

O Microsoft Foundry acaba de lançar em preview uma funcionalidade que promete mudar a forma como times de IA medem a qualidade de seus modelos e agentes. Em vez de confiar apenas em leaderboards genéricos, agora é possível executar benchmarks padronizados diretamente no seu deployment, com sua configuração e seu judge model. Para empresas brasileiras que dependem de IA para crescer, isso significa mais controle sobre regressões, fine-tunes e decisões de custo versus qualidade.
TL;DR: A Microsoft Foundry lançou benchmarks padronizados (preview) para avaliar deployments de modelos e agentes de IA. Diferente do leaderboard geral, esses benchmarks medem o desempenho real do seu deployment com sua configuração. Isso é crucial para comparar versões, validar fine-tunes e evitar regressões em agentes. O artigo explica os benchmarks disponíveis, como executá-los via portal ou API REST, e as melhores práticas para incorporar medição confiável no ciclo de desenvolvimento — fundamental para empresas brasileiras que querem escalar IA com controle de qualidade.
Introdução
Benchmarks no Microsoft Foundry (preview) tornam esse tipo de medição uma parte de primeira classe do workflow de desenvolvimento. Você pode executar benchmarks open-source conhecidos contra qualquer deployment de modelo ou agente no seu projeto, comparar execuções lado a lado na visualização de evaluation group e controlar todo o fluxo pelo portal ou pela REST API.
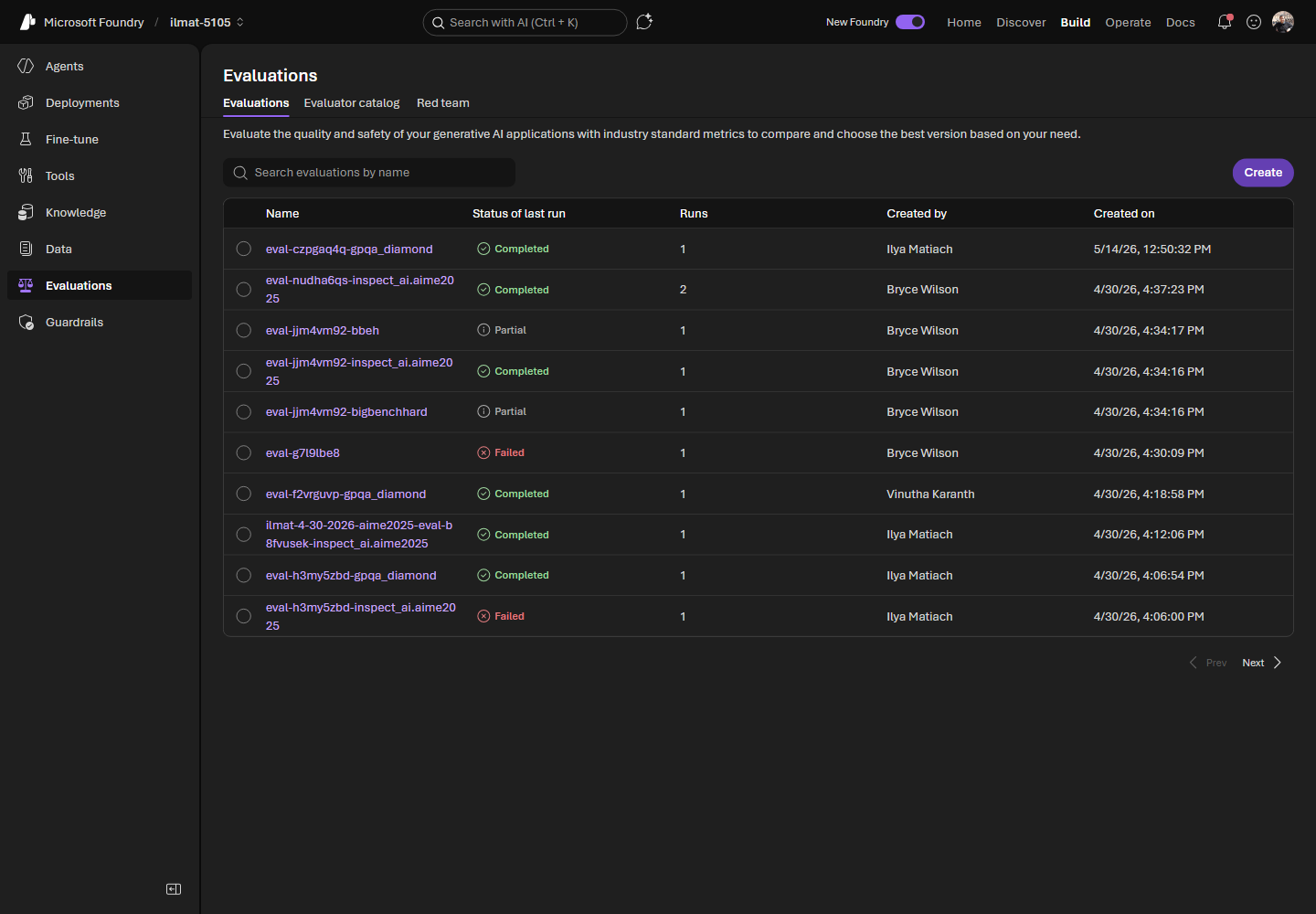
Figura 1. Benchmarks aparecem na lista de Evaluations do Microsoft Foundry junto com suas avaliações personalizadas.
Como isso difere do model leaderboard?
O Microsoft Foundry já inclui um model leaderboard que exibe pontuações pré-computadas de benchmarks no catálogo de modelos. O leaderboard responde: “Como esses modelos se saem em geral?”
Os benchmarks respondem a uma pergunta diferente: “Como meu deployment ou meu agente, com meu judge model e minha configuração, se sai agora?” Essa distinção é importante quando você está comparando dois deployments do mesmo modelo, validando um fine-tune, verificando se um agente regrediu após uma mudança de ferramenta ou reexecutando um benchmark após um upgrade de versão do modelo.
Para o contexto brasileiro, onde muitas vezes times de IA precisam justificar custos de inferência — especialmente ao usar modelos de fronteira — essa medição granular é o que separa uma decisão baseada em dados de um palpite.
O que um benchmark contém?
