 5 seeds), a amostragem por diversidade produz subconjuntos mensuravelmente mais diversos:
| Métrica | Diversity sampling | Random | Δ% | p-value |
|---|---|---|---|---|
| Diversidade unigrama | 0,307 | 0,238 | +29,1% | 0,010 |
| Tamanho do vocabulário | 7.019 | 4.849 | +44,8% | 0,003 |
Os ganhos de vocabulário se generalizam para cinco datasets adicionais (Dolly +5,7%, No Robots +44,5%, OASST2 +55,7%, ShareGPT-GPT4 +86,3%, UltraChat +49,3%), com os maiores efeitos em dados humanos.
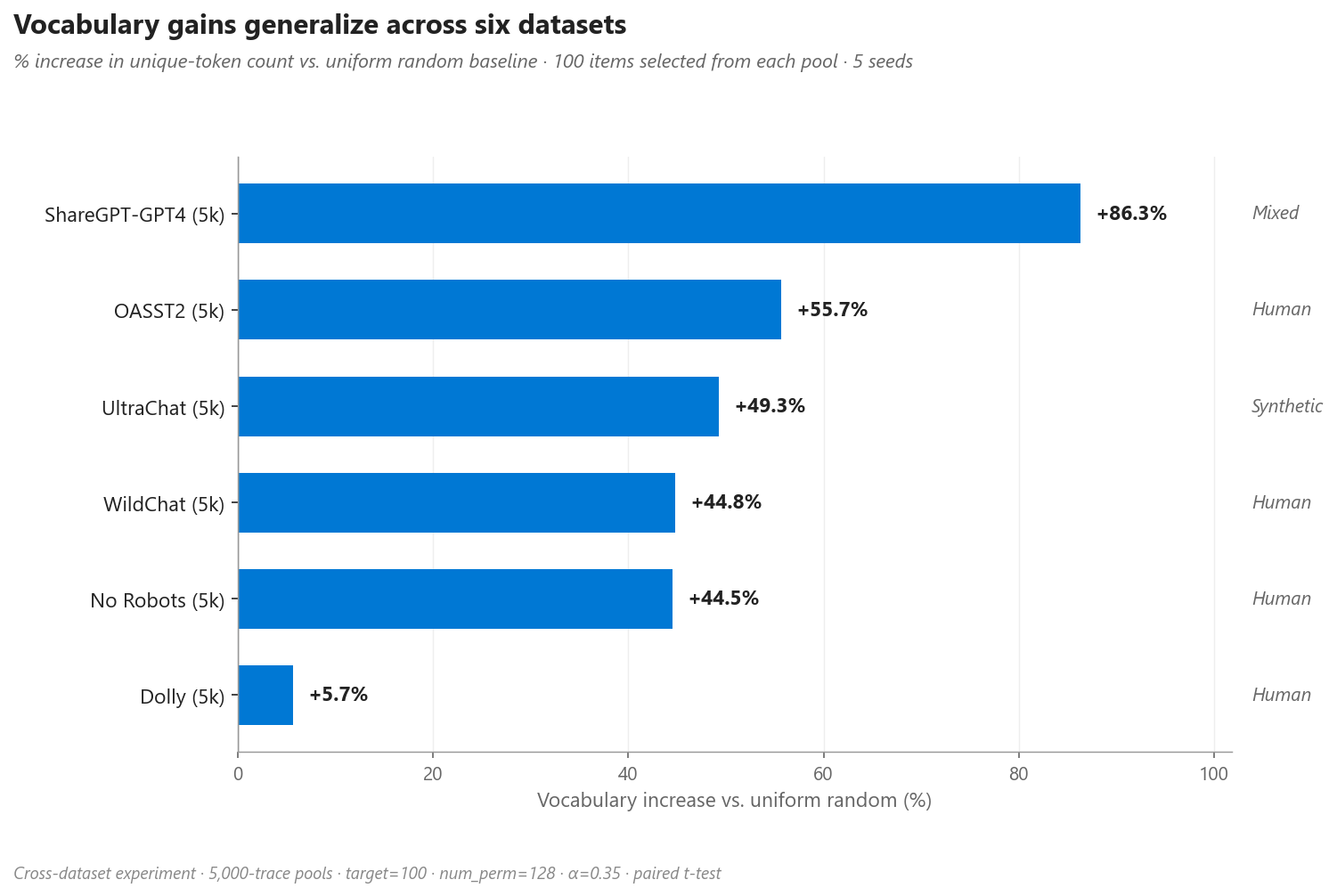
Figura 4. Aumento de vocabulário relativo à baseline uniforme em seis datasets. Todos os ganhos são positivos, mas variam conforme a riqueza lexical do pool subjacente.
