

TL;DR: Este artigo explica a arquitetura de um knowledge pipeline baseado em Retrieval-Augmented Generation (RAG) que transforma dados de arquivos empresariais armazenados no Azure NetApp Files em um sistema de conhecimento ativamente consultável por IA. A solução usa OneLake para acesso zero-copy, Azure AI Search para indexação semântica e Azure OpenAI para embeddings e geração de respostas com citação de fontes. O resultado: nenhum movimento de dados, workflows inalterados e respostas rastreáveis. Ideal para empresas brasileiras que buscam adotar IA sem refatorar a infraestrutura de armazenamento.
Introdução
Na Parte 1 desta série, From Enterprise File Storage to an AI-Ready Data Foundation using Azure NetApp Files and OneLake, estabelecemos a base: como o Azure NetApp Files e o Microsoft OneLake transformam o armazenamento de arquivos empresariais em uma camada de dados endereçável por IA, sem migração, duplicação ou interrupção de workflows.
Mas uma base pronta para IA, por si só, não torna os dados utilizáveis por sistemas de IA.
⚠️ Importante
Pesquisas da indústria mostram que muitas iniciativas de IA falham antes mesmo de chegar à produção. De acordo com a IDC, menos da metade (44%) dos projetos-piloto de IA avançam além da fase experimental, e os principais fatores limitantes não são a capacidade dos modelos, mas a qualidade dos dados de negócio e a tempestividade do acesso a eles.
IDC, AI-Ready Data Storage Infrastructure: Definition, Taxonomy, Ontology, and Future Outlook, IDC #US53709325, August 2025
Para transformar dados de arquivos empresariais em algo que grandes modelos de linguagem possam raciocinar, pesquisar e citar, precisamos de um knowledge pipeline — um pipeline que entenda conteúdo não estruturado em escala, recupere a informação certa no momento certo e ancore as respostas da IA em dados autoritativos.
É aqui que entra a Retrieval-Augmented Generation (RAG) na arquitetura.
Co-autores: Thomas Willingham, Azure NetApp Files Product Manager; Sean Luce, Azure NetApp Files Product Manager
Por que um knowledge pipeline é necessário?
Grandes modelos de linguagem (LLMs) são poderosos, mas têm uma limitação fundamental em ambientes empresariais: eles não têm acesso inerente aos dados internos da sua organização.
Mesmo quando os dados estão acessíveis por meio de uma fundação unificada como o OneLake, esses modelos não conseguem simplesmente “ler” arquivos sob demanda. Sistemas de IA empresariais exigem um mecanismo para:
- Descobrir conteúdo relevante em grandes conjuntos de documentos;
- Compreender o significado semântico de arquivos não estruturados;
- Recuperar apenas os trechos mais relevantes para uma determinada pergunta;
- Gerar respostas ancoradas em documentos reais, com rastreabilidade.
É exatamente isso que um knowledge pipeline oferece.
Em vez de empurrar todos os dados empresariais para dentro de um modelo, o pipeline mantém os dados no lugar, constrói um índice semântico continuamente atualizado e recupera informações relevantes no momento da consulta. O modelo de IA então gera respostas apenas com base no conteúdo recuperado, não em suposições ou dados genéricos de treinamento.
Como funciona a Retrieval-Augmented Generation (RAG) em escala empresarial?
Em alto nível, a RAG combina duas funções:
- Retrieval – encontrar os pedaços mais relevantes de conteúdo empresarial
- Generation – usar um modelo de linguagem para sintetizar uma resposta a partir dessas fontes recuperadas
Para dados de arquivos empresariais, esse padrão é especialmente importante:
- Repositórios de arquivos são grandes, dinâmicos e mudam constantemente;
- O conteúdo não é estruturado e varia muito em formato e qualidade;
- Precisão, rastreabilidade e conformidade são obrigatórias, não opcionais.
A RAG garante que as respostas da IA estejam ancoradas em conteúdo empresarial atual e autorizado, e não em conhecimento inferido, desatualizado ou alucinado.
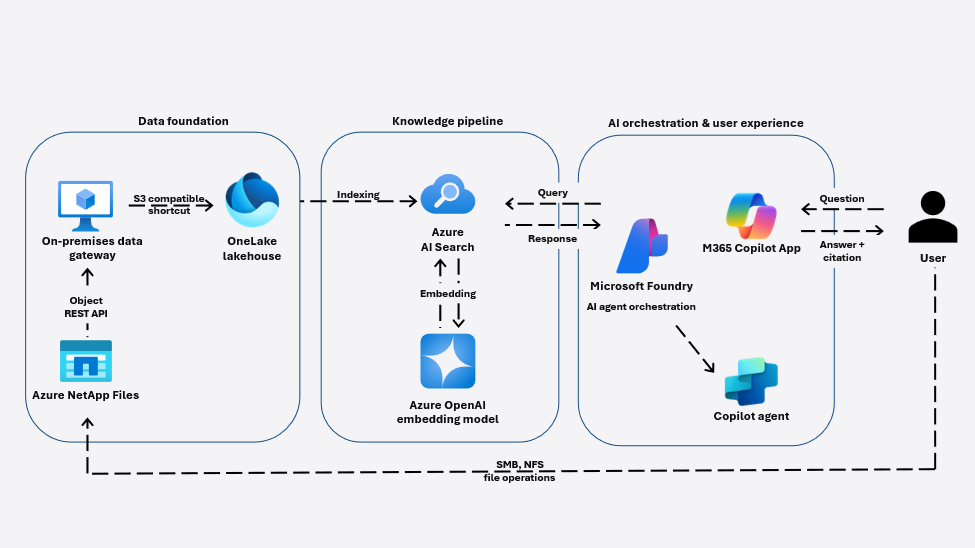
Qual é a arquitetura do knowledge pipeline?
