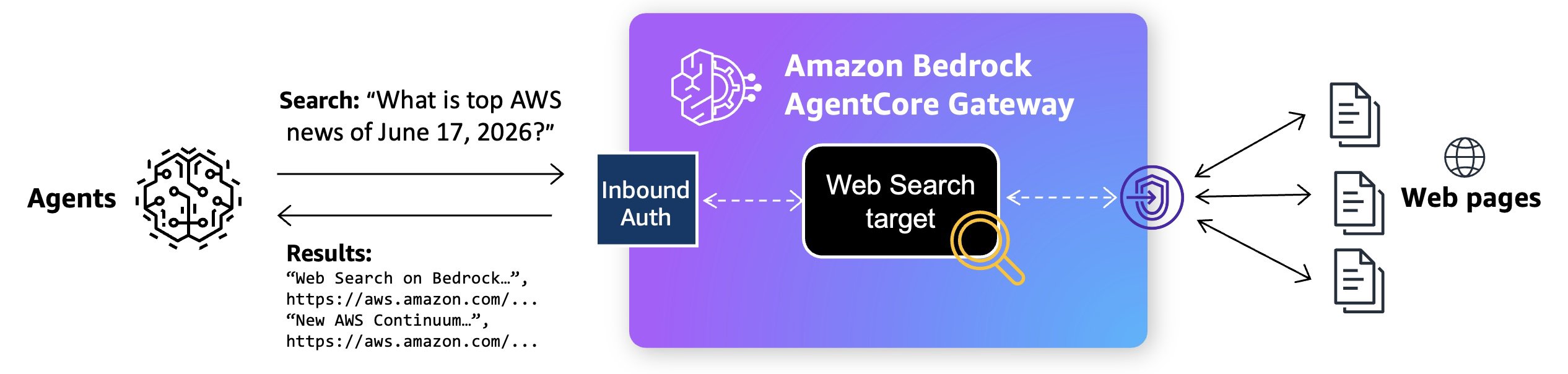
TL;DR — O Amazon Bedrock Managed Knowledge Base é um serviço gerenciado que abstrai toda a complexidade de construir e operar pipelines RAG (Retrieval-Augmented Generation). Com conectores nativos para fontes empresariais, Smart Parsing automático e um Agentic Retriever capaz de realizar buscas multi-hop entre múltiplas bases, ele permite que times de engenharia foquem na lógica de negócio em vez de infraestrutura. Para empresas brasileiras que desejam escalar aplicações de IA generativa com dados proprietários, a novidade reduz significativamente o custo operacional e acelera o time-to-market, mantendo flexibilidade para escolher modelos de embedding, re-ranking e geração.
A AWS anunciou hoje o Amazon Bedrock Managed Knowledge Base, um conjunto de capacidades que permite a desenvolvedores construir aplicações de IA generativa de nível empresarial usando dados proprietários em minutos. Organizações que constroem agentes de IA precisam de acesso seguro, confiável e atualizado a dados corporativos para entregar respostas precisas e rápidas. O Managed Knowledge Base abstrai a complexidade da construção e gestão de pipelines RAG, permitindo que desenvolvedores se concentrem em resultados de negócio, não em gerenciamento de infraestrutura.
Desenvolvedores que constroem bases de conhecimento para seus agentes enfrentam três desafios principais hoje:
- Conectar a dados empresariais – O conhecimento corporativo reside em sistemas heterogêneos, com diferentes tipos de conteúdo, listas de controle de acesso e formatos de documento. Manter conectores customizados para cada fonte adiciona complexidade que retarda o desenvolvimento.
- Otimizar a precisão do RAG – As melhores práticas para retrieval-augmented generation evoluem constantemente. Desenvolvedores precisam experimentar diferentes estratégias de parsing, abordagens de chunking, modelos de embedding e comportamentos de retrieval agentivo para obter respostas precisas de seus dados.
- Gerenciar infraestrutura em escala – Organizações precisam servir grandes bases de conhecimento com milhões de documentos, ou gerenciar milhares de bases menores entre equipes. Ambos os padrões exigem infraestrutura confiável, segurança e controle de custos.
Esses desafios forçam os desenvolvedores a realizar trabalho indiferenciado repetidamente, em vez de focar em suas aplicações.
