

TL;DR: Avaliadores genéricos não capturam critérios específicos de cada agente de IA. A Microsoft Foundry propõe avaliadores de rubrica auto-gerados: a partir da definição da tarefa e exemplos, o sistema gera uma rubrica com dimensões ponderadas, reutilizável entre iterações. Testes em seis benchmarks (JSON Editing, TauBench Telecom, BFCL, etc.) mostraram ROC AUC entre 0,794 e 0,972, correlação de Spearman de 0,69 a 0,98 e alta confiabilidade (ICC(3,1) = 0,85). Para empresas brasileiras, isso significa avaliação de agentes mais aderente a cenários reais com menos esforço manual.
Por que seu agente precisa de um avaliador específico para a tarefa?
Imagine um agente de atendimento ao cliente de uma operadora de telecomunicações. Um cliente entra em contato pedindo para trocar de plano e receber um reembolso por uma cobrança indevida. O agente precisa verificar a identidade do cliente e confirmar o novo plano antes de encerrar a conversa. Se pular a etapa de verificação, você tem um incidente de segurança. Esses critérios de sucesso são específicos para esse cenário.
O auto-generated rubric evaluator (avaliador de rubrica auto-gerado) foi projetado para resolver exatamente isso: usar o contexto que você já possui para gerar um avaliador de rubrica específico para a tarefa, que retorna um score ponderado com explicações por dimensão, e pode ser reutilizado ao longo das iterações.
Como a Microsoft validou a qualidade do avaliador?
A validação foi feita em quatro aspectos:
- Verdict Validity — se os julgamentos em casos reais refletem o que um revisor competente concluiria.
- Rubric Validity — se as rubricas geradas capturam os requisitos da tarefa e os modos de falha.
- Manual Quality Inspection — se os julgamentos parecem corretos para um revisor humano.
