

TL;DR: O Google Cloud anunciou melhorias significativas para o Managed Service for Apache Spark (antigo Dataproc), com destaque para o Lightning Engine (até 4,9x mais rápido), Flexíveis VMs para maior disponibilidade, clusters zero-scale e paradas programadas para redução de custos, e integrações com IA (MCP Server e Data Agent Kit). Para empresas brasileiras, essas funcionalidades representam ganhos diretos de performance, eficiência operacional e controle de gastos em ambientes de dados e machine learning.
Na Google Cloud, o objetivo é permitir que você execute workloads analíticas e de data science em larga escala com máxima eficiência, processando pipelines de big data, machine learning e tarefas de ETL. Recentemente, o serviço Dataproc foi renomeado para Managed Service for Apache Spark, refletindo sua integração profunda com o Agentic Data Cloud.
Para atender às diversas necessidades arquiteturais dos times de dados modernos, o serviço é oferecido em dois modos de implantação: serverless (abstrai completamente a infraestrutura para jobs efêmeros ou ad-hoc) e clusters gerenciados (projetado para times que exigem customização fina de infraestrutura, ambientes persistentes, processamento stateful de longa duração ou integração nativa com configurações de hardware personalizadas do Compute Engine).
Nos clusters gerenciados, a experiência foi repensada com foco em três pilares: tornar o Spark mais rápido (supercharging execution speeds), mais fácil de executar (maximizando a obtenção de recursos e reduzindo overhead operacional) e mais inteligente (incorporando IA diretamente no ciclo de vida de desenvolvimento e operação). Este artigo foca especificamente nos anúncios do Google Cloud Next ‘26 para o modo de clusters gerenciados.
Como o Lightning Engine acelera as cargas de trabalho Spark?
A maior novidade para clusters gerenciados é o Lightning Engine, que traz ganhos massivos de performance para APIs Spark DataFrame/Dataset e consultas pesadas de Spark SQL. Alimentado por um motor de execução nativo em C++ com vetorização SIMD (Single Instruction, Multiple Data), construído sobre Velox e Gluten, o Lightning Engine elimina gargalos de execução JVM ao compilar planos de consulta em instruções nativas.
Esse motor de execução nativa entrega:
- Até 4,9x mais performance que o Spark open-source padrão
- Até 2x a relação preço-performance em relação à principal alternativa de alta velocidade
Crucialmente, não é necessário alterar código das aplicações Spark existentes. Como os jobs completam mais rápido, você reduz diretamente as horas de runtime do Compute Engine e o custo total. Para habilitar o Lightning Engine, basta especificar a opção ao criar um cluster.

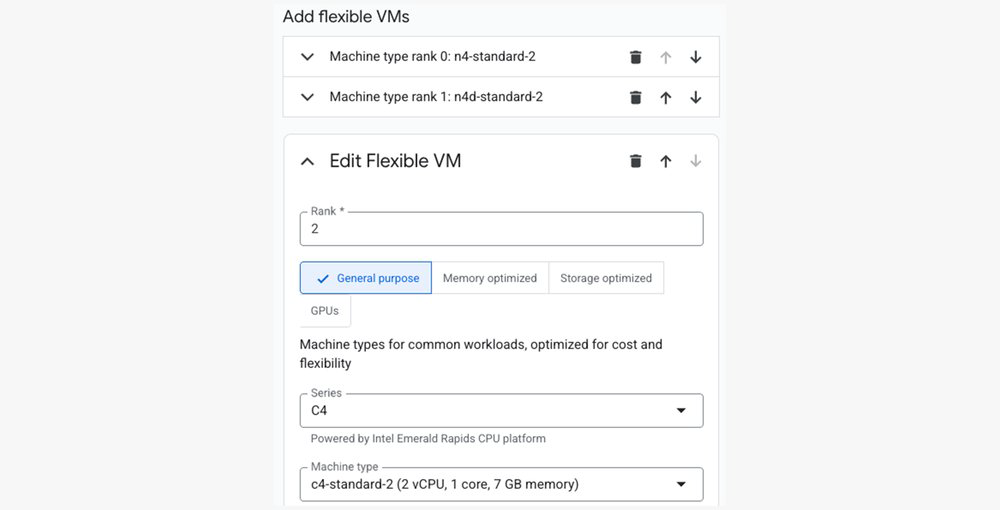
Como a flexibilidade de VMs melhora a disponibilidade de recursos?