O Amazon Bedrock Managed Knowledge Base resolve esses problemas abstraindo os múltiplos componentes de infraestrutura que os desenvolvedores tradicionalmente precisam montar e manter (armazenamento, recuperação, embeddings, re-ranking e seleção de modelo de fundação) em um único primitive gerenciado. Por padrão, o serviço automaticamente seleciona e gerencia um modelo de embeddings, um re-ranker e um modelo de fundação ideais, permitindo que você comece rapidamente sem precisar escolher ou manter cada um. Sobre essa base gerenciada, três inovações principais melhoram ainda mais a facilidade de uso e a precisão:
- Conectores de dados nativos – Seis conectores pré-construídos que extraem nativamente dados e permissões de aplicações SaaS, eliminando a sobrecarga que os desenvolvedores enfrentam ao gerenciar requisitos específicos de cada aplicação. No lançamento, oferecemos suporte a Amazon S3, SharePoint, Confluence, Web Crawler, Google Drive e OneDrive.
- Smart Parsing – Diferentes tipos de conteúdo e fontes exigem abordagens distintas para alcançar recuperação precisa. O Smart Parsing lida com essa complexidade automaticamente, selecionando a estratégia de parsing correta para cada tipo de dado e conector, fornecendo a maior precisão para seus agentes.
- Agentic Retriever – Otimizado para consultas complexas que exigem recuperação multiturn e multihop dentro de uma única base de conhecimento ou entre várias bases. O Agentic Retriever infere automaticamente a intenção do usuário final e extrai contexto relevante do conhecimento institucional distribuído entre fontes e modalidades.
Com apenas algumas linhas de código, o Amazon Bedrock Managed Knowledge Base gerencia e escala automaticamente o pipeline RAG completo que alimenta seus agentes de conhecimento empresarial. Para construtores de agentes, ele está disponível como um tipo de target pré-construído no Amazon Bedrock AgentCore Gateway, reduzindo a integração a poucas linhas de código, gerando permissões baseadas em papéis automaticamente e fornecendo observabilidade e métricas de avaliação no painel AgentCore Observability.