- Reliability and Separability — se os julgamentos são estáveis entre execuções e distinguem agentes candidatos mais fortes dos mais fracos.
Resultados da Validação
1. Concordância com sinais de referência confiáveis
A validação end-to-end usou o gerador de rubrica (GPT-5.4) para produzir as dimensões e depois o avaliador de rubrica para pontuar cada caso. A pergunta inicial: os scores acompanham sinais que as equipes já confiam? Para isso, selecionaram benchmarks conhecidos:
| Dataset | O que testa |
|---|---|
| JSON Editing | Tarefas determinísticas de edição estruturada onde saídas podem ser verificadas exatamente. |
| TauBench Telecom | Tarefas de agente de atendimento ao cliente que exigem seguir políticas, usar ferramentas e completar tarefas. |
| The Agent Company | Tarefas de agente de escritório de longo horizonte com uso de ferramentas multi-step. Subconjunto de 10 casos do InspectAI. |
| BFCL Multi-Turn Tool Calling | Comportamento de function calling multi-turn em cenários realistas de uso de ferramentas. |
| LiveClawBench | Tarefas de agente web abertas que exigem navegação, interação e julgamento. |
| Retail-Agent Customer Service | Conversas reais de suporte ao varejo em estilo produção. |
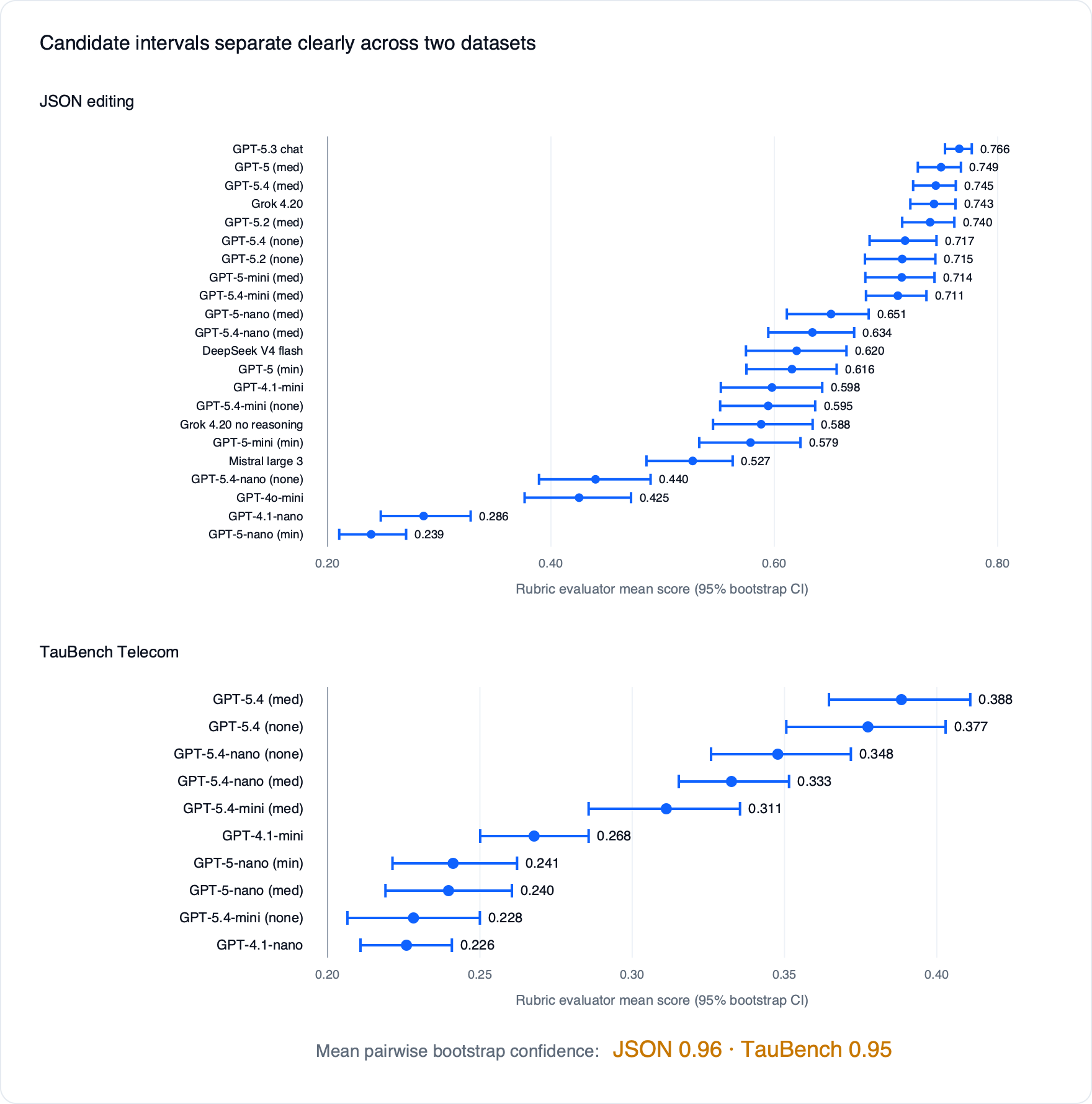
Para os três datasets com sinais de referência por caso, foi medida a correlação entre scores do avaliador e os sinais. Usando ROC AUC (que mede a capacidade de atribuir score maior a casos bem-sucedidos), os resultados foram: 0,794 no TauBench Telecom, 0,869 no The Agent Company e 0,972 no JSON Editing.
Em nível agregado de candidatos (útil para seleção de agentes), o Spearman ρ variou de 0,69 a 0,98 entre os cinco benchmarks, com agregação reduzindo ruído por caso.