Um benchmark é um pacote de avaliação predefinido. Em vez de pedir que você faça upload de dados e defina critérios de scoring, o benchmark já fornece:
- Benchmark dataset — um dataset curado e de tamanho fixo com prompts e respostas esperadas.
- Task category — a capacidade sendo medida (reasoning, math, science, truthfulness, …).
- Evaluation logic — um evaluator embutido como
builtin.regex_match, ou um scorer específico do benchmark. - Optional judge model — para benchmarks que usam julgamento baseado em modelo (ex.: FrontierScience), você também escolhe um deployment para atuar como grader. A maioria dos benchmarks baseados em regex ou scorer (como GPQA Diamond, BBH, MuSR, BBEH e TruthfulQA) não precisa de Judge model.
O resultado de cada execução é tipicamente uma pontuação: uma porcentagem mais uma contagem de pass, como 82% com 645 / 790 exemplos passando na métrica do benchmark.
Target vs. judge model
O target é o que você está avaliando — um deployment de modelo ou um agente. O judge model é um deployment separado que o serviço de avaliação usa para pontuar outputs quando um benchmark requer julgamento baseado em modelo. A pontuação do judge model não representa sua própria qualidade; faz parte do pipeline de scoring. Mantenha o judge model consistente entre execuções que você deseja comparar, da mesma forma que manteria um instrumento de medição fixo em um experimento científico.
Benchmarks disponíveis na preview
O conjunto inicial cobre raciocínio, matemática, ciência e veracidade, com contagens de exemplos que variam de pequenos benchmarks smoke-test (AIME 2025, 30 exemplos) a suítes maiores (BBEH, 4.520 exemplos).
| Benchmark | Task | Examples | Evaluation logic |
|---|---|---|---|
| AIME 2025 Benchmark | reasoning, quality, math | 30 | AIME 2025 |
| BBEH Benchmark | reasoning, quality | 4.520 | builtin.bbeh |
| BIG-Bench Hard Benchmark | reasoning, quality | 934 | builtin.regex_match |
| ChemBench Benchmark | reasoning, quality, sciences | 2.785 | ChemBench |
| FrontierScience Benchmark | reasoning, quality | 160 | FrontierScience |
| GPQA Diamond Benchmark | reasoning, quality | 198 | builtin.regex_match |
| MuSR Benchmark | reasoning, quality | 756 | builtin.regex_match |
| TruthfulQA Benchmark | truthfulness, quality, reasoning | 790 | TruthfulQA |
Para equipes brasileiras, benchmarks como GPQA Diamond (198 exemplos) ou AIME 2025 (30) são ideais para começar — rápidos de executar e com resultados interpretáveis.
