

TL;DR: Este artigo mostra como estender IA a dados de arquivos corporativos sem migração, combinando Azure NetApp Files, Object REST API e OneLake. A chave é o padrão zero-copy: OneLake cria shortcuts virtuais para os dados, mantendo o NetApp Files como sistema de registro. Dados passam a ser endereçáveis por IA sem duplicação, alteração de workflows ou riscos de compliance.
Índice
- Introdução
- Por que a base de dados é fundamental?
- Expandindo além dos dados de colaboração
- O padrão zero-copy de base de dados
- Por que o OneLake muda o modelo?
- O que isso viabiliza
- Conclusão principal
- Saiba mais
Introdução
A IA empresarial avança rápido, mas muitas organizações descobrem um desafio comum: seus dados mais valiosos não estão acessíveis aos sistemas que desejam usar. Enquanto plataformas de colaboração e serviços de dados modernos são projetados para integração com IA, a maior parte do conhecimento empresarial ainda reside em sistemas de arquivos — alimentando aplicações críticas, workflows operacionais e sistemas de registro de longa data. Esses ambientes foram construídos para performance, confiabilidade e escala, não para descoberta ou raciocínio orientados por IA.
Isso cria uma lacuna fundamental. As organizações têm os dados necessários para alimentar IA, mas eles frequentemente ficam fora do alcance das plataformas modernas. Nesta série de artigos, exploramos como fechar essa lacuna sem reescrever workflows, migrar dados ou interromper sistemas existentes.
Coautores: Thomas Willingham e Sean Luce, Product Managers do Azure NetApp Files.
Por que a base de dados é fundamental?
Conforme as organizações aceleram a adoção de IA, um desafio familiar emerge: a IA é tão eficaz quanto os dados a que tem acesso. Modelos e ferramentas evoluem rapidamente, mas muitas empresas são limitadas por bases de dados que nunca foram projetadas para cargas de trabalho de IA.
O problema não é falta de dados. Muitas organizações já armazenam seu conhecimento institucional mais valioso em sistemas de arquivos corporativos:
- Especificações de engenharia e documentos de design
- Contratos legais e registros de compliance
- Políticas e procedimentos
- Runbooks técnicos
- Relatórios históricos e arquivos
Para muitas empresas, esses conteúdos vivem em sistemas de arquivos de alta performance como o Azure NetApp Files, acessados via workflows SMB e NFS consolidados. Os dados são rápidos, confiáveis e confiáveis, mas praticamente invisíveis para a IA. Arquivos são ricos em informação, mas fundamentalmente passivos: os usuários precisam saber onde procurar, e sistemas de IA não conseguem raciocinar sobre dados que não acessam. Essa desconexão entre onde o conteúdo corporativo vive e onde a IA pode operar é hoje um dos maiores bloqueios para a adoção escalável de IA.
Expandindo além dos dados de colaboração
Muitos cenários de IA atuais focam em dados de colaboração que são cloud-native, armazenados em SharePoint ou OneDrive e adequados para repositórios de pequeno a médio porte. Essa é uma classe importante e valiosa de dados, mas representa apenas parte da realidade empresarial. A IA corporativa exige ir além dos dados de colaboração para incluir sistemas de registro, onde reside a maior parte do conhecimento institucional.
A maioria das grandes organizações também depende de:
- Grandes ambientes NAS medidos em dezenas ou centenas de terabytes, frequentemente com milhões de arquivos
- Ambientes híbridos e on-premises
- Workflows SMB/NFS consolidados que não podem ser facilmente replataformados ou migrados
Esses ambientes não são falhas do SharePoint — eles atendem a necessidades diferentes. Sistemas de arquivos continuam sendo o sistema de registro para muitas cargas de trabalho reguladas, sensíveis a performance e com uso intensivo de documentos.
O desafio tem sido estender a IA e as plataformas de dados a essa classe de dados de arquivos corporativos sem forçar migração, duplicação ou mudança de workflow. Essa é a lacuna que o Azure NetApp Files e o Microsoft OneLake preenchem juntos.