Primeiros passos com Amazon Bedrock Managed Knowledge Base
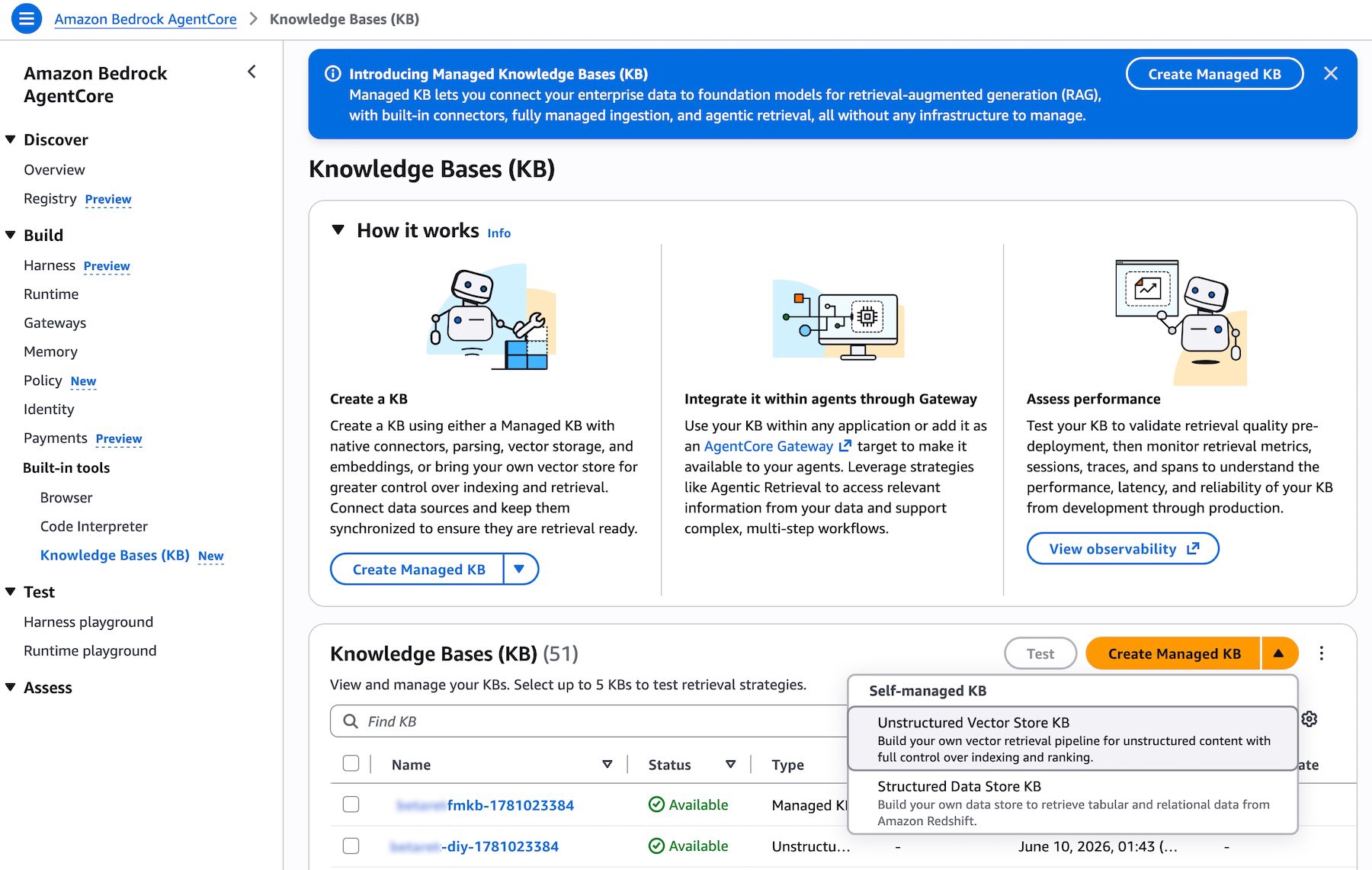
Criar uma Managed Knowledge Base é simples. Navegue até o console do Amazon Bedrock AgentCore ou o console do Amazon Bedrock, abra a página Knowledge Bases e escolha Create Managed KB. A experiência é a mesma em ambos os consoles. Você verá que Unstructured Vector Store KB está agora disponível como opção recomendada, junto com outros tipos de knowledge base que você já conhece:
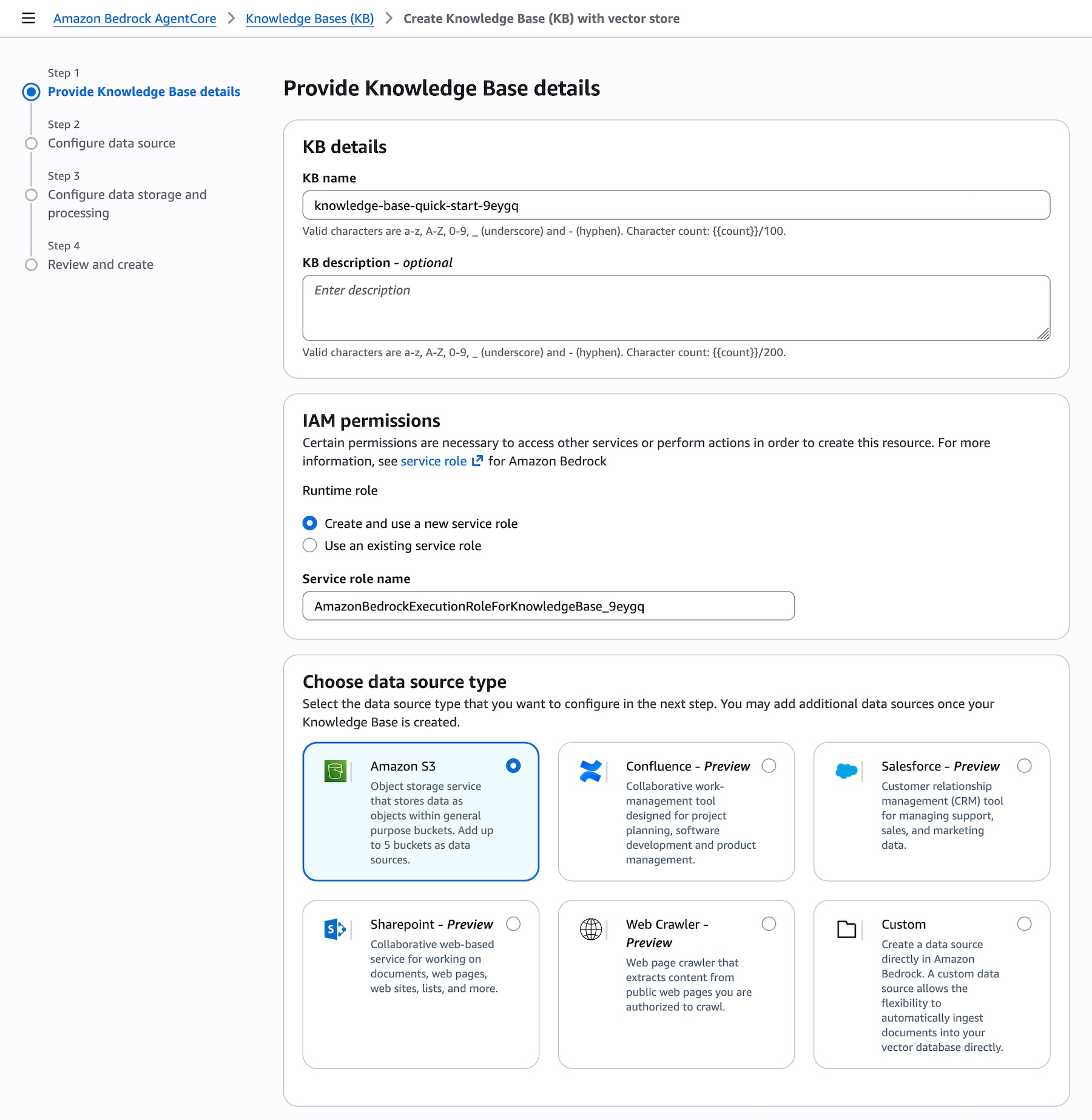
Ao criar uma nova Knowledge Base, você pode conectar suas fontes de dados empresariais escolhendo a partir de uma lista de conectores suportados diretamente em um dropdown. As roles do AWS Identity and Access Management (IAM) são criadas automaticamente, e você pode editar essas permissões se necessário:
Um conjunto otimizado de defaults será apresentado, permitindo que você crie sua knowledge base em apenas alguns cliques. Depois que os dados forem sincronizados, você pode integrar a knowledge base ao seu agente ou fornecê-la como uma ferramenta para seu modelo de fundação e começar a consultar.
Smart Parsing para ingestão precisa de dados
Um dos principais desafios na construção de bases de conhecimento é preparar tipos de dados diversos para recuperação precisa. Depois que você aponta o Managed Knowledge Base para suas fontes de dados, o Smart Parsing determina automaticamente a estratégia de parsing ideal para cada tipo de dado e conector, sem necessidade de configuração extra.
O Smart Parsing combina múltiplas técnicas:
- Modelos de dados específicos do conector – Tratamento otimizado para cada fonte de dados. Por exemplo, o conector Web Crawler preserva a estrutura HTML, incluindo imagens e tabelas incorporadas, garantindo que conteúdo rico não seja perdido durante a ingestão. Conectores SharePoint mantêm a hierarquia de documentos e relacionamentos entre arquivos.
- Processamento multimodal – Detecção e processamento automáticos de diferentes tipos de conteúdo dentro de documentos. O sistema identifica bounding boxes em documentos e os envia para modelos de fundação para extração de dados, legendagem e descrição de cenas em arquivos de vídeo.
- Chunking otimizado – O Smart Parsing utiliza modelos de fundação para entender a estrutura do documento e extrair conteúdo significativo, garantindo que documentos complexos com formatos mistos sejam indexados adequadamente. Defaults inteligentes equilibram precisão de recuperação com desempenho baseado no tipo de documento e estrutura de conteúdo, enquanto usuários avançados podem personalizar estratégias de chunking quando necessário.
Essa abordagem automatizada elimina semanas de experimentação normalmente necessárias para alcançar precisão de recuperação em produção, preservando ainda a flexibilidade para personalização quando necessário.
Usando o Agentic Retriever para consultas complexas
Após a ingestão dos dados, você pode começar a consultar sua knowledge base. Aplicações de IA generativa frequentemente enfrentam dificuldades com consultas complexas que exigem raciocínio, recuperação recursiva multi-etapas e avaliações intermediárias dos resultados. Considere um usuário fazendo duas perguntas relacionadas: “Qual é o orçamento de infraestrutura em nuvem para o time da plataforma de ML?” e “Nossa política de despesas permite pagamento antecipado de compromissos anuais?”. Uma única etapa de recuperação pode encontrar documentos sobre o time de ML, mas falhar em conectar a informação de orçamento com a política de despesas necessária para responder completamente à pergunta.
