

TL;DR — Este artigo explica a terceira e última parte de uma arquitetura que torna dados de arquivos corporativos (Azure NetApp Files) acessíveis por assistentes de IA como o Microsoft 365 Copilot. Usando Microsoft Foundry como orquestrador de agentes, Azure AI Search para retrieval semântico e Azure OpenAI para geração fundamentada, é possível oferecer respostas em linguagem natural dentro do fluxo de trabalho do usuário (Teams, Copilot Chat), sem migração de dados, duplicação ou perda de governança. Ideal para empresas brasileiras que precisam escalar IA sobre dados legados sem comprometer compliance ou segurança.
Introdução
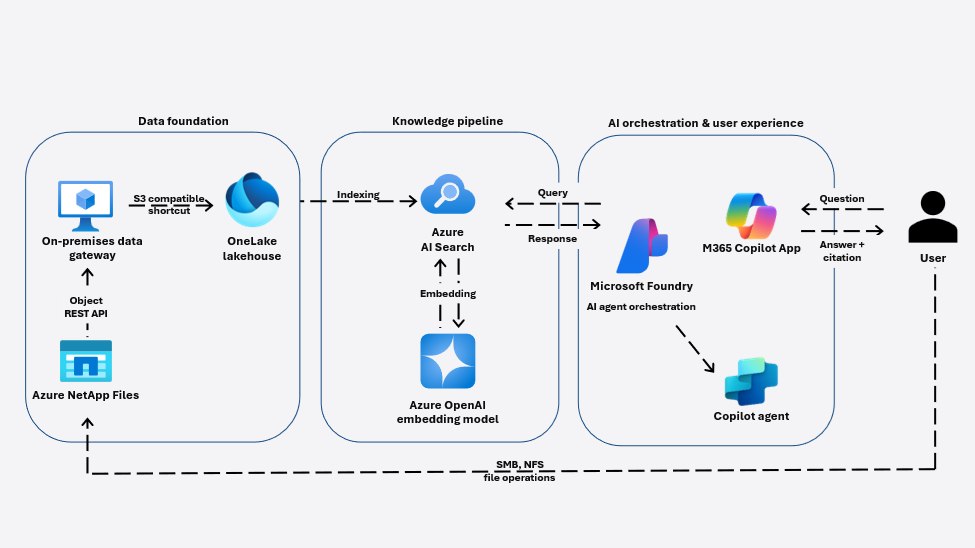
No Parte 1, estabelecemos uma fundação de dados zero‑copy que torna arquivos corporativos endereçáveis por IA usando Azure NetApp Files e Microsoft OneLake — sem migração, duplicação ou interrupção de fluxos.
Na Parte 2, mostramos como essa fundação é ativada por um pipeline de conhecimento usando Azure AI Search e Azure OpenAI, transformando arquivos não estruturados em um sistema de conhecimento vivo e consultável, fundamentado em Retrieval-Augmented Generation (RAG).
Nesta parte final, focamos na experiência do usuário: como essa arquitetura é exposta de forma segura e eficaz aos usuários finais por meio de agentes de IA empresarial, incluindo o Copilot, dentro do ambiente onde os colaboradores já trabalham.
Co-autores: Thomas Willingham (Product Manager, Azure NetApp Files) e Sean Luce (Product Manager, Azure NetApp Files)
Por que a camada de experiência do usuário é crítica na IA empresarial?
A adoção de IA empresarial raramente falha por insuficiência dos modelos. Ela falha quando os usuários precisam mudar a forma como trabalham, aprender novas ferramentas ou confiar em respostas opacas.
Para cenários centrados em conhecimento, o sucesso depende de três fatores:
- Usuários interagem com a IA dentro de seus fluxos de trabalho existentes.
- As respostas são fundamentadas em dados corporativos autorizados.
- As respostas são rastreáveis e auditáveis.
O Microsoft 365 Copilot fornece a experiência de linguagem natural ideal para essa camada. No entanto, o Copilot em si não “entende arquivos”. Ele depende de fontes de conhecimento externas e mecanismos de grounding bem definidos para recuperar e sintetizar informações com segurança.
É aqui que o Copilot Agent completa a arquitetura, com o Microsoft Foundry fornecendo a camada de orquestração por trás dele.