LLM judges preferem dados amostrados por diversidade
Realizamos 268 julgamentos pareados com GPT-4.1 em duas formulações (qual amostra produz melhor dataset de avaliação e qual produz melhor dataset de treino). Taxas de vitória agregadas:
| Formulação | Diversity wins | Random wins |
|---|---|---|
| Dataset de avaliação | 78,0% (209/268) | 22,0% (59/268) |
| Dataset de treino | 71,3% (191/268) | 28,7% (77/268) |
Os subsets amostrados por diversidade vencem em todos os três tamanhos de dataset (1k, 5k, 10k). Um segundo juiz GPT-5.2 em 50 comparações reproduziu a mesma direção, com 76% de concordância bruta na avaliação e 68% no treino.
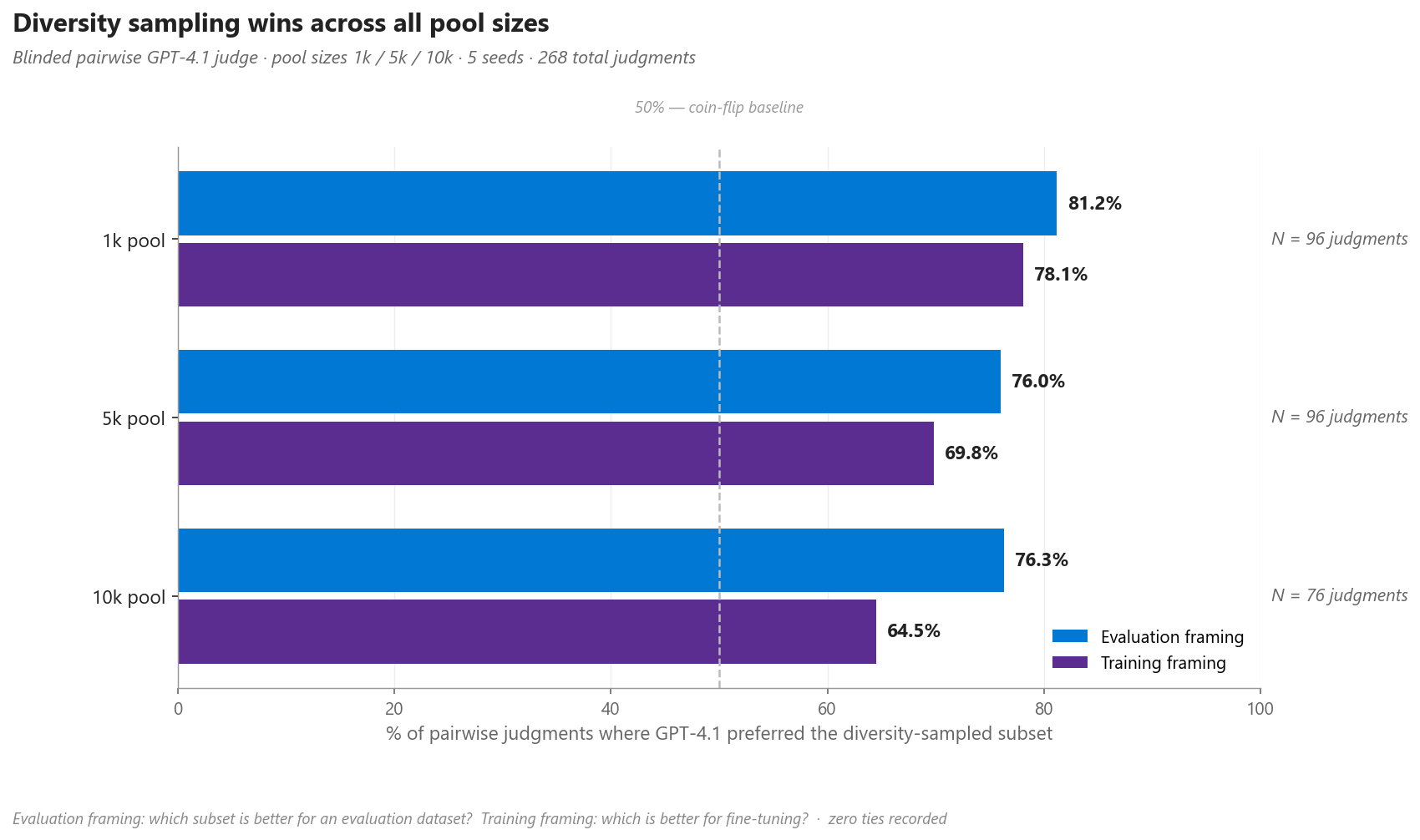
Figura 5. Taxas de vitória pareadas para o subset diversity-sampled, nas formulações de avaliação e treino, por tamanho de pool. A linha tracejada em 50% é a baseline de cara-ou-coroa; todas as barras estão bem acima.