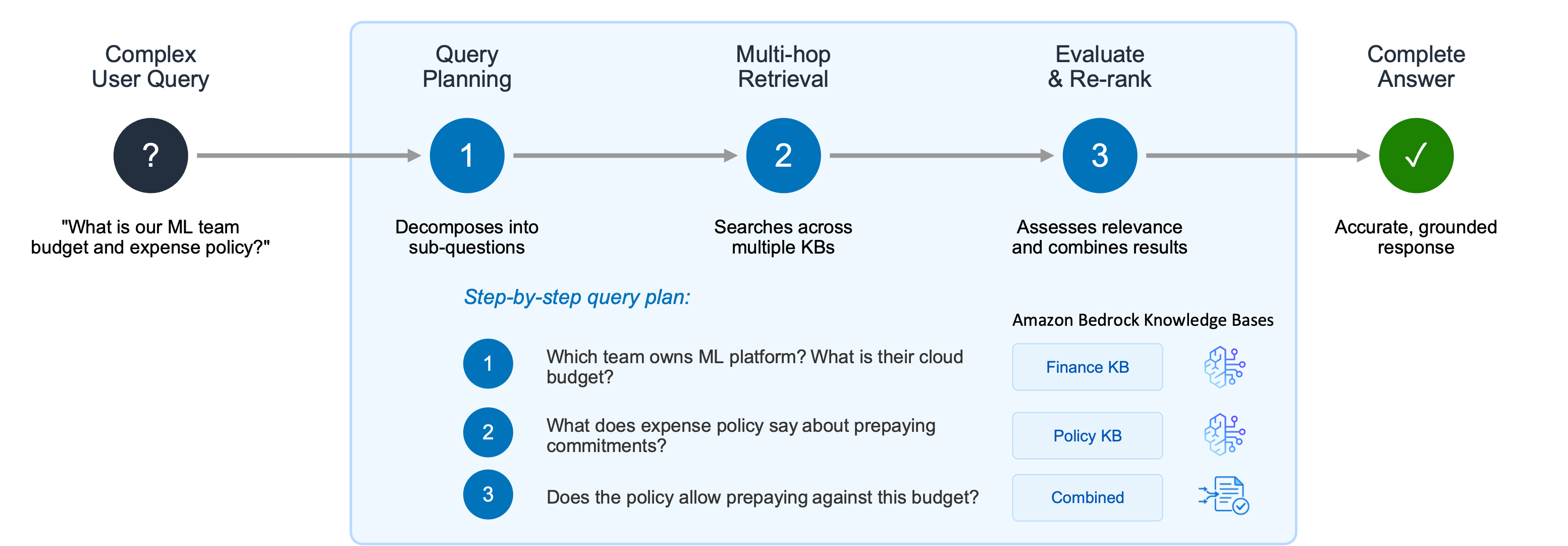
O Agentic Retriever resolve isso criando um plano de consulta passo a passo: 1. Qual time é dono da plataforma de ML e qual é o orçamento de infraestrutura? 2. O que a política de despesas diz sobre pagamento antecipado de compromissos anuais? 3. A política permite que o time de ML pague antecipadamente dentro desse orçamento?
O sistema realiza recuperação multi-hop e raciocínio em cada etapa e, uma vez que tenha reunido passagens relevantes suficientes, interrompe o processo de busca e retorna os melhores resultados. Ao abstrair a complexidade de construir um pipeline de raciocínio multi-hop separado, essa abordagem melhora dramaticamente a precisão para consultas complexas, permitindo que desenvolvedores foquem em suas aplicações de busca agentiva em vez de lógica de orquestração.