Microsoft Foundry: orquestrando agentes de IA empresarial
Antes de expor o conhecimento corporativo aos usuários finais por meio de agentes de IA como o Copilot, ele precisa ser montado, fundamentado e governado como uma capacidade de IA. Esse é o papel do Microsoft Foundry.
O Microsoft Foundry é o control plane para construir e governar agentes de IA empresarial. Ele define:
- Quais fontes de conhecimento um agente pode acessar,
- Como o retrieval e o grounding são aplicados,
- Como os modelos são restritos ao conteúdo corporativo recuperado, garantindo respostas fundamentadas, explicáveis e auditáveis.
Essa separação garante que o Copilot permaneça como a experiência do usuário, enquanto o Foundry governa como os agentes raciocinam sobre os dados, de forma segura e previsível.
O agente Copilot como experiência do usuário
O agente Copilot é construído e governado dentro do Microsoft Foundry, mas os usuários interagem com ele por meio do Copilot.
Em alto nível, o agente executa três funções críticas:
- Recebe perguntas em linguagem natural dos usuários dentro de experiências M365 (Teams, Copilot Chat).
- Consulta o índice do Azure AI Search construído sobre dados de arquivos corporativos referenciados via OneLake.
- Gera respostas fundamentadas usando Azure OpenAI, restrito ao conteúdo recuperado e enriquecido com citações das fontes.
Essa separação é intencional. O Copilot não lê o storage de arquivos diretamente, nem raciocina sobre documentos brutos. Em vez disso, consulta uma fonte de conhecimento curada e indexada, projetada especificamente para cenários RAG empresariais.
O resultado é uma experiência conversacional, mas previsível.
Fluxo de consulta completo
Quando um usuário faz uma pergunta no Copilot — como:
“Qual é o nosso procedimento de escalonamento de incidentes para violações de dados?”
A interação segue um fluxo controlado e seguro:
- Usuário submete a pergunta no Copilot.
- O Copilot Agent encaminha a consulta para o Azure AI Search.
- Chunks relevantes de documentos são recuperados usando busca semântica vetorial.
- Azure OpenAI sintetiza uma resposta usando apenas o conteúdo recuperado.
- Nomes dos arquivos fonte são incluídos na resposta para transparência.
Em nenhum momento o modelo infere informações de fora do conjunto de dados corporativo ou alucina respostas com base no treinamento geral.
Isso não é um chatbot sobreposto ao storage de arquivos. É um pipeline de retrieval e raciocínio governado, exposto por meio de uma experiência familiar e conversacional.
Por que esse padrão funciona em ambientes regulados e complexos?
Este modelo é especialmente poderoso para indústrias onde confiança, rastreabilidade e conformidade são inegociáveis.
Como as respostas são sempre fundamentadas em arquivos fonte específicos:
- Times jurídicos podem verificar interpretações contra a linguagem dos contratos.
- Times de segurança podem auditar respostas até runbooks oficiais.
- Times de compliance podem validar que políticas, e não suposições, estão sendo citadas.
Igualmente importante: os dados nunca saem do seu sistema de record:
- Arquivos permanecem governados e seguros no Azure NetApp Files.
- Controles de acesso continuam sendo aplicados na camada de storage.
- OneLake fornece virtualização, não duplicação.
- Serviços de IA operam sobre representações indexadas, não sobre conjuntos copiados.
Isso preserva os modelos de governança existentes enquanto estende seu alcance para experiências impulsionadas por IA.
Estendendo o Copilot além de cenários centrados em SharePoint
A maioria dos exemplos do Copilot foca em conteúdo de colaboração armazenado em SharePoint ou OneDrive. Esses são cenários válidos e importantes.
No entanto, o conhecimento empresarial não vive exclusivamente em repositórios colaborativos.
Grandes organizações dependem de:
- Sistemas de arquivos em rede contendo décadas de conhecimento operacional.
- Ambientes híbridos onde SMB e NFS são as interfaces primárias.
- Plataformas de storage de alta performance que não podem ser replataformadas.
Ao combinar Azure NetApp Files, OneLake, um pipeline de conhecimento baseado em RAG e Copilot, esta arquitetura estende o alcance do Copilot para a realidade do data estate corporativo, sem forçar esse data estate a mudar.