Ganho de vocabulário e preferência do juiz medem coisas diferentes — variedade lexical vs. sinal holístico de qualidade. Eles geralmente concordam, mas nem sempre:
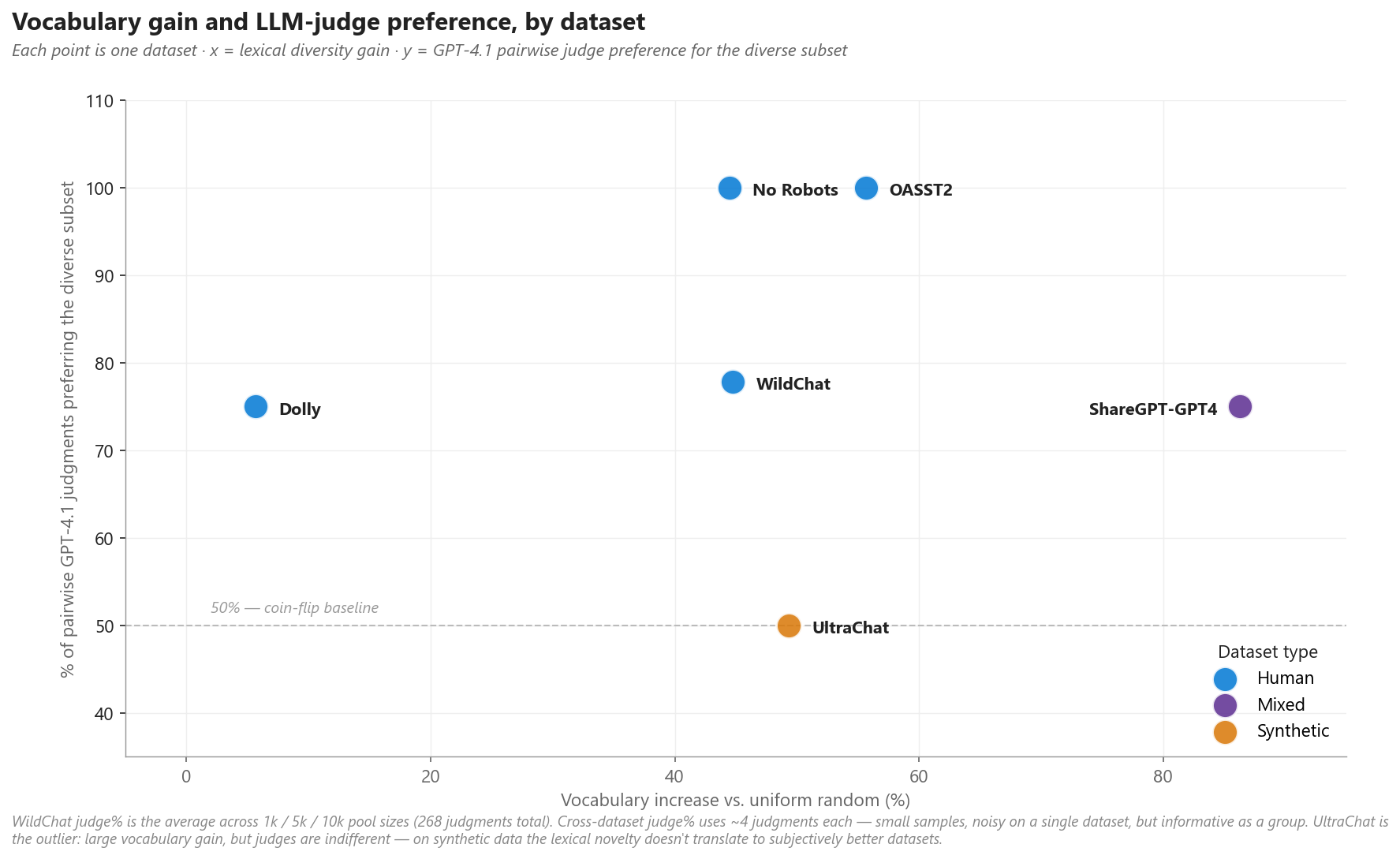
Figura 6. Ganho de vocabulário vs. preferência do LLM, um ponto por dataset. Quatro datasets ficam na região win-win. UltraChat é o outlier: ganho de +49% em vocabulário que não se traduz em preferência do juiz — em dados totalmente sintéticos, a novidade lexical é real, mas os juízes não veem o subset como significativamente melhor.
O resultado do UltraChat é informativo: em datasets sintéticos — onde ambos os lados da conversa são gerados por modelo — a amostragem por diversidade ainda encontra variedade lexical, mas os juízes não consideram o subset melhor, provavelmente porque as conversas subjacentes já são homogeneamente formuladas.
Fine-tuning: convergência mais rápida, qualidade final similar
Realizamos fine-tuning supervisionado no GPT-4.1 usando a API padrão OpenAI: dois subsets de 80 exemplos do WildChat (diversity-sampled vs. aleatório), 20 exemplos de validação, 3 épocas cada.
| Métrica | Diversity sampling | Random | Δ |
|---|---|---|---|
| Train loss final | 0,547 | 0,908 | −40% |
| Token accuracy (treino) | 85,3% | 76,7% | +8,6pp |
| Validation loss | 0,869 | 0,873 | comparável |
| Holdout pairwise (N=48) | 37,5% wins | 33,3% wins | não significativo |
As dinâmicas de treino diferem fortemente: o modelo diversity-sampled converge na época 2 e atinge 40% menos loss. Na qualidade de geração, ambos os modelos têm desempenho comparável — confirmando que a vantagem de diversidade não prejudica a qualidade downstream.