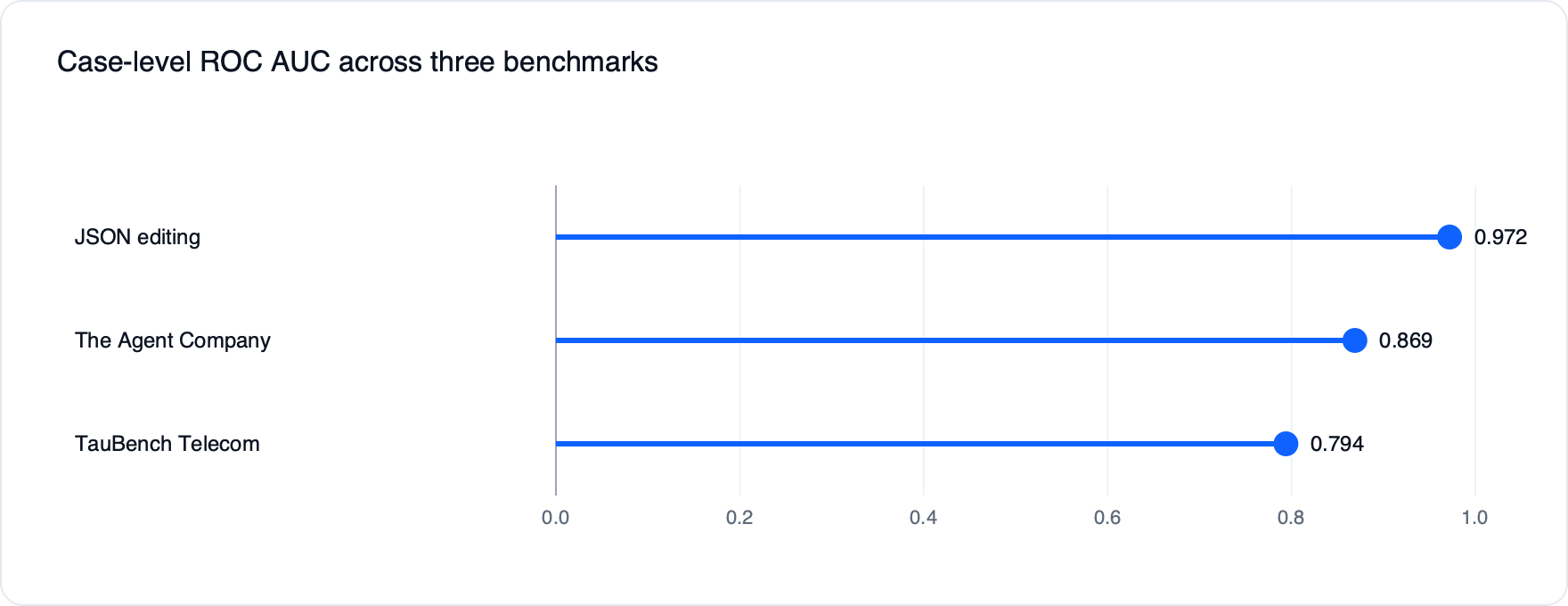
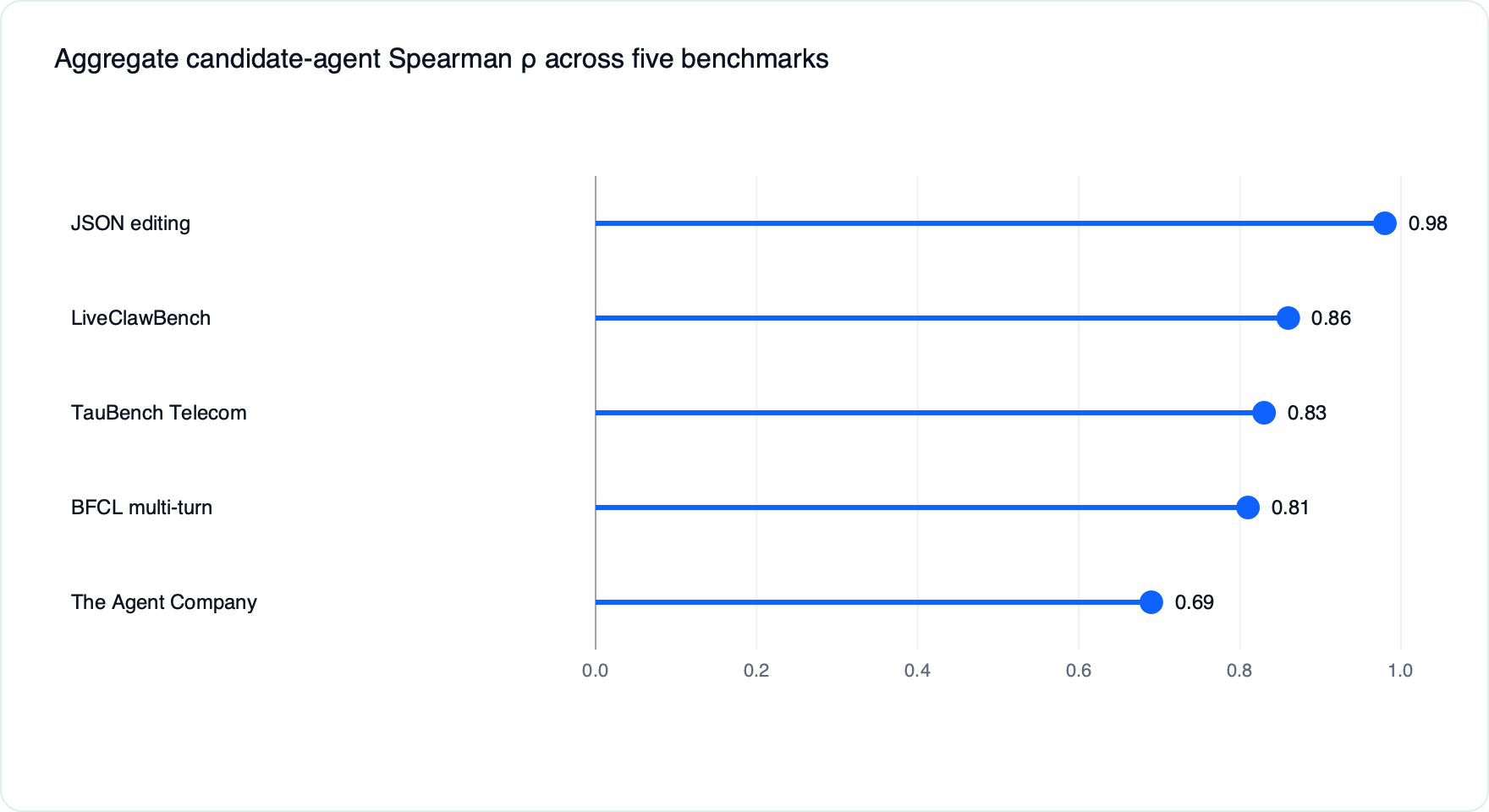
2. Qualidade da rubrica no GDPVal
O benchmark GDPVal mede quão bem modelos de IA realizam trabalho economicamente valioso em setores como governo, manufatura e serviços técnicos. Cada tarefa possui uma rubrica criada por especialistas. O gerador de rubrica alcançou 72,1% de recall e 86,4% de precisão contra as dimensões dos especialistas.
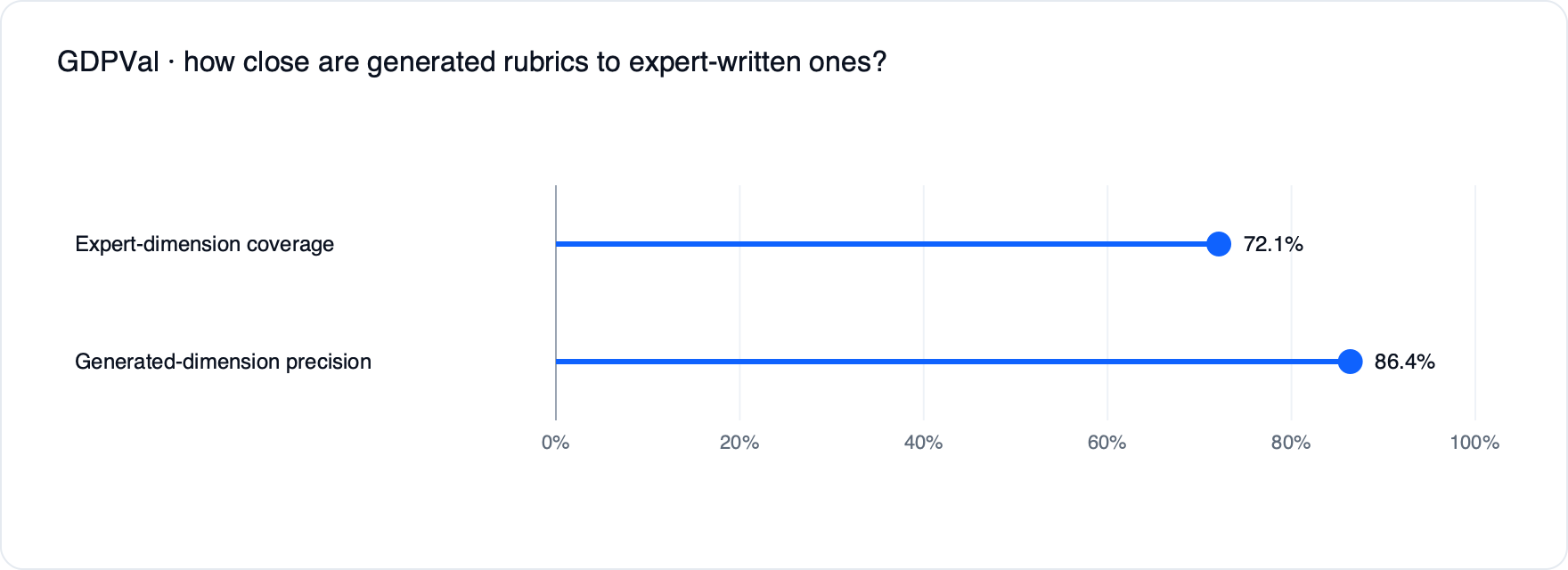
3. Qualidade manual em conversas de varejo
Para um dataset real de atendimento ao cliente de varejo, foi gerada uma rubrica com seis dimensões e avaliados 12 diálogos. Em uma inspeção manual de 72 julgamentos por dimensão, o revisor discordou de apenas um deles. A maioria dos casos neutros envolvia perguntas de aplicabilidade que o avaliador sinalizou inconsistentemente.