Escassez temporária de um tipo específico de máquina pode travar a criação do cluster ou interromper o autoscaling. Para melhorar drasticamente a resiliência do cluster contra restrições de capacidade, as Flexible VMs para clusters gerenciados agora estão em disponibilidade geral.
Com as Flexible VMs, você pode definir até dez tipos de máquina ranqueados para seus nós master, primary e secondary workers. O Managed Service for Apache Spark combina essa preferência com a alocação automática de zona regional, escaneando dinamicamente toda a região para atender suas requisições de capacidade usando o melhor layout de hardware disponível. Isso ajuda a garantir que seus pipelines sejam inicializados de forma previsível, reduzindo drasticamente erros de disponibilidade de recursos e maximizando sua capacidade de capturar capacidade de Spot VM a custo reduzido durante períodos de pico de demanda.
Como os clusters zero-scale e paradas programadas reduzem custos?
Para dar mais controle fiscal sobre ambientes persistentes e de desenvolvimento, foram disponibilizadas duas funcionalidades muito requisitadas: clusters zero-scale e paradas programadas.
- Clusters zero-scale: Você pode provisionar ambientes que usam exclusivamente secondary workers (Spot VMs), permitindo que o cluster escale automaticamente para zero nós quando não há processamento ativo, mantendo apenas o nó master online para preservar metadados.
- Paradas programadas: Permite configurar políticas automatizadas de desligamento do cluster com base em limites específicos de idle time ou em um timestamp futuro preciso.
Como essas funcionalidades são integradas nativamente, reduzem o atrito operacional de ter que deletar e reconstruir o ambiente, enquanto você para de pagar por overhead de computação ociosa durante noites e finais de semana.
Como o MCP Server integra IA aos clusters Spark?
Para preencher a lacuna entre inteligência artificial generativa e engenharia de dados, foi lançado o Model Context Protocol (MCP) server para Managed Service for Apache Spark. Essa integração de padrão aberto permite que LLMs e assistentes de IA interajam de forma segura e dinâmica com seus clusters gerenciados usando linguagem natural.
Utilizando o MCP server, seus agentes de IA podem se conectar à sua plataforma de dados sob as permissões IAM existentes, realizando operações baseadas em cluster (criação, submissão de jobs, ajuste de autoscaling) diretamente da sua aplicação de IA.
Como o Data Agent Kit acelera o desenvolvimento de pipelines?
A extensão Google Cloud Data Agent Kit permite que cientistas, engenheiros e desenvolvedores gerenciem todo o ciclo de vida de workloads de dados diretamente em seu ambiente de desenvolvimento preferido. O suporte nativo foi adicionado aos clusters gerenciados, permitindo construir e implantar Data Agents especializados para geração de código e preparação de dados.

Os desenvolvedores podem usar o Antigravity 2.0 (plataforma de desenvolvimento agentic da Google) ou levar essas capacidades para IDEs como VS Code, Claude Code ou Codex, via extensões e plugins do Data Agent Kit. Ao combinar esse workflow simplificado com o poder de processamento dos clusters gerenciados, esses agentes inteligentes podem executar workflows complexos diretamente sobre data lakes de petabytes. Especificamente, o Data Agent Kit permite:
- Construir e orquestrar pipelines: Autorar pipelines de dados multi-nó e gerar documentação de código usando linguagem natural.
- Realizar debugging em tempo real: Usar o Gemini Cloud Assist para analisar logs de executor, identificar causas raiz de falhas e recomendar ações corretivas.
- Conectar-se facilmente a recursos Spark: Anexar-se a runtimes serverless ou clusters gerenciados sem configuração manual de rede ou instalação local de Spark.
- Gerenciar Git e CI/CD: Commitar, mergear e implantar código diretamente da IDE, acionando testes automatizados e pipelines de deploy.