Qualidade se mantém em datasets com anotação humana
Uma preocupação natural é que a amostragem por diversidade possa sobre-selecionar itens difíceis, estranhos ou de baixa qualidade. Testamos em três datasets:
| Dataset | Anotadores | Dimensão | Diversity | Random | Δ% |
|---|---|---|---|---|---|
| HelpSteer2 | Profissionais Scale AI | Helpfulness (0–4) | 2,66 | 2,94 | −9,7% |
| OASST2 | 13,5K voluntários | Quality (0–1) | 0,72 | 0,67 | +8,1% |
| Summarize FB | Crowd workers | Overall (1–7) | 5,16 | 4,77 | +8,3% |
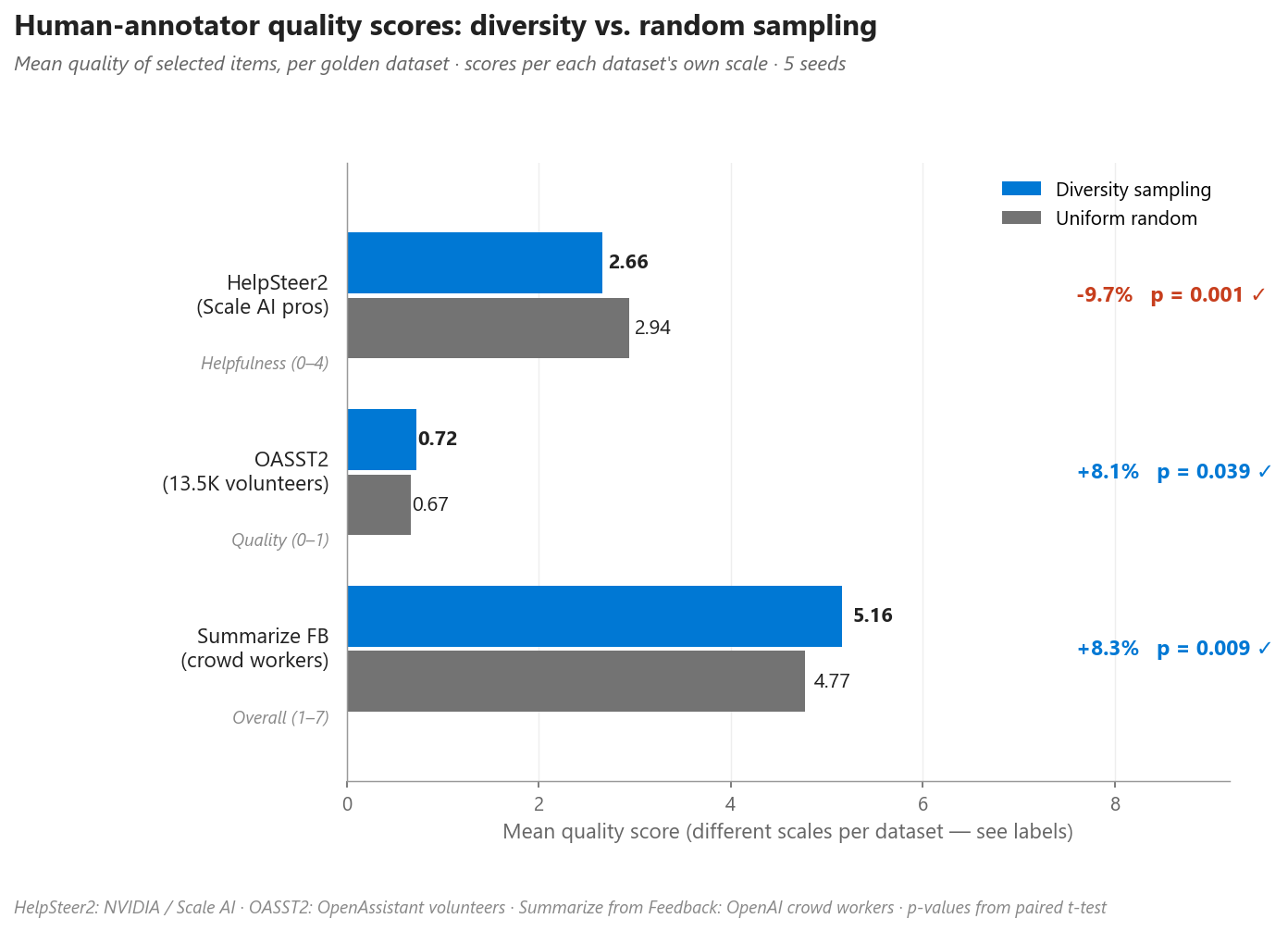
Figura 7. Scores de qualidade humana para subsets diversity-sampled vs. uniform-random. Diversity sampling produz ganhos significativos em OASST2 e Summarize from Feedback, e queda significativa no HelpSteer2 — veja os exemplos qualitativos na próxima seção.