Do storage ao conhecimento à ação
Juntas, as três camadas formam uma arquitetura coesa:
- Parte 1: Fundação de Dados — Azure NetApp Files + OneLake tornam dados de arquivos corporativos endereçáveis por IA sem migração ou duplicação.
- Parte 2: Pipeline de Conhecimento — Azure AI Search + Azure OpenAI transformam arquivos em um sistema de conhecimento vivo usando RAG.
- Parte 3: Orquestração e Experiência do Usuário — Microsoft Foundry orquestra agentes de IA empresarial, e Copilot fornece uma forma natural e confiável para usuários fazerem perguntas e receberem respostas fundamentadas.
Isto não é uma solução de uso único. É um padrão de arquitetura repetível para permitir acesso seguro e contínuo a dados corporativos para IA, gerando valor de negócio real de forma segura, previsível e em escala.
Principais conclusões
A verdadeira promessa da IA empresarial não é substituir sistemas de record, mas torná-los inteligíveis.
Com esta arquitetura, o Azure NetApp Files se torna mais que storage de alta performance. Torna-se a base de um data estate preparado para IA, entregando insights fundamentados dentro do Copilot, sem comprometer desempenho, segurança ou confiança.
Juntas, essas três partes formam uma arquitetura completa para estender a IA a dados de arquivos corporativos – conectando sistemas de record a experiências de usuário impulsionadas por IA.
Colocando a arquitetura em prática
Esta série de três partes descreve um padrão repetível para levar IA a dados de arquivos corporativos; sem migração, duplicação, interrupção de fluxos de trabalho ou comprometimento de governança.
Para se aprofundar:
- Revise a arquitetura de referência descrita nesta série e mapeie para seu ambiente.
- Identifique cenários de conhecimento baseados em arquivos candidatos (segurança, compliance, operações).
- Engaje seus times de dados, storage e IA — entre em contato via [email protected] para aplicar este padrão usando Azure NetApp Files, Microsoft OneLake e Copilot.
A IA empresarial tem sucesso quando sistemas de record se tornam sistemas de inteligência.
Aprenda mais
- From Enterprise File Storage to an AI-Ready Data Foundation using Azure NetApp Files and OneLake
- From File Data to AI‑Powered Knowledge Pipelines using Azure NetApp Files object REST API
- Configure object REST API in Azure NetApp Files | Microsoft Learn
- OneLake, the OneDrive for data - Microsoft Fabric | Microsoft Learn
- Microsoft Foundry | Microsoft Learn
- Build a Copilot agent for Microsoft 365 | Microsoft Learn
Artigo originalmente publicado por GeertVanTeylingen em Azure Updates - Latest from Azure Charts.
Perguntas Frequentes
-
O Copilot consegue ler diretamente arquivos no Azure NetApp Files?
Não. O Copilot não acessa o storage diretamente. Ele consulta um índice do Azure AI Search construído sobre os dados referenciados via OneLake. O retrieval é feito por busca semântica, e o modelo Azure OpenAI só usa o conteúdo retornado para gerar a resposta, garantindo respostas fundamentadas e sem alucinações. -
Preciso migrar meus dados do Azure NetApp Files para o SharePoint para usar o Copilot?
Não. A arquitetura descrita permite que dados armazenados em sistemas de arquivos tradicionais (NFS, SMB) sejam virtualizados via OneLake sem duplicação. Isso estende o alcance do Copilot para além de cenários centrados em SharePoint, preservando os sistemas de record existentes. -
Como garantir que as respostas da IA sejam auditáveis e estejam em conformidade?
O Microsoft Foundry atua como control plane, definindo quais fontes de conhecimento o agente pode acessar e como o grounding é aplicado. As respostas são sempre vinculadas a arquivos fonte específicos, e os controles de acesso continuam sendo aplicados na camada de storage (Azure NetApp Files), permitindo auditoria por times jurídicos, de segurança e compliance. -
Essa arquitetura funciona bem em ambientes regulados (ex: bancos, saúde)?
Sim. O artigo destaca que o padrão é especialmente indicado para setores onde rastreabilidade e conformidade são obrigatórias, pois os dados nunca saem do sistema de record, a IA opera sobre representações indexadas e as respostas incluem citações dos arquivos originais.
