

Ray Serve LLM no GKE: 5x mais throughput e 8x menos latência sem perder a experiência do desenvolvedor
TL;DR — Este artigo analisa as três otimizações arquiteturais que tornaram o Ray Serve LLM no GKE até 5x mais rápido em throughput e 8x mais eficiente em latência: integração com HAProxy, streaming direto de tokens e novo backend v2 para vLLM. Para empresas brasileiras que rodam modelos de linguagem em produção, isso significa performance comparável ao vLLM nativo sem perder a flexibilidade do ecossistema Ray — ideal para workloads que exigem escalabilidade e baixa latência sem complexidade operacional extra.
Desenvolvedores que buscam inferência de LLM e serving de modelos frequentemente recorrem ao Ray Serve, uma biblioteca escalável de model serving com APIs Python nativas e foco em produtividade, construída pela Anyscale. Quando combinado com o Google Kubernetes Engine (GKE), as equipes ganham uma plataforma unificada e otimizada para casos de uso exigentes de serving de LLMs — desde o desenvolvimento inicial do modelo até a produção online.
No entanto, essa flexibilidade e conjunto de recursos costumavam ter um custo em performance. Mas hoje, em parceria com a Anyscale, estamos entregando até 5x mais throughput e 8x menos latência no Ray Serve, atendendo às demandas crescentes e aos rigorosos requisitos de performance de inferência distribuída de ponta — sem sacrificar a facilidade de uso.
Escalando inferência sem gargalos?
Por meio de uma engenharia conjunta, três otimizações arquiteturais foram introduzidas para transformar a performance do Ray Serve LLM:
-
Integração Ray Serve com HAProxy: o Ray Serve agora incorpora o HAProxy para gerenciar roteamento interno de requisições e load balancing. Essa configuração reduz drasticamente a sobrecarga do proxy e impede que o runtime Python sature sob tráfego intenso.
-
Arquitetura de streaming direto de tokens: essa arquitetura desacopla o caminho inicial da requisição do fluxo de retorno. Os tokens fluem diretamente das réplicas do modelo para o proxy, ignorando completamente o ingress router no caminho de streaming, reduzindo a latência.
-
Backend v2 do Ray executor para vLLM: o backend reformulado para vLLM move o Ray para fora do data plane, permitindo scheduling assíncrono. Isso unifica o caminho de código com os executores nativos do vLLM, fechando a lacuna de performance e garantindo que usuários do Ray se beneficiem das otimizações mais recentes do motor.
Benchmarking de performance no GKE: o que os números mostram?
Em parceria com a Anyscale, a equipe também realizou benchmarks do Ray Serve LLM atualizado em clusters GKE com hardware de IA de última geração — incluindo VMs A4 do Google Cloud equipadas com sistemas NVIDIA HGX B200. O modelo escolhido foi o Gemma 4 E2B, um modelo pequeno e eficiente, ideal para isolar gargalos introduzidos por orquestração e roteamento. Os benchmarks compararam o novo Ray Serve LLM com sua performance anterior e com uma configuração de vLLM puro usando o executor Ray.
Essas melhorias técnicas geram um impacto transformador: até 5x mais throughput e 8x melhor latência em comparação com configurações anteriores do Ray Serve.
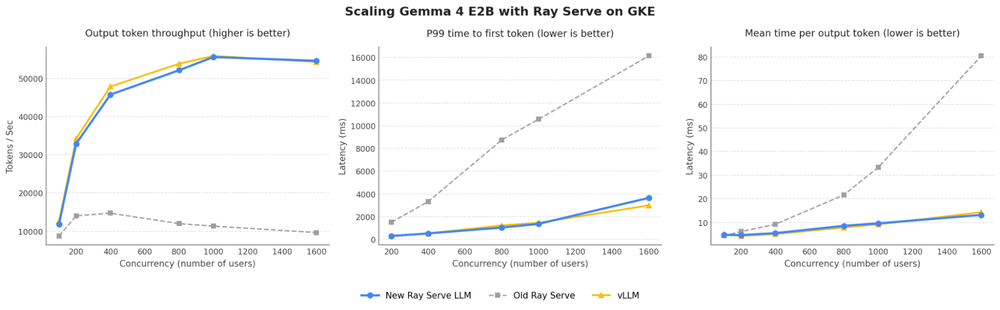
O Ray Serve LLM melhorado mostrou uma evolução notável em um cluster de serving com oito réplicas, exibindo um padrão de escalabilidade que supera amplamente a performance anterior e se aproxima da performance do vLLM nativo — mas sem abrir mão da flexibilidade que o Ray oferece.
Por que escolher o GKE para Ray Serve?
O GKE fornece a infraestrutura fundamental que faz essas otimizações de software brilharem. Ao usar o Ray Operator add-on para GKE, você obtém deployment turnkey nos aceleradores de IA do Google Cloud, incluindo escalabilidade horizontal automatizada, monitoramento, escalabilidade multi-cluster e tolerância a falhas embutida. O GKE abstrai as partes complexas da orquestração de hardware físico distribuído — sua equipe pode se concentrar em refinar modelos e lógica de aplicação com Ray.
Teste o Ray Serve LLM no GKE
Incentivamos desenvolvedores a experimentar essas melhorias na versão mais recente do Ray (2.56 em diante) e vivenciar o futuro do serving de LLMs de alta performance no GKE.
Para mais detalhes, consulte os recursos abaixo:
- New from Anyscale: High Performance Distributed Inference with Ray Serve LLM
- Enable High Throughput on Ray Serve with KubeRay
- Serve an LLM with multi-cluster Ray Serve and GKE Inference Gateway
- Serve Gemma open models on GKE with Ray
Perguntas Frequentes
Quais as três principais otimizações introduzidas no Ray Serve LLM?
Foram implementadas: (1) integração com HAProxy para roteamento e load balancing interno; (2) arquitetura de streaming direto de tokens, que desacopla o caminho de requisição do retorno; (3) backend v2 para vLLM, que move o Ray para fora do data plane e unifica o código com executores nativos do vLLM.
Essas melhorias funcionam apenas no GKE ou podem ser usadas em outros clusters Kubernetes?
As otimizações são nativas do Ray Serve LLM (versão 2.56+), portanto podem ser usadas em qualquer cluster Kubernetes. No entanto, o GKE oferece um add-on Ray Operator que facilita o deployment, escalabilidade horizontal, monitoramento e tolerância a falhas, potencializando os ganhos.
Como o desempenho se compara ao vLLM puro?
Segundo os benchmarks com o modelo Gemma 4 E2B em oito réplicas, o Ray Serve LLM otimizado atinge desempenho comparável ao vLLM nativo - mas com a vantagem de manter a flexibilidade e o ecossistema de ferramentas que o Ray oferece para desenvolvimento e operação.
Quais acelaradores de hardware foram usados nos testes?
Os benchmarks foram executados em clusters GKE com VMs A4 equipadas com sistemas NVIDIA HGX B200, usando o modelo Gemma 4 E2B para isolar gargalos de orquestração e roteamento.
Posso testar essas melhorias hoje?
Sim. As otimizações estão disponíveis a partir do Ray release 2.56. A documentação oficial inclui guias para habilitar alta throughput com KubeRay, servir LLMs com multi-cluster Ray e GKE Inference Gateway, e deploy de modelos Gemma no GKE com Ray.
Artigo originalmente publicado por Seiji Eicher, Software Engineer, Anyscale em Cloud Blog.