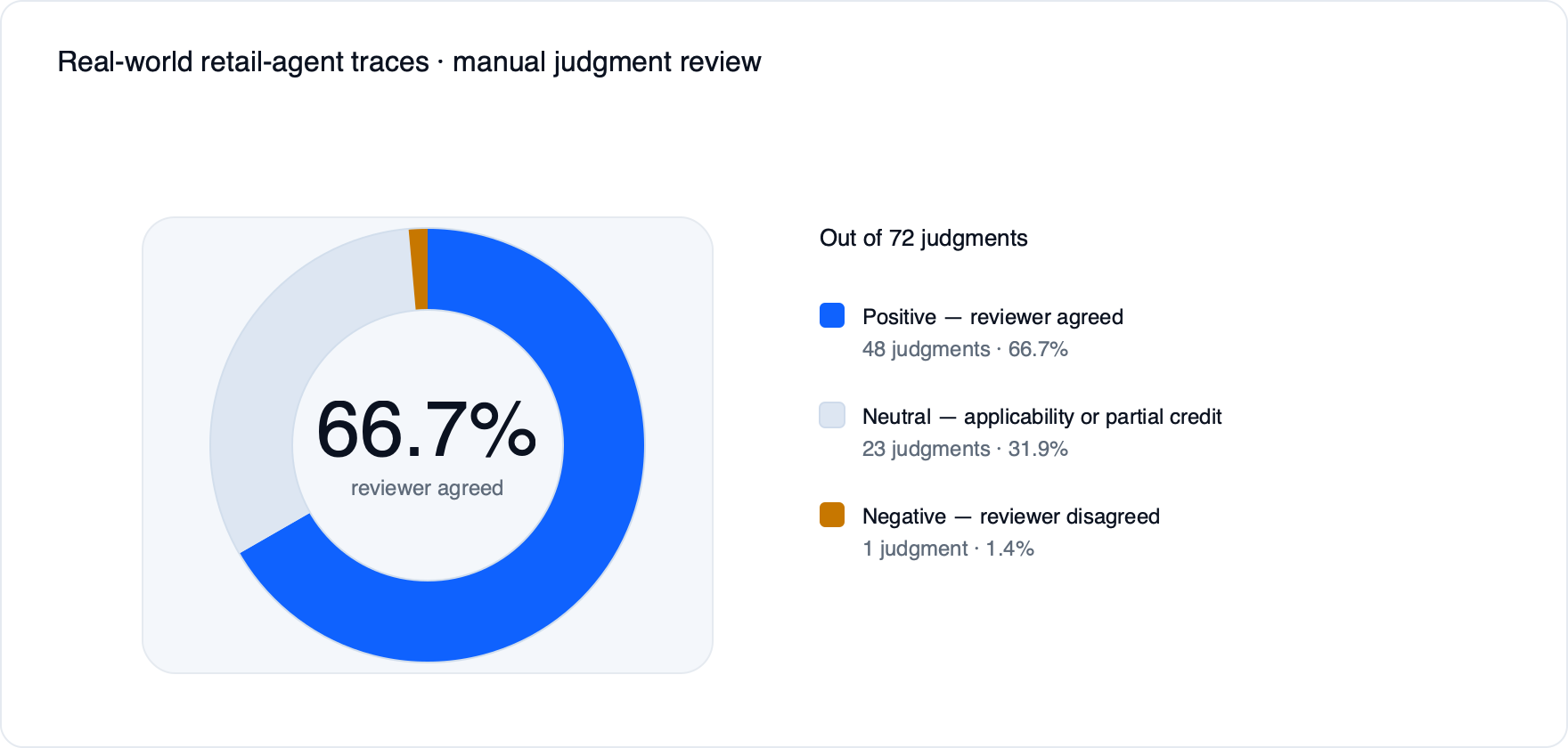
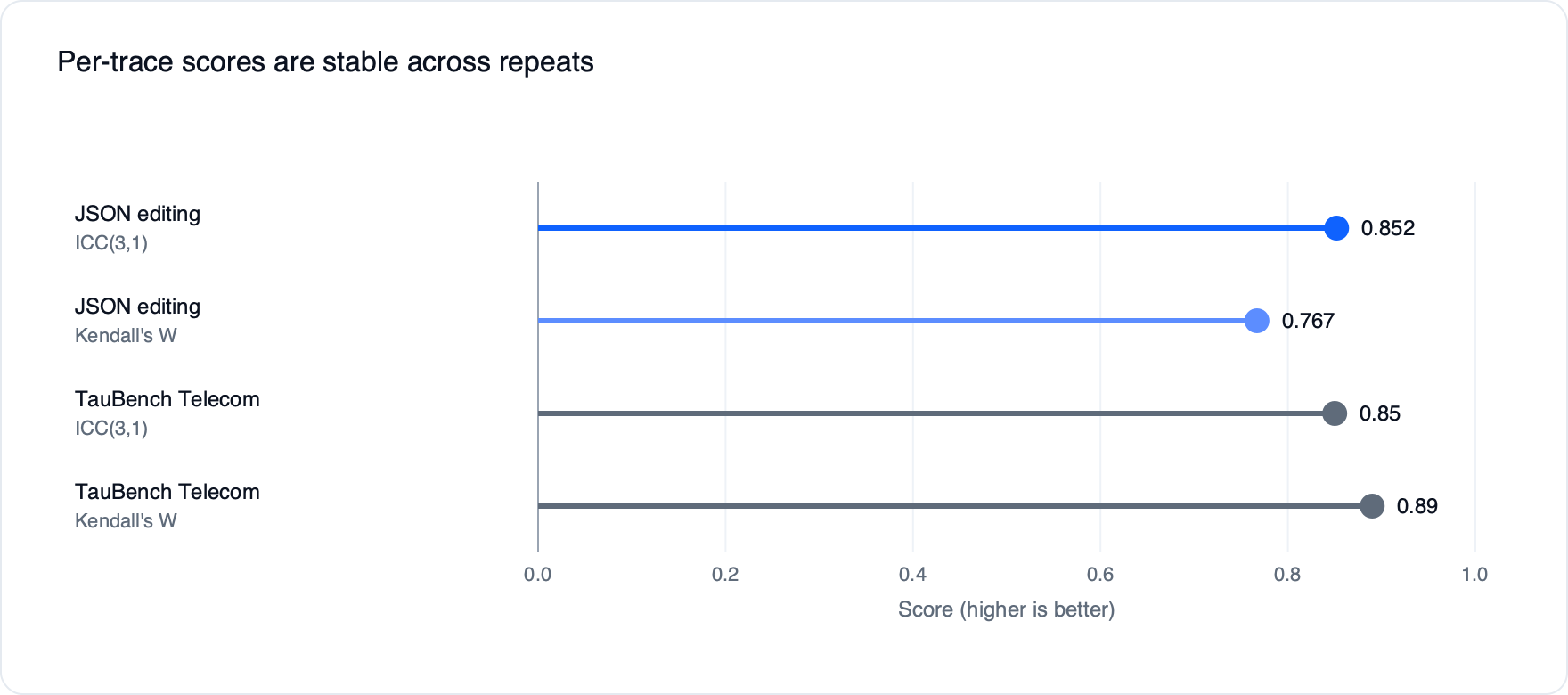
Confiabilidade e separabilidade
Confiabilidade
A estabilidade dos scores foi medida com ICC(3,1) e Kendall's W. No JSON Editing, ICC(3,1) = 0,852 e Kendall's W = 0,767. No TauBench Telecom, ICC(3,1) = 0,85 e Kendall's W = 0,89. Isso indica que reexecutar o avaliador no mesmo caso produz números similares.
Separabilidade
A separabilidade mede se o avaliador consegue dizer qual de dois agentes candidatos é melhor. Foi reportada mean pairwise bootstrap confidence: 0,96 no JSON Editing e 0,95 no TauBench Telecom, indicando ordenação consistente.
Como começar?