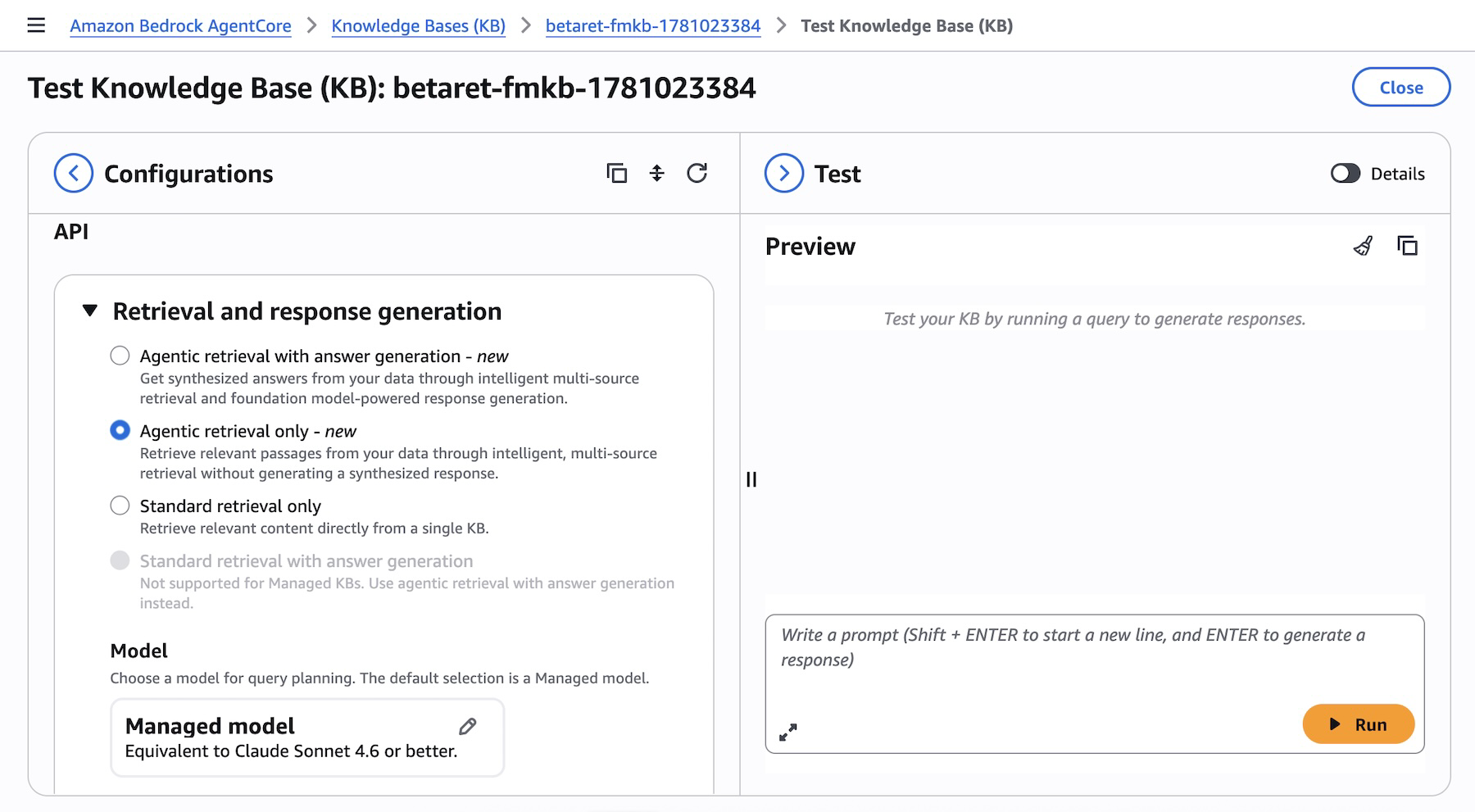
Você pode testar o Agentic Retriever diretamente do painel de teste da sua knowledge base no console do Amazon Bedrock AgentCore. Selecione Agentic retrieval only como tipo de recuperação para deixar o sistema planejar e executar automaticamente consultas multi-etapas entre suas bases de conhecimento:
Habilitando MCP com Bedrock AgentCore
O Amazon Bedrock Managed Knowledge Base se integra perfeitamente ao AgentCore Gateway como um tipo de target nativo. Essa integração elimina a necessidade de integração manual e fornece observabilidade embutida, aplicação de políticas e gerenciamento automático de permissões.