Nesta solução, o knowledge pipeline fica sobre a fundação de dados do OneLake e conecta dados de arquivos empresariais a experiências de IA downstream por meio de três serviços principais:
| Componente | Função no Knowledge Pipeline |
|---|---|
| Microsoft OneLake | Fornece acesso unificado e zero-copy aos dados de arquivos empresariais |
| Azure AI Search | Indexa, faz chunking e recupera conteúdo relevante usando busca por palavras-chave + vetorial |
| Azure OpenAI | Gera embeddings semânticos e sintetiza respostas ancoradas |
Juntos, esses serviços transformam dados de arquivos passivos em um sistema de conhecimento empresarial ativamente consultável.
Passo 1: Indexar conteúdo empresarial sem movê-lo
O pipeline começa com o Azure AI Search indexando o conteúdo exposto pelo OneLake.
Como o OneLake referencia volumes do Azure NetApp Files por meio de shortcuts, o Azure AI Search pode ler os arquivos diretamente, sem copiá-los para outro sistema de armazenamento. Os arquivos permanecem:
- Armazenados no Azure NetApp Files;
- Disponíveis in-place via workflows SMB / NFS existentes;
- Governados pelo modelo de segurança e propriedade original.
Durante a indexação, o Azure AI Search realiza três funções principais:
- Extração de conteúdo – leitura de texto de formatos de documentos suportados;
- Chunking – divisão de documentos grandes em segmentos semanticamente significativos;
- Captura de metadados – preservação de nomes de arquivos e informações contextuais.
Esse processo cria uma representação pesquisável do conteúdo dos arquivos empresariais, deixando os dados originais intocados. Conforme os arquivos mudam, esse índice é atualizado por meio de processos de re-indexação que regeneram embeddings para o conteúdo modificado.
Passo 2: Criar significado semântico com embeddings
A busca por palavras-chave sozinha é insuficiente para consultas em linguagem natural.
Para compreender o significado, e não apenas palavras coincidentes, o pipeline usa vector embeddings gerados pelo Azure OpenAI.
Durante a indexação:
- Cada chunk de documento é convertido em um vetor de alta dimensão que representa seu significado semântico;
- Esses embeddings são armazenados no Azure AI Search junto com o índice textual.
Isso permite a busca por similaridade semântica, onde o sistema recupera conteúdo relevante mesmo quando a pergunta do usuário não corresponde exatamente às palavras do documento.
Por exemplo:
- Uma consulta sobre “procedimentos de resposta a incidentes” pode recuperar documentos intitulados “Security Escalation Playbook”.
- A intenção da política importa mais do que a redação literal.
Isso é crítico para cenários de IA em linguagem natural, onde os usuários fazem perguntas de forma conversacional, em vez de pesquisar por nome de arquivo ou palavra-chave.
Passo 3: Recuperação no momento da consulta
Quando um usuário envia uma pergunta — por exemplo, por meio de um AI agent — o knowledge pipeline é ativado em tempo real.
No momento da consulta:
- A pergunta é convertida em um embedding;
- O Azure AI Search executa uma busca por similaridade vetorial contra o conteúdo indexado;
- Os chunks de documento mais relevantes são recuperados;
- Os metadados da fonte (incluindo nomes de arquivos) são preservados.
Apenas o conteúdo recuperado é passado para o modelo de linguagem para geração da resposta.
Exemplo: Como a recuperação funciona na prática
Um usuário pergunta: “Qual é o nosso procedimento de escalonamento de incidentes para violações de dados?”
O sistema recupera seções relevantes de documentos como um “Security Escalation Playbook” armazenado no Azure NetApp Files e passa apenas esses trechos para o modelo de linguagem gerar uma resposta ancorada, com citações das fontes incluídas.
Esse design garante:
- As respostas da IA são baseadas em documentos empresariais reais;
- O escopo da informação é rigidamente controlado;
- Os resultados permanecem explicáveis e auditáveis.
Passo 4: Geração de respostas ancoradas
Finalmente, o Azure OpenAI sintetiza uma resposta em linguagem natural usando apenas o conteúdo recuperado.