Cenários comuns de uso
Comparando deployments de modelo
Suponha que você esteja decidindo entre dois deployments — talvez duas versões da mesma família de modelo, ou um modelo de fronteira versus um menor e mais barato. Com benchmarks, você cria um único evaluation group (por exemplo, GPQA Diamond) e adiciona uma execução por target. A visualização do grupo mostra a pontuação e o consumo de tokens lado a lado, permitindo pesar qualidade contra custo no mesmo lugar.
Esse mesmo padrão captura regressões após um upgrade de versão ou fine-tune: reexecute o benchmark estabelecido, olhe a visualização do grupo e o delta mostra se as coisas melhoraram.
Avaliando um agente
Agentes introduzem variabilidade que avaliações puras de modelo não capturam: prompts, ferramentas, lógica de orquestração e dados conectados influenciam os outputs. Apontar benchmarks para um agente fornece um sinal reprodutível e agnóstico de modelo que complementa os evaluators específicos de agente que você já pode estar usando (intent resolution, task adherence, tool-call accuracy).
Um padrão prático: escolha um benchmark pesado em raciocínio como GPQA Diamond ou MuSR, aponte para seu agente (e, se relevante, uma ou duas versões) e execute sempre que mudar o modelo subjacente, o system prompt ou o tool set. O score do benchmark se torna uma régua estável através de mudanças que de outra forma seriam difíceis de comparar. Na página de detalhes de um agente no Microsoft Foundry, a aba Evaluation abre o mesmo wizard com escopo para aquele agente.
Executando um benchmark no portal
No Build experience do seu projeto Foundry, abra Evaluations e escolha Create. O wizard passa por três etapas curtas:
- Target — escolha Model ou Agent, depois selecione um ou mais deployments ou versões de agente.
- Data — escolha Benchmarks como fonte de dataset, selecione os benchmarks desejados e selecione um Judge model se o benchmark exigir.
