

TL;DR: Este artigo analisa como a Trustpilot substituiu seu pipeline de reviews baseado em modelos encoders por uma arquitetura em tempo real com Gemma fine-tuned, hospedada no Google Cloud. A conclusão principal: com fine-tuning de modelos abertos, é possível atingir performance similar a modelos frontier como Gemini por uma fração do custo, garantindo independência de fornecedores e previsibilidade financeira — uma abordagem especialmente relevante para empresas brasileiras que buscam escalar com controle.
Processar milhões de reviews de usuários em tempo real, com restrições rígidas de latência e custo, não é tarefa simples. A Trustpilot já fazia isso com machine learning customizado muito antes de os grandes modelos de linguagem (LLMs) virarem hype. Agora, ao migrar seu stack central para IA generativa, a empresa construiu um pipeline de streaming de alto volume usando modelos Gemma fine-tuned. Neste artigo, detalhamos como essa arquitetura foi concebida e o que empresas brasileiras podem aprender com ela.
Como a Trustpilot extrai inteligência profunda de reviews em escala?
O core business da Trustpilot depende de entregar inteligência de reviews acionável e profunda. Como plataforma que preza por transparência e feedback genuíno, ela precisa preservar a integridade dos dados e maximizar seu valor. Isso significa extrair cada gota de metadados dos reviews recebidos — e LLMs são a ferramenta ideal para isso.
Esses modelos são excelentes em interpretar textos humanos confusos para realizar reconhecimento de entidades nomeadas (NER), categorizar domínios de negócio, pontuar sentimento e identificar a intenção do cliente. O problema? Pedir a um LLM para analisar alguns reviews é simples; processar milhões em tempo real sem explodir os custos é um gargalo de engenharia colossal.
Por que fazer fine-tune de um modelo aberto em vez de usar uma API pronta?
Diante de um desafio dessa magnitude, por que não simplesmente plugar um modelo frontier poderoso como o Gemini via API? Para um pipeline tão crítico ao negócio, modelos fechados raramente são a melhor opção. Ao fine-tunar modelos de pesos abertos como o Gemma, a Trustpilot assume total controle de sua estratégia de IA. Eis os motivos:
- Independência total de modelo: Ao ser dona dos modelos, a Trustpilot controla o ciclo de retraining, livrando-se completamente do cronograma de atualizações de terceiros ou de mudanças súbitas de API.
- Economia previsível: A migração de um modelo de precificação variável por token para custos fixos de infraestrutura torna viável e otimizável a execução de milhões de predições.
- Expansão das capacidades de MLOps: Construir os modelos internamente permite à Trustpilot incorporar seu "diferencial secreto" de inteligência de reviews, ao mesmo tempo que desenvolve competências em modelos de pesos abertos.
- Continuidade arquitetural: Padronizar-se em uma linhagem de modelo aberto preserva a capacidade de aproveitar futuras iterações do modelo base, obtendo ganhos de performance com mínimo overhead de engenharia.
Em vez de implantar um modelo enorme, a Trustpilot criou uma suíte de modelos altamente especializados usando o leve google/gemma-2-9b como base.
Para obter performance de peso-pesado a partir de um footprint pequeno, a empresa empregou anotação por consenso sobre uma amostra estratificada do corpus de reviews, usando uma seleção de modelos teacher da família Gemini 2.0/2.5 Pro/Flash. Esse processo gerou datasets de treinamento de alta qualidade para tarefas específicas como classificação de tópicos, NER e extração de sentimento.
Os datasets foram então usados para fine-tunar uma linha de modelos customizados que superaram consideravelmente a solução legada e entregaram precisão apenas alguns pontos percentuais abaixo do consenso dos modelos teacher.
Qual foi a arquitetura do sistema?