O padrão zero-copy de base de dados
Para desbloquear a IA em dados de arquivos corporativos, precisamos de uma base diferente — que respeite os sistemas de registro existentes enquanto torna os dados acessíveis a serviços modernos de IA.
Esta solução introduz uma base de dados zero-copy, zero-migration construída sobre três componentes principais:
| Componente | Função |
|---|---|
| Azure NetApp Files | Sistema de registro para arquivos não estruturados corporativos (SMB/NFS) |
| Object REST API | Fornece acesso a objetos (compatível com S3) aos dados de arquivos |
| Microsoft OneLake | Camada unificada de dados que expõe os dados sem duplicá-los |
Os arquivos continuam sendo criados, atualizados e gerenciados no Azure NetApp Files exatamente como hoje. A Object REST API fornece acesso baseado em objetos a esses dados, permitindo que plataformas modernas de analytics e IA trabalhem diretamente com conjuntos de dados existentes sem copiar, mover ou reestruturar.
Esse mesmo padrão zero-copy já é usado para desbloquear analytics avançados e cenários de IA com serviços como Azure Databricks e Microsoft Fabric, validando sua adequação para cargas de trabalho corporativas de IA em larga escala.
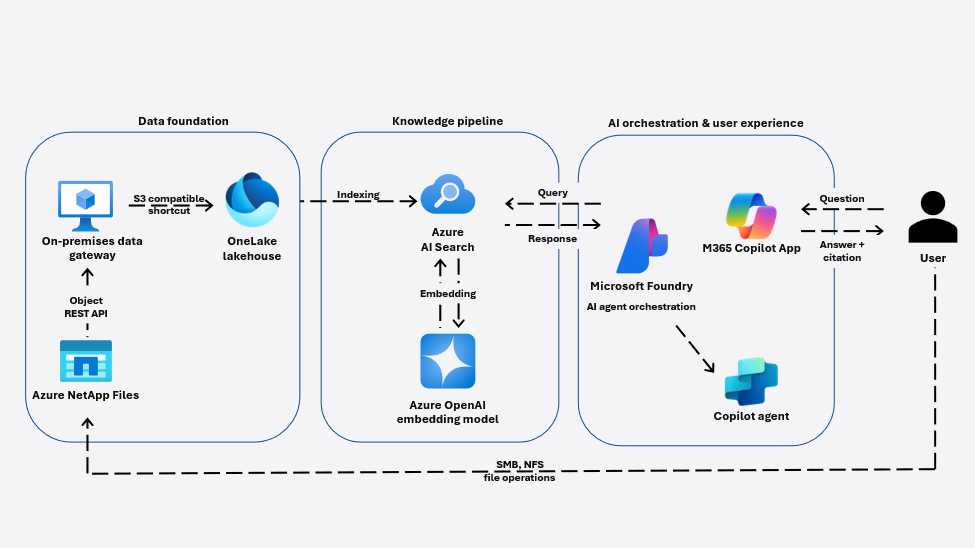
Por que o OneLake muda o modelo?
O Microsoft OneLake é frequentemente descrito como um "data lake único para toda a organização", mas sua capacidade mais importante nesta arquitetura é o que ele não faz.
OneLake não ingere os dados do Azure NetApp Files.
Em vez disso, ele:
- Cria shortcuts como ponteiros virtuais para dados externos
- Preserva ownership, permissões e padrões de acesso
- Evita duplicação de armazenamento e pipelines ETL
- Mantém o Azure NetApp Files como o sistema de registro autoritativo
Esse modelo baseado em shortcuts permite que o OneLake unifique dados entre nuvens, plataformas e ambientes on-premises enquanto mantém um namespace lógico único. Do ponto de vista da IA, isso é crítico: significa que dados de arquivos corporativos podem ser descobertos, indexados e raciocinados por serviços downstream sem quebrar limites de compliance, duplicar armazenamento ou introduzir risco de sincronização.