Em dois dos três datasets, a amostragem por diversidade seleciona itens com maior qualidade segundo anotadores humanos. No HelpSteer2 a tendência se inverte: a diversidade escolhe mais prompts de escrita criativa, roleplay e tópicos de nicho, que os anotadores consideram mais difíceis e portanto menos úteis.
Para visualizar onde está o gap de qualidade no HelpSteer2, veja a distribuição completa dos scores:
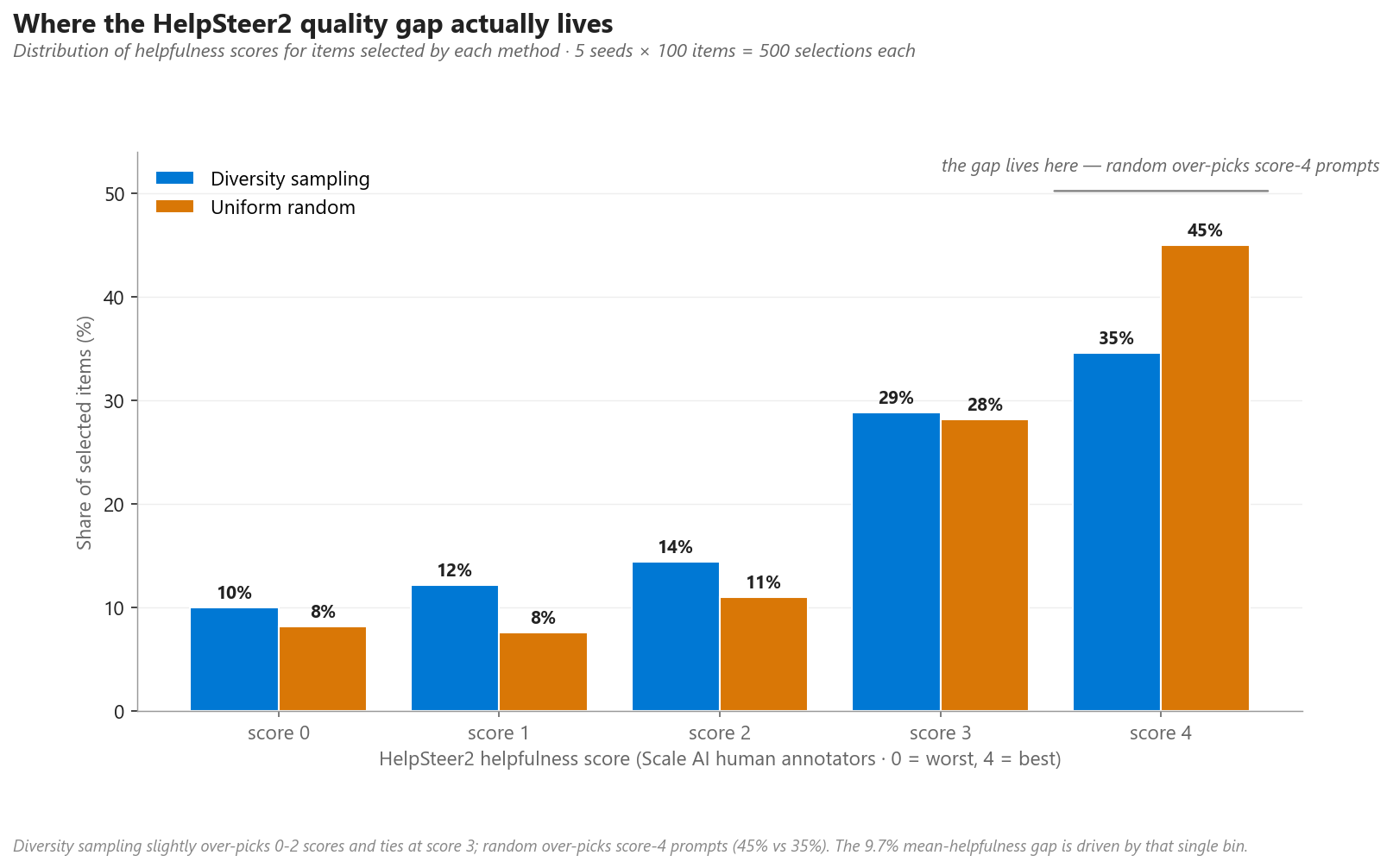
Figura 8. Distribuição dos scores de helpfulness no HelpSteer2 para 500 itens selecionados por cada método (5 seeds). A amostragem por diversidade sobrepõe levemente itens de score baixo e médio (0–2) e empata no score 3, enquanto o random sobrepõe os prompts de score 4 (45% vs. 35%) — as perguntas mais comuns e bem-trilhadas. O gap de 9,7% na média é quase todo desse único bin de score 4.