Você pode navegar até o console do Amazon Bedrock AgentCore ou SDK e criar um AgentCore Gateway ou selecionar um existente. Ao adicionar targets ao seu gateway, você encontrará Knowledge Base como um novo tipo de target pré-construído, juntamente com outras opções como servidor MCP, Lambda ARN, REST API e outras integrações. Basta selecionar o ID da sua knowledge base para expô-la através do gateway:
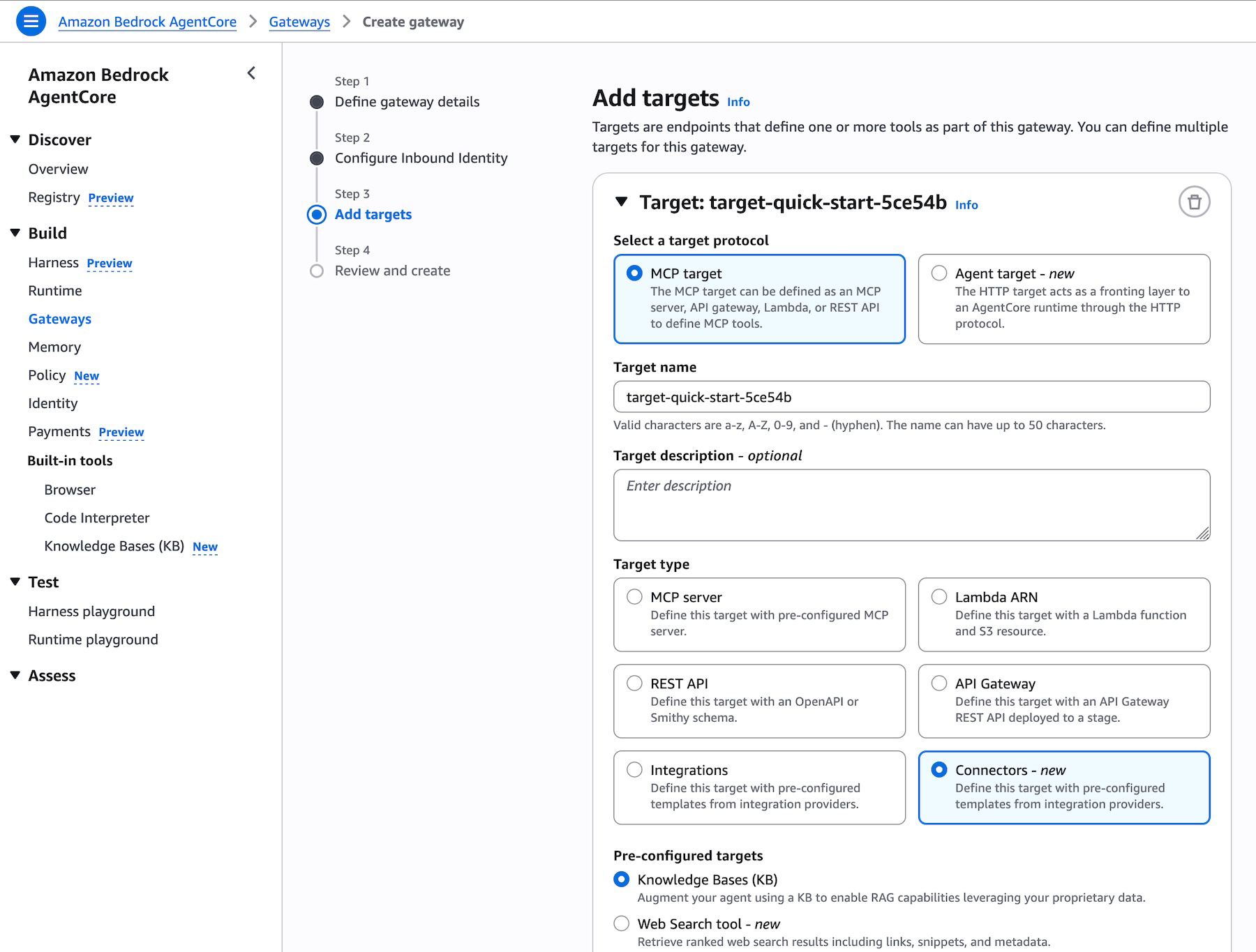
O gateway expõe o Model Context Protocol (MCP) padrão, para que as ferramentas da knowledge base sejam automaticamente descobertas por clientes de qualquer framework compatível com MCP, incluindo Strands Agents, LangChain, CrewAI, LlamaIndex e LangGraph. Nenhum código de integração personalizado é necessário.
Escolha e flexibilidade de modelos
O Amazon Bedrock Managed Knowledge Base preserva a flexibilidade que os desenvolvedores esperam do Amazon Bedrock. Cada modelo de fundação disponível no Bedrock pode alimentar a etapa de geração, e os desenvolvedores podem selecionar diferentes modelos de embedding e re-ranking para otimizar a recuperação para seu caso de uso específico, permitindo que as equipes ajustem a precisão e o custo-desempenho sem alterar a infraestrutura.