- Review — confirme targets, datasets e evaluators, depois submit.
Como o benchmark possui seu próprio dataset, prompts e evaluator, o wizard pula o upload de dataset, configuração de prompt e a maior parte da configuração de evaluator que avaliações personalizadas exigem.
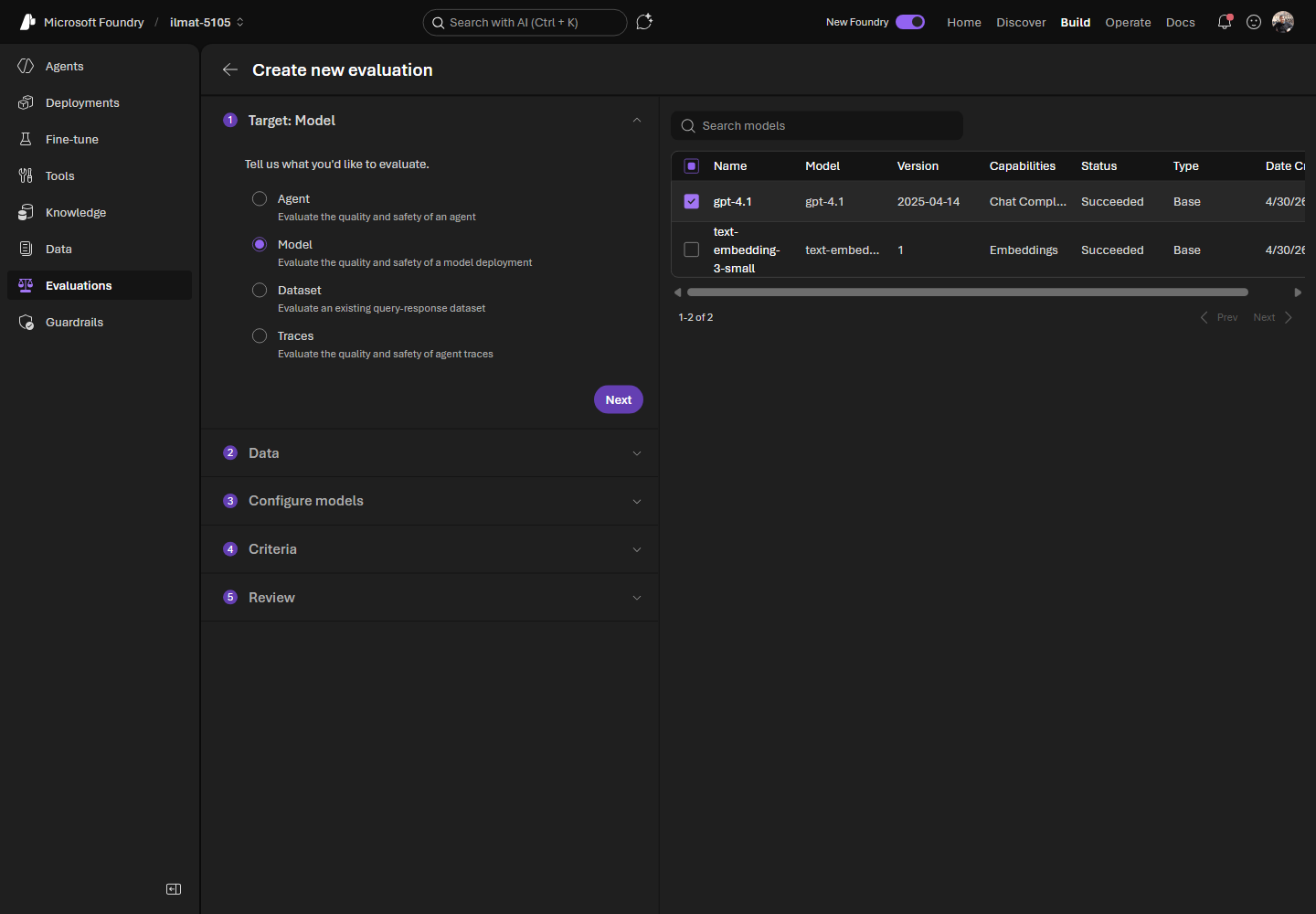
Figura 2. Comece selecionando um ou mais deployments de modelo (ou um agente) como target da avaliação.
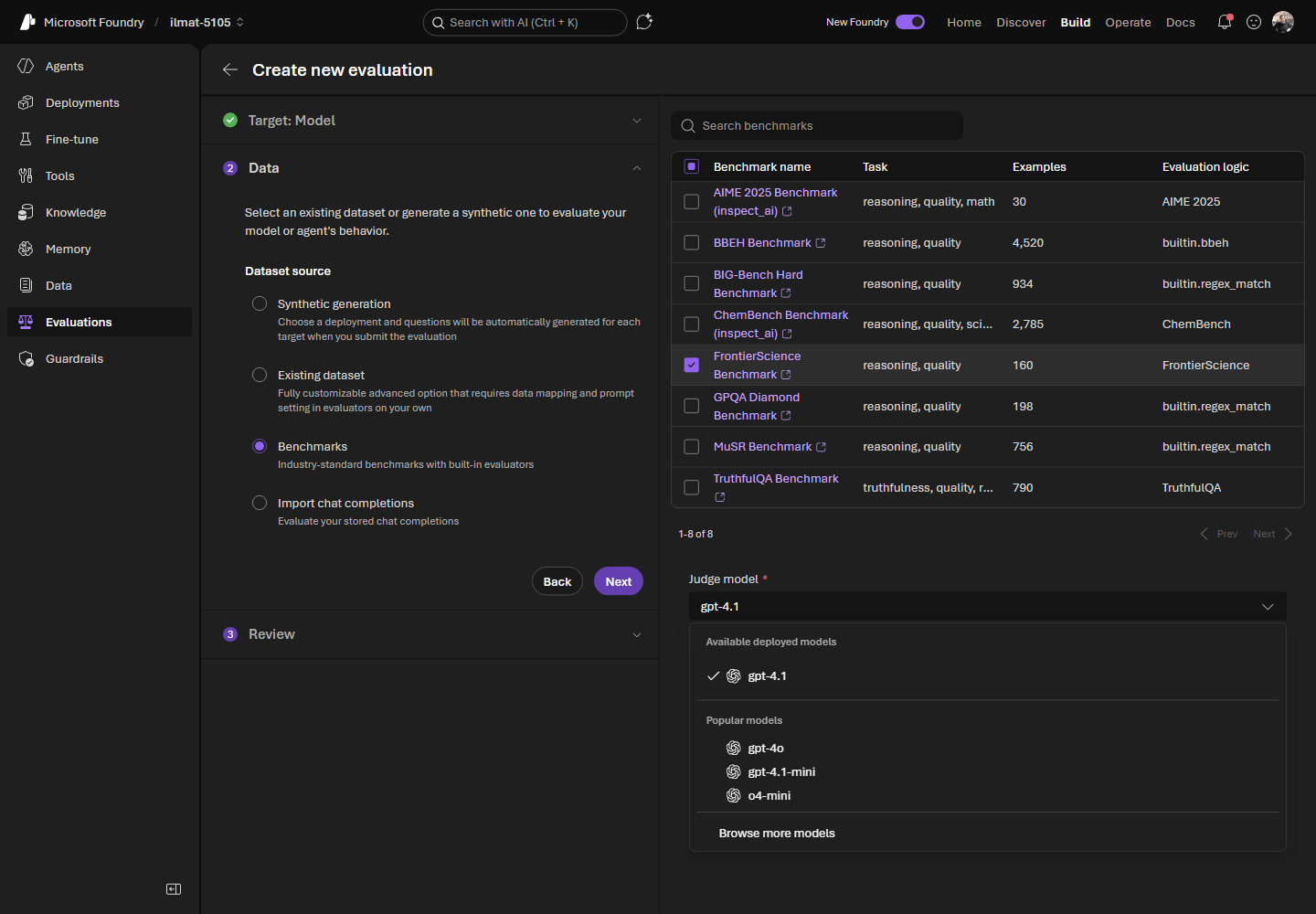
Figura 3. Na etapa Data, escolha Benchmarks e selecione um ou mais do catálogo. Ao selecionar um benchmark que usa julgamento baseado em modelo (aqui, FrontierScience), aparece um dropdown para escolher o deployment que atuará como grader.
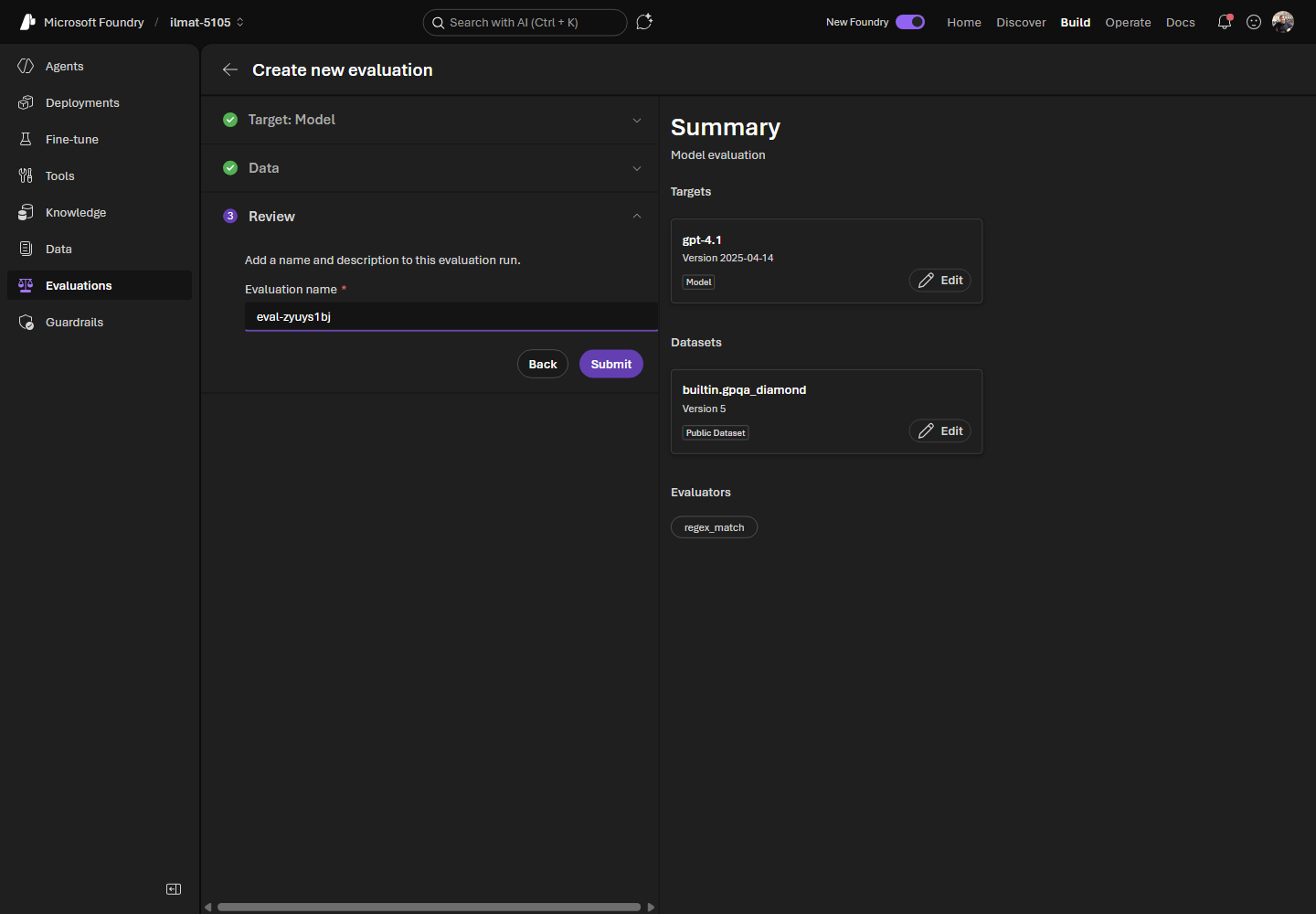
Figura 4. A etapa Review resume targets, datasets de benchmark e evaluators antes da submissão.
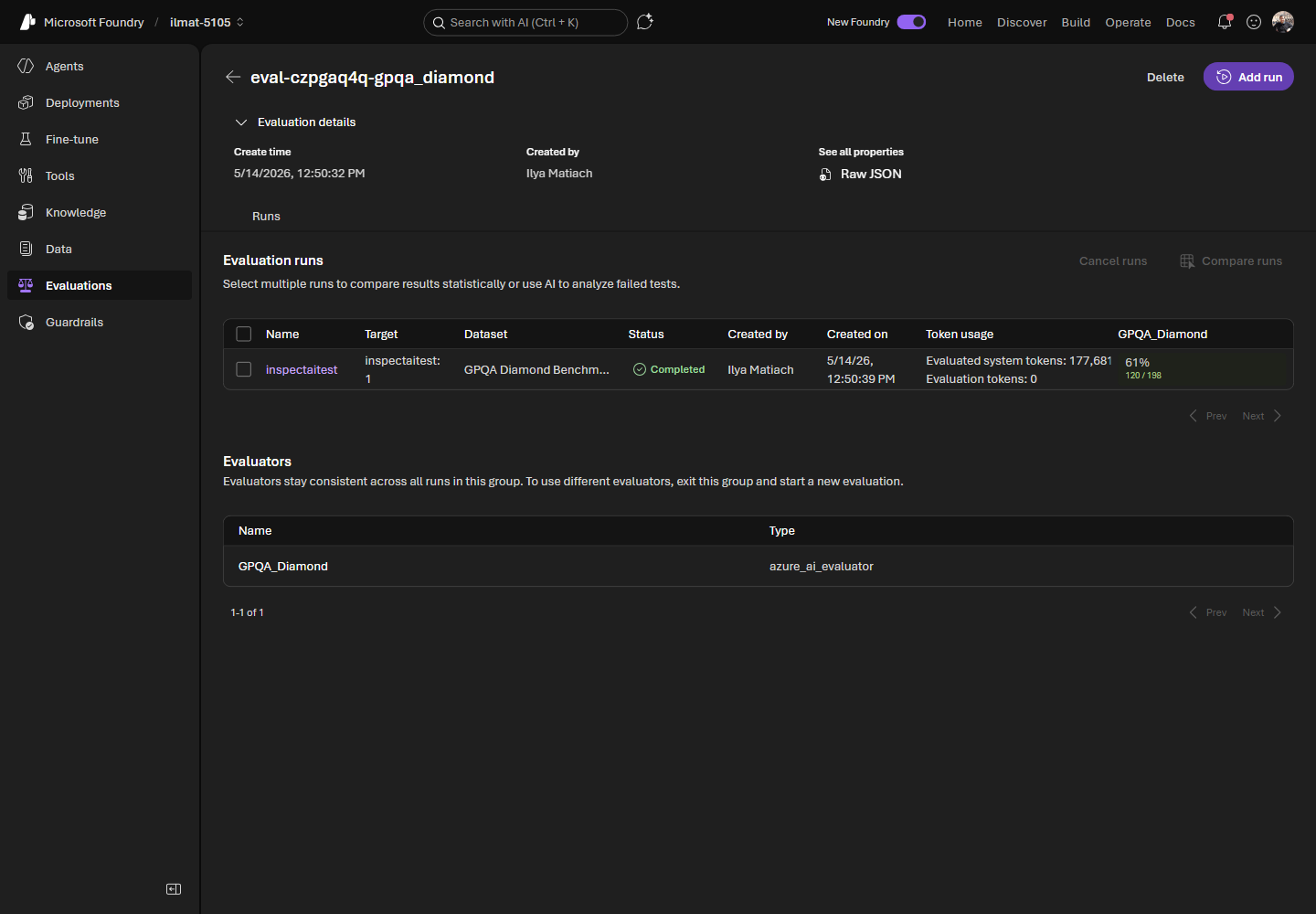
Figura 5. Um evaluation group concluído mostra status, consumo de tokens e score do benchmark de cada execução.