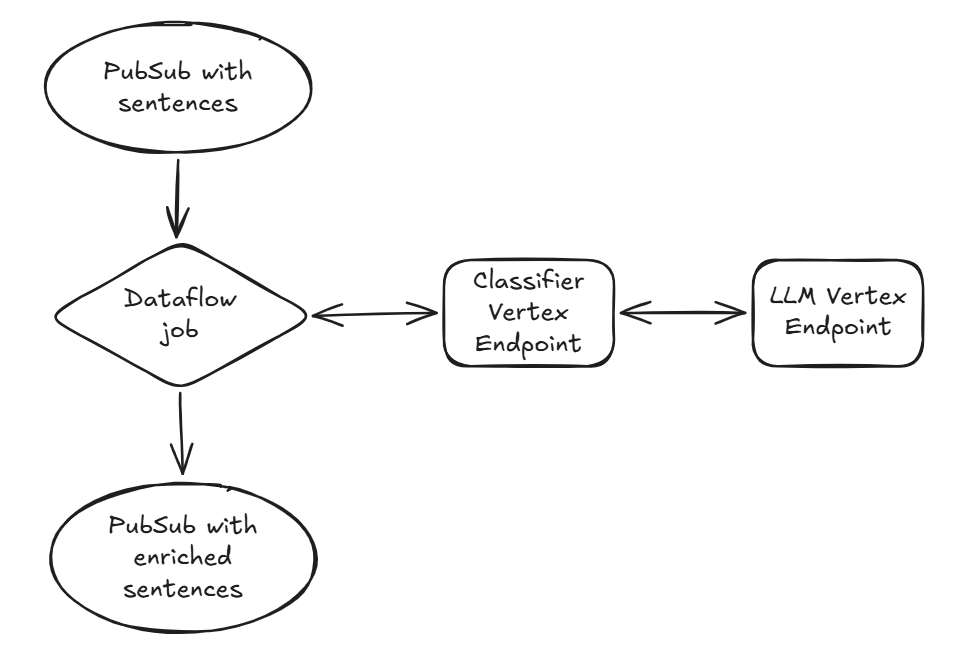
A arquitetura foi construída sobre Dataflow e Gemini Enterprise Agent Platform Endpoints, que se integram nativamente graças ao VertexAIModelHandlerJSON.
A equipe desacoplou a lógica de negócio da inferência bruta do LLM criando dois endpoints separados:
- O classificador: um endpoint baseado em FastAPI que cuida da parte "suja": pré/pós-processamento, template de prompts e chaining.
- O LLM: um endpoint dedicado exclusivamente a servir o modelo Gemma via vLLM.
Essa abordagem mantém o job do Dataflow limpo e garante que o endpoint LLM faça apenas o que sabe de melhor: gerar texto. Além disso, permite que a Trustpilot escale cada componente de forma independente conforme o tráfego.
Como foi o tuning de performance?
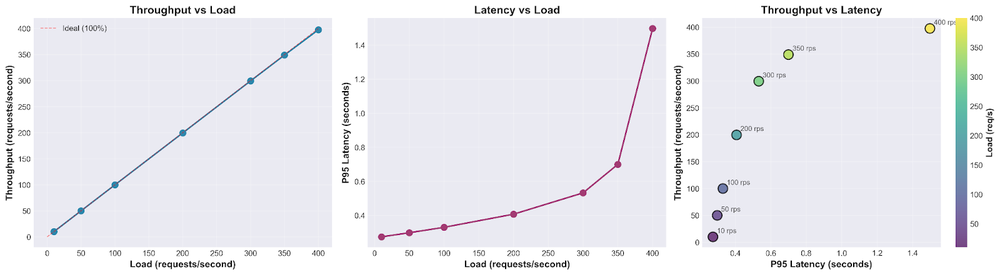
Para extrair o máximo dos endpoints vLLM no Agent Platform, a Trustpilot focou em otimizar cada etapa do pipeline, especialmente as VMs A2 com GPUs A100. Também aproveitou a versão customizada e otimizada do vLLM mantida pela plataforma.
Um dos focos foi otimizar a configuração do backend vLLM para evitar gargalos de processamento. Ajustando cuidadosamente os parâmetros do engine, selecionando o tipo de dado adequado e habilitando funcionalidades como prefix caching, eles garantiram que os modelos pudessem lidar com altos volumes de streaming de forma suave.
Juntos, a equipe também criou um framework reutilizável de load testing para encontrar a capacidade de serviço ideal para um servidor de inferência vLLM e traçar seu perfil de performance. Isso permitiu estabelecer uma linha de base para a infraestrutura necessária e ajustar o auto-scaling usando a métrica baseada em contagem de requisições. Além disso, identificaram que uma nova métrica usando vLLM number of requests waiting poderia ser ainda mais eficaz.
Quais desafios a Trustpilot enfrentou?
Durante a construção, alguns obstáculos merecem destaque:
- Rede privada: A arquitetura visava o isolamento total via endpoints privados e Private Service Connect, mas isso não foi possível por falta de suporte nativo para comunicação privada direta entre endpoints distintos.
- Observabilidade e confiabilidade dos deployments: Deployments de endpoints podem ser