Diferente de soluções gerenciadas que prendem você a provedores de modelo específicos, o Amazon Bedrock Managed Knowledge Base separa o gerenciamento de infraestrutura (conectores, parsing, armazenamento, orquestração de recuperação) da seleção de modelos. Isso significa que você pode:
- Aproveitar os modelos mais recentes – Adotar novos modelos de embedding, re-ranking e fundação à medida que se tornam disponíveis para melhorar precisão, latência e custo da sua aplicação sem reconstruir o pipeline RAG.
- Otimizar para price-performance – Escolher modelos menores e mais rápidos para consultas simples e modelos mais capazes para tarefas complexas de raciocínio, tudo usando a mesma infraestrutura de knowledge base.
- Usar modelos de embedding do Bedrock – Embora o Smart Parsing forneça defaults otimizados, você pode configurar modelos de embedding do Bedrock quando seu domínio exigir compreensão semântica especializada.
- Manter consistência com aplicações existentes – Se você já usa as APIs do Bedrock Knowledge Bases (
Retrieve,StartIngest,StopIngest,IngestKnowledgeBaseDocuments), o Managed Knowledge Base utiliza as mesmas APIs, portanto a migração não requer alterações de código — basta apontar para o novo ID da knowledge base.
Essa abordagem garante que você possa gastar tempo em sua aplicação de IA generativa sem perder a capacidade de trocar de modelos com base em requisitos em evolução ou novas capacidades dos modelos.
Comece hoje
O Amazon Bedrock Managed Knowledge Base está disponível hoje nas regiões US East (N. Virginia), US West (Oregon), Asia Pacific (Sydney, Tokyo), Europe (Dublin, Frankfurt, London) e AWS GovCloud (US-West). Para disponibilidade regional e roadmap futuro, visite AWS Capabilities by Region.
Com o Bedrock Managed Knowledge Base, você paga pelo que usa, sem compromissos antecipados. O preço é baseado em duas dimensões: o tamanho dos dados indexados armazenados e o número de retrievals realizados (on-demand). Para detalhes de preço, visite a página de preços do Amazon Bedrock. O Bedrock também faz parte do AWS Free Tier que novos clientes AWS podem usar para começar sem custo e explorar os principais serviços da AWS.
Essas capacidades funcionam com qualquer framework open source como CrewAI, LangGraph, LlamaIndex e Strands Agents, e com qualquer modelo de fundação. Os serviços Bedrock podem ser usados juntos ou independentemente, e você pode começar usando seu ambiente de desenvolvimento assistido por IA favorito com o AgentCore open source MCP server.
Para saber mais e começar rapidamente, visite o Bedrock Knowledge Bases Developer Guide.
Perguntas Frequentes
-
Como o Managed Knowledge Base gerencia permissões de acesso aos dados corporativos?
O serviço cria automaticamente roles do IAM e permite editar permissões manualmente. Os conectores nativos (SharePoint, Confluence, etc.) herdam as ACLs dos sistemas de origem, garantindo que apenas usuários autorizados acessem as informações corretas durante a recuperação. -
Quais conectores de dados estão disponíveis no lançamento?
Seis conectores pré-construídos são suportados: Amazon S3, SharePoint, Confluence, Web Crawler, Google Drive e OneDrive. A AWS planeja adicionar mais fontes no futuro, mas já cobre os principais repositórios empresariais usados por organizações brasileiras. -
O Agentic Retriever funciona com múltiplas bases de conhecimento simultaneamente?
Sim. O Agentic Retriever pode realizar retrieval multi-hop entre várias bases de conhecimento. Ele decompõe consultas complexas em etapas, busca em diferentes fontes e combina os resultados, tudo de forma automática, sem que o desenvolvedor precise orquestrar manualmente. -
É possível migrar uma knowledge base existente do Bedrock para o Managed Knowledge Base sem alterar o código?
Sim. O Managed Knowledge Base utiliza as mesmas APIs que as knowledge bases tradicionais do Bedrock (Retrieve, StartIngest, etc.). A migração requer apenas apontar para o novo ID da knowledge base gerenciada, sem necessidade de reescrever integrações ou pipelines. -
Em quais regiões o Managed Knowledge Base está disponível?
No lançamento, o serviço está disponível em US East (N. Virginia), US West (Oregon), Asia Pacific (Sydney, Tokyo), Europe (Dublin, Frankfurt, London) e AWS GovCloud (US-West). Para empresas brasileiras, as regiões mais próximas são Virgínia (us-east-1) e Oregon (us-west-2), com latências adequadas para a maioria dos casos.
Artigo originalmente publicado por Daniel Abib em AWS News Blog.