Nota: o Summarize from Feedback é uma tarefa de sumarização (artigos Reddit / CNN), não instruction-following geral. Incluímos para amplitude metodológica.
O que o sampler realmente seleciona
Para tornar o trade-off diversidade-vs-cobertura concreto, veja exemplos reais de itens selecionados por cada método no HelpSteer2 (seed=42). Dos 100 itens selecionados por cada método, apenas 3 se sobrepõem — os métodos escolhem subconjuntos quase completamente diferentes.
Exemplos diversity-sampled (selecionados pela diversidade, ignorados pelo random):
| # | Prompt do usuário (truncado) | Helpfulness | Correctness | Coherence |
|---|---|---|---|---|
| 1 | I have a vacation rental website and I am looking for alliterative and descriptive headlines that are 4–5 words in length. Examples: "Get Away to Galveston", "Sleep Soundly in Seattle". Each headline should have at least 50% alliteration… | 2 | 2 | 4 |
| 2 | You are a branding consultant with a creative mind. Give me 30 naming ideas for a baby’s website for parents in a table format. | 1 | 1 | 2 |
| 3 | my table has dates and USD values. give me historical exchange rates for each date for USD to Euro. also the converted USD to EU value: 01/02/2021 84.62 / 01/03/2021 79.48 / 01/04/2021 79.69 / 01/05/2021 38.06 / 01/06/2021 58.46… | 0 | 0 | 2 |
Exemplos aleatórios (selecionados pelo random, ignorados pela diversidade):
| # | Prompt do usuário (truncado) | Helpfulness | Correctness | Coherence |
|---|---|---|---|---|
| 1 | How to cook t-bone in the oven | 4 | 4 | 4 |
| 2 | Create a 4-day dumbbell and EZ-bar workout program to build over 10lbs of muscle in 3 months | 3 | 3 | 4 |
| 3 | How did life originate? | 3 | 3 | 4 |
Os prompts diversity-sampled são incomuns, criativos e subespecificados — exatamente o tipo de entrada que um conjunto de avaliação ou fine-tuning deve stress-testar. Os prompts aleatórios são solicitações comuns e bem-trilhadas, onde os modelos já produzem respostas confiáveis. O gap de qualidade (3–10%) é consequência direta dessa mudança de conteúdo, não um sinal de que a amostragem por diversidade está selecionando trabalho de qualidade inferior.
Considerações
A amostragem por diversidade é um padrão poderoso para workloads de avaliação e fine-tuning, mas algumas ressalvas são honestas:
- Cobertura, não representatividade. Por design, enfatiza amplitude de comportamento em vez de espelhar frequências de produção. Para casos que precisam de uma estimativa fiel da população (latência, taxas de erro), a amostra uniforme é mais adequada.
- Dados sintéticos têm ganhos menores. Em datasets totalmente sintéticos (ex.: UltraChat), as conversas subjacentes já são pré-diversificadas pelo processo de geração, reduzindo o sinal para a técnica.