Interpretando os resultados dos benchmarks
Os resultados aparecem em dois níveis. A página do evaluation group lista cada execução com target, dataset, status, token usage e score — conveniente para comparações lado a lado. Abra uma execução individual para status, Raw JSON, Download results, Download user logs e o breakdown geral das métricas incluindo token usage e score.
Um score pode ser expresso como porcentagem (ex.: 82%) e como contagem pass/total (ex.: 645 / 790). Quando métricas detalhadas por exemplo não estão disponíveis, o resultado geral ainda é exibido, e Download results fornece o output linha a linha para análise mais profunda.
Token usage é reportado como métrica de primeira classe. Benchmarks podem executar centenas ou milhares de exemplos, e o julgamento baseado em modelo multiplica o custo de tokens — portanto, fique de olho nessa coluna ao escalar.
Automatizando benchmarks com a REST API (preview)
Tudo o que está no portal também está disponível através da Foundry evaluations REST API. Você cria um evaluation group que fixa o benchmark (e judge model, quando necessário), depois adiciona uma execução por target que deseja avaliar. O exemplo abaixo mostra a forma de uma requisição de criação de grupo; a referência completa — autenticação, variante com judge model, adição de execuções, respostas de erro, limitações e troubleshooting — está no Microsoft Learn.
POST {project-endpoint}/openai/evals?api-version=2025-11-15-preview
Authorization: Bearer {token}
Content-Type: application/json
{
"name": "truthfulqa-benchmark-eval-group",
"display_name": "TruthfulQA Benchmark",
"data_source_config": {
"type": "azure_ai_source",
"scenario": "benchmark_preview",
"benchmark_name": "builtin.truthful_qa",
"benchmark_version": "3"
}
}
Cada evaluation group precisa de pelo menos uma execução — é a execução que realmente avalia o target contra o benchmark do grupo. Adicione uma execução por target que deseja comparar.