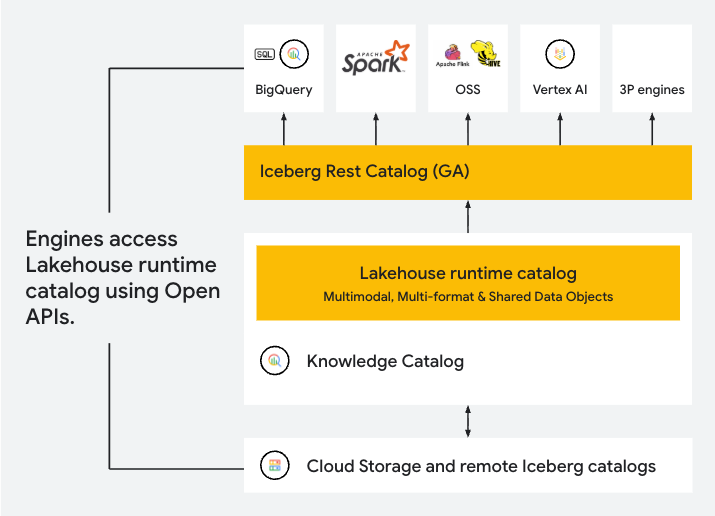
O que é o Lakehouse e como ele unifica dados?
Foi lançado também o Lakehouse, que oferece interoperabilidade de leitura/escrita entre motores como Managed Service for Apache Spark e BigQuery. Utilizando o catálogo runtime do Lakehouse como uma camada de metadados unificada e serverless, ele elimina silos de dados e a necessidade de camadas complexas de tradução.
Essa abordagem agentic-first permite que organizações processem formatos abertos diretamente do Google Cloud Storage ou até consultem datasets remotos na AWS usando o recém-lançado cross-cloud Lakehouse, tudo mantendo uma única fonte de verdade para segurança e governança.
Para clientes que utilizam clusters gerenciados, essa integração desbloqueia capacidades poderosas: times de dados podem acelerar suas workloads de ETL e data science mais exigentes em até 4,9x usando o Lightning Engine otimizado.
O que há de novo no Cluster Image 3.0 com Spark 4.1?
Acompanhando o ecossistema open-source, foi lançada em preview a Cluster Image 3.0, construída com Apache Spark 4.1 e Java 21 como runtime padrão. O Spark 4.1 introduz capacidades como modo real-time para structured streaming, permitindo que seu ambiente Spark suporte streaming contínuo com latência de sub-segundos.
Primeiros passos
Essas atualizações já estão disponíveis nos clusters gerenciados! Você pode habilitar as novas funcionalidades diretamente pelo console do Google Cloud ou via CLI gcloud.
Para criar um novo cluster gerenciado com Lightning Engine nativamente habilitado, execute:
gcloud dataproc clusters create my-optimized-cluster \
--region=us-central1 \
--image-version=2.3 \
--engine=lightning
Alternativamente, navegue até a página do Managed Service for Apache Spark no console, clique em "Create cluster" e selecione "Enable Lightning Engine" nas configurações do cluster.
Perguntas Frequentes
-
O Lightning Engine exige alterações no código Spark existente?
Não. O Lightning Engine é ativado por configuração do cluster (via console ou gcloud CLI) e não requer nenhuma mudança nas aplicações Spark existentes. Os ganhos de performance vêm da execução nativa C++ com vetorização SIMD, aplicada automaticamente. -
Como os clusters zero-scale ajudam a reduzir custos?
Com clusters zero-scale, é possível usar apenas workers secundários (Spot VMs) e escalar para zero nós quando não há processamento. Apenas o nó mestre permanece online para preservar metadados, eliminando custos com idle compute durante inatividade. -
O MCP Server substitui o gcloud ou o console?
Não. O MCP Server é um complemento que permite que LLMs e assistentes de IA interajam com os clusters Spark via linguagem natural, respeitando permissões IAM. Ele facilita operações como criação de clusters, submissão de jobs e ajuste de autoscaling diretamente de aplicações de IA. -
O que é o Data Agent Kit e como ele se integra ao Managed Spark?
O Data Agent Kit é uma extensão que permite a cientistas e engenheiros de dados gerenciar todo o ciclo de vida de workloads diretamente de IDEs como VS Code, Claude Code ou Codex. Com suporte nativo nos clusters gerenciados, possibilita criação de pipelines, debugging com Gemini e integração com Git/CI/CD. -
O Lakehouse substitui o BigQuery?
Não. O Lakehouse é uma camada de catálogo unificada que permite ler e escrever dados entre Managed Spark e BigQuery sem silos. Ele também suporta processamento de formatos abertos no Cloud Storage e consultas cross-cloud (AWS), mantendo governança e segurança centralizadas.
Artigo originalmente publicado por Qiqi Wu, Senior Product Manager, Google Cloud em Cloud Blog.