Os resultados podem variar conforme o design da tarefa, qualidade da entrada e configuração. A recomendação é: descreva claramente a tarefa no campo de prompt, inclua o máximo de contexto de alta qualidade (como definição do agente e exemplos), e revise a rubrica gerada antes de usar. Execute contra um pequeno conjunto de casos conhecidos como bons e ruins para entender como o score reflete diferentes modos de falha.
Experimente o workflow no portal da Foundry e siga o tutorial de rubric evaluator. Para uma demonstração completa, assista à sessão From observability to ROI for AI agents on any framework no Build.
Perguntas Frequentes
-
O que são avaliadores de rubrica auto-gerados?
São avaliadores gerados automaticamente pelo Microsoft Foundry a partir do contexto da tarefa (ex.: definição do agente, exemplos). Eles produzem um score ponderado por dimensões com explicações, podendo ser reutilizados em múltiplas iterações, ao contrário de avaliadores pré-construídos que podem ser genéricos demais. -
Quão confiáveis são esses avaliadores?
Os testes indicam alta confiabilidade: ICC(3,1) de 0,85 e Kendall's W de 0,89 no TauBench Telecom, e confiança bootstrap de 0,96 no JSON Editing. Isso significa que reavaliar o mesmo caso produz scores similares e que o avaliador distingue consistentemente agentes mais fortes de mais fracos. -
Que ganho prático uma empresa brasileira pode esperar ao usar esse recurso?
Redução significativa do esforço manual para criar métricas de avaliação personalizadas para agentes de IA em produção. Em vez de depender de revisão humana ou avaliadores genéricos, a ferramenta gera rubricas alinhadas a regras de negócio locais (ex.: compliance LGPD, políticas de atendimento) e valida agentes automaticamente. -
O avaliador funciona para qualquer tipo de agente?
Sim, desde que você forneça uma descrição clara da tarefa e contexto de qualidade. Os benchmarks testaram agentes de atendimento ao cliente (telecom, varejo), edição estruturada de JSON, chamadas de função multi-turn e agentes web, com resultados positivos. A Microsoft recomenda revisar a rubrica gerada antes do uso.
Artigo originalmente publicado por Shuo Qiu em Azure Updates - Latest from Azure Charts.