O modelo não infere além das fontes fornecidas. Em vez disso, ele:
- Resume informações relevantes;
- Resolve ambiguidades entre múltiplos documentos;
- Produz uma resposta ancorada em dados empresariais.
Como os nomes dos arquivos são preservados em todo o pipeline, as interfaces downstream — como um AI agent — podem exigir que as respostas incluam citações explícitas das fontes.
Isso é especialmente importante em ambientes regulados e orientados por compliance, onde os usuários precisam verificar de onde veio a resposta.
Por que essa arquitetura é importante?
O knowledge pipeline resolve um problema que integrações genéricas de IA não conseguem:
- Sem movimentação de dados – os arquivos permanecem no Azure NetApp Files;
- Sem re-plataforma – os workflows existentes continuam inalterados;
- Sem lacuna de confiança – toda resposta pode ser rastreada até um documento real.
Em vez de forçar as empresas a reestruturar seus dados para se adaptarem às ferramentas de IA, essa arquitetura adapta a IA à forma como as empresas já armazenam e gerenciam conhecimento.
O resultado é um sistema de conhecimento vivo:
- Atualizado à medida que o conteúdo muda, por meio de processos de re-indexação que refrescam o índice semântico;
- Escalável para milhões de documentos;
- Pronto para suportar múltiplas experiências de IA, não apenas um cenário único voltado ao usuário.
Preparando-se para a experiência Copilot
Neste ponto, o pipeline já fez o trabalho pesado:
- Os dados de arquivos empresariais estão acessíveis pelo OneLake;
- Indexados semanticamente e pesquisáveis;
- Prontos para acesso controlado e ancorado por IA.
O que resta é expor essa capacidade aos usuários finais — de forma segura, consistente e dentro das ferramentas que eles já usam.
Este knowledge pipeline fornece a base governada e pronta para retrieval que os agents de IA empresariais podem consumir e orquestrar, antes de serem apresentados aos usuários finais por meio de experiências downstream.
Principal conclusão
Os dados de arquivos empresariais se tornam um sistema de conhecimento vivo e consultável, sem mover, copiar ou reestruturar um único arquivo, eliminando o “copy-tax” operacional associado à duplicação de dados.
Ao combinar Microsoft OneLake, Azure AI Search e Azure OpenAI, o knowledge pipeline transforma a base de dados zero-copy em um recurso empresarial ativamente pesquisável. Cada resposta da IA é ancorada em documentos reais, rastreável até sua fonte e limitada a conteúdo autorizado.
Com o knowledge pipeline pronto, o próximo passo é expor essa capacidade aos usuários finais de forma segura e intuitiva.
Na Parte 3, Bringing Enterprise File Data to Users with Microsoft Foundry, M365 Copilot and Azure NetApp Files, exploraremos como esse pipeline é exposto por meio de agents de IA empresariais e experiências de usuário, governado pelo Microsoft Foundry, permitindo interação em linguagem natural com dados de arquivos empresariais, com citações, governança e controles empresariais.
Perguntas Frequentes
-
Preciso mover meus arquivos do Azure NetApp Files para outro lugar para usar IA?
Não. A arquitetura mantém os arquivos no Azure NetApp Files. O OneLake cria shortcuts que referenciam os volumes, e o Azure AI Search indexa o conteúdo diretamente, sem copiar dados. Os arquivos continuam acessíveis via SMB/NFS com segurança e governança originais. -
Como o pipeline lida com documentos que mudam frequentemente?
O índice semântico é atualizado por re-indexação periódica. Quando arquivos são modificados, o processo regenera os embeddings dos chunks afetados, mantendo o sistema de conhecimento sempre sincronizado com o conteúdo mais recente. -
Esse pipeline funciona apenas com o Microsoft Copilot ou pode ser usado com outros agentes de IA?
O pipeline foi projetado para alimentar qualquer AI agent ou interface downstream. Ele fornece uma base governada e pronta para retrieval, que pode ser consumida pelo Microsoft Copilot, Microsoft Foundry ou outras soluções de IA corporativas. A Parte 3 da série aborda a exposição via Foundry e Copilot. -
Quais são os principais riscos de adotar IA empresarial sem um knowledge pipeline como este?
Sem um pipeline, os modelos de linguagem não têm acesso a dados internos, o que leva a respostas genéricas, alucinações e falta de rastreabilidade. Segundo a IDC, menos da metade (44%) dos pilotos de IA saem da fase experimental, principalmente por má qualidade ou baixa atualização dos dados. Um knowledge pipeline mitiga esses riscos ao ancorar as respostas em documentos reais. -
Preciso reestruturar meus arquivos para usar esse pipeline?
Não. A arquitetura foi projetada para adaptar a IA à forma como as empresas já armazenam e gerenciam dados. Não há necessidade de re-plataforma ou reestruturação. Os arquivos permanecem em seus formatos originais, e a indexação semântica ocorre sobre o conteúdo existente.
Artigo originalmente publicado em Azure Updates - Latest from Azure Charts.