O que isso viabiliza
Com o Azure NetApp Files conectado ao OneLake por meio da Object REST API:
- Dados de arquivos corporativos tornam-se endereçáveis por IA
- Workflows SMB/NFS existentes permanecem inalterados
- Dados permanecem governados, seguros e de propriedade da plataforma original
- Sistemas de IA ganham visibilidade sobre conhecimento anteriormente inacessível
Essa arquitetura não substitui cenários baseados em SharePoint. Em vez disso, expande os cenários de IA e analytics de dados para um patrimônio de dados corporativos mais amplo e representativo.
Conclusão principal
O Azure NetApp Files é a base de alta performance, inteligente e ciber-resiliente para dados de arquivos corporativos, alimentando IA com dados de aplicações empresariais onde quer que eles estejam.
Ao combinar Azure NetApp Files, Object REST API e Microsoft OneLake, as organizações estabelecem uma base unificada e zero-copy que traz dados de arquivos corporativos para o escopo dos sistemas modernos de IA. Com essa base em vigor, o próximo passo é transformar esses dados em conhecimento utilizável.
Esta base de dados pronta para IA viabiliza capacidades e agentes de IA de nível superior que são governados e apresentados aos usuários nas camadas posteriores da arquitetura. Na Parte 2 — From File Data to AI‑Powered Knowledge Pipelines using Azure NetApp Files object REST API — exploraremos como essa base habilita um pipeline de conhecimento usando Azure AI Search e Azure OpenAI para suporte a Retrieval-Augmented Generation (RAG).
Saiba mais
- From File Data to AI‑Powered Knowledge Pipelines using Azure NetApp Files object REST API
- Bringing Enterprise File Data to Users with Azure NetApp Files, Microsoft Foundry, and M365 Copilot
- Understand Azure NetApp Files object REST API | Microsoft Learn
- Configure object REST API in Azure NetApp Files | Microsoft Learn
- Connect OneLake to an Azure NetApp Files volume using object REST API | Microsoft Learn
- How Azure NetApp Files Object REST API powers Azure and ISV Data & AI services – on YOUR data
- Unlocking Advanced Data Analytics & AI with Azure NetApp Files object REST API
Perguntas Frequentes
-
O que é o padrão zero-copy descrito no artigo?
É uma arquitetura em que os dados não são copiados nem movidos do sistema de origem. O OneLake cria shortcuts (ponteiros virtuais) para os dados no Azure NetApp Files, permitindo que serviços de IA acessem os arquivos sem duplicar armazenamento ou quebrar workflows SMB/NFS existentes. -
OneLake precisa ingerir os dados do Azure NetApp Files?
Não. OneLake não ingere ou copia os dados. Ele utiliza shortcuts como ponteiros virtuais, preservando ownership, permissões e padrões de acesso. O Azure NetApp Files continua sendo o sistema de registro autoritativo. -
Essa arquitetura substitui o uso do SharePoint para dados de IA?
Não. Ela expande os cenários de IA para além dos dados de colaboração (SharePoint/OneDrive), abrangendo sistemas de registro como NAS corporativos, workflows SMB/NFS e ambientes híbridos que não podem ser facilmente migrados. -
Quais serviços de IA conseguem consumir esses dados após a conexão com OneLake?
Com o OneLake expondo os dados via shortcuts, serviços downstream como Azure AI Search, Azure OpenAI, Azure Databricks e Microsoft Fabric podem descobrir, indexar e raciocinar sobre os arquivos corporativos, suportando padrões RAG (Retrieval-Augmented Generation). -
Há risco de quebra de compliance ou sincronização duplicada?
Não, porque os dados permanecem no Azure NetApp Files, governados pelo sistema original. OneLake apenas referencia os arquivos, evitando duplicação, riscos de sincronização e violação de limites de compliance.
Artigo originalmente publicado por Geert Van Teylingen em Azure Updates - Latest from Azure Charts.