- Qualidade do modelo fine-tuned é comparável, não dramaticamente melhor. A amostragem por diversidade acelera a convergência e produz datasets mais ricos, mas na qualidade de geração hold-out é equivalente à baseline uniforme.
- O trade-off diversidade-vs-qualidade é específico do dataset. Dois de três datasets com anotação humana mostraram scores de qualidade mais altos com diversidade; um (HelpSteer2) mostrou scores mais baixos, impulsionados pela seleção de prompts mais difíceis e criativos.
Onde a amostragem por diversidade brilha
| Workload | Adequação |
|---|---|
| Seleção de dados para fine-tuning | Forte — convergência mais rápida, cobertura mais ampla |
| Geração de rubrica e evaluator | Forte — revela temas de avaliação mais claros |
| Suites de avaliação long-tail | Forte — maximiza cobertura do espaço de entrada |
| Treino crítico de qualidade | Forte — combine cobertura de diversidade com revisão manual dos itens selecionados |
| Benchmark de distribuição de produção | Fraco — amostra uniforme espelha frequências reais |
| Dados pré-curados ou sintéticos | Fraco — os dados já são diversos |
Considerações finais
A amostragem inteligente — MinHash diversity sampling — oferece aos desenvolvedores do Foundry uma maneira rápida e sem custo extra de curar datasets de maior cobertura a partir de traces de produção. Na nossa avaliação, a técnica entregou ganhos mensuráveis de diversidade, foi fortemente preferida por LLM judges tanto para avaliação quanto para treino, e acelerou a convergência do fine-tuning — tudo em menos de um minuto em pools típicos de traces.
Vale manter o escopo claro: a técnica é projetada para amplitude de comportamento, não para representação fiel das frequências de produção. Para a maioria dos workloads de avaliação e fine-tuning, cobertura mais ampla é exatamente o que se quer — e é aí que este recurso realmente brilha.
Perguntas Frequentes
-
O que é amostragem inteligente no Microsoft Foundry?
É um recurso que seleciona automaticamente um subconjunto diverso de traces de agentes de produção usando o algoritmo MinHash farthest-first. Ele prioriza cobrir o máximo possível do espaço de entrada, em vez de espelhar a distribuição real do tráfego, sendo ideal para criar datasets de avaliação e fine-tuning. -
Quais são os ganhos reais em diversidade lexical?
No dataset WildChat (5.000 traces, 100 selecionados), a amostragem por diversidade obteve +29,1% de diversidade unigrama e +44,8% de tamanho de vocabulário em relação à amostragem uniforme. Em outros cinco datasets, os ganhos de vocabulário variaram de +5,7% a +86,3%, sendo maiores em dados humanos e menores em dados sintéticos. -
A técnica é útil para fine-tuning de modelos?
Sim. No experimento com fine-tuning do GPT-4.1, a amostragem por diversidade reduziu o loss de treino em 40% e acelerou a convergência (época 2 vs. random), mantendo qualidade de geração comparável. A vantagem está na cobertura mais ampla dos dados de treino, não na melhoria drástica do modelo final. -
Quando devo evitar usar este sampler?
Evite para workloads que exigem fidelidade à distribuição real de produção, como benchmarks de latência ou taxas de erro. Também é menos eficaz em datasets sintéticos já pré-diversificados (ex.: UltraChat) e pode selecionar prompts mais difíceis ou criativos, reduzindo a pontuação de qualidade em métricas como helpfulness no HelpSteer2. -
A amostragem inteligente tem custo computacional adicional?
Não. O algoritmo roda server-side sem chamadas a LLM ou modelos de embedding; é baseado em hashing (MinHash) e percorre os traces uma vez. O custo é dominado pela hashing e escala linearmente com o tamanho do pool — negligenciável comparado ao custo de rodar a avaliação ou o fine-tuning.
Artigo originalmente publicado em Azure Updates - Latest from Azure Charts.