POST {project-endpoint}/openai/evals/{evaluation-id}/runs?api-version=2025-11-15-preview
Authorization: Bearer {token}
Content-Type: application/json
{
"name": "truthfulqa-run-target-a",
"display_name": "TruthfulQA - {target-deployment-a}",
"data_source": {
"type": "azure_ai_benchmark_preview",
"target": {
"type": "azure_ai_model",
"model": "{connection-name}/{target-deployment-a}"
}
}
}
Veja o how-to no Microsoft Learn para a referência completa: https://learn.microsoft.com/en-us/azure/foundry/observability/how-to/benchmark-evaluations
Melhores práticas
- Comece com um ou dois benchmarks para validar sua configuração antes de escalar para suítes maiores.
- Fixe um judge model estável e uma benchmark_version estável ao comparar execuções ao longo do tempo.
- Fique de olho no token usage. Benchmarks grandes e judge models baseados em modelo acumulam; faça um preflight com uma única execução antes de lançar um batch.
- Baixe os resultados para análise de falhas quando um score agregado não conta toda a história.
- Trate recursos em preview como preview. Fixe api-version, valide identificadores de benchmark e revise release notes antes de depender da API em produção.
Considerações finais
Aplicativos de IA confiáveis dependem de medição confiável. À medida que modelos, prompts, datasets de fine-tuning e agentes continuam evoluindo, os times que se moverem mais rápido serão aqueles que conseguem responder rápida e credivelmente: “essa mudança melhorou as coisas?”
Os benchmarks do Microsoft Foundry trazem medição padronizada para o mesmo lugar onde você constrói, implanta e observa seus sistemas de IA — através de um fluxo simplificado no portal e uma REST API programável. Para testar, abra seu projeto Foundry, vá em Build > Evaluations, escolha Create e selecione um benchmark pequeno como AIME 2025 (30 exemplos) ou GPQA Diamond (198) contra um deployment de modelo ou agente. Depois de ter uma baseline, adicione suítes maiores e targets adicionais, e deixe que benchmarks padronizados se tornem parte de como sua equipe entrega IA.
Perguntas Frequentes
-
Qual a diferença entre os benchmarks do Foundry e o model leaderboard?
O leaderboard mostra pontuações pré-computadas gerais dos modelos no catálogo. Já os benchmarks medem o desempenho do seu deployment específico, com seu judge model e configuração, respondendo 'como meu deployment se comporta agora?' — essencial para comparar versões, validar fine-tunes ou detectar regressões. -
Preciso configurar um judge model para todos os benchmarks?
Não. Apenas benchmarks que usam julgamento baseado em modelo (como FrontierScience) exigem um judge model. A maioria (GPQA Diamond, BBH, MuSR, BBEH, TruthfulQA) usa evaluators baseados em regex ou scorers próprios e não precisam de judge model. -
Posso usar benchmarks para avaliar agentes, não apenas modelos puros?
Sim. Agentes introduzem variabilidade de prompts, ferramentas e lógica de orquestração. Aplicar benchmarks a agentes fornece um sinal reprodutível e agnóstico de modelo, complementando evaluators específicos de agente. Recomenda-se usar benchmarks como GPQA Diamond ou MuSR e reexecutar após mudanças no modelo, prompt ou tool set. -
Quais benchmarks estão disponíveis na preview?
O conjunto inicial cobre raciocínio, matemática, ciência e veracidade. Inclui AIME 2025 (30 exemplos), GPQA Diamond (198), MuSR (756), TruthfulQA (790), ChemBench (2.785), BIG-Bench Hard (934), BBEH (4.520) e FrontierScience (160). A tabela completa está no artigo. -
Como automatizar a execução de benchmarks usando a API REST?
Você pode criar um evaluation group via POST para o endpoint/openai/evals, especificando o benchmark e, se necessário, o judge model. Depois, adicione runs para cada target. Tudo documentado no Microsoft Learn. A API permite integrar benchmarks no pipeline de CI/CD.
Artigo originalmente publicado por imatiach em Azure Updates - Latest from Azure Charts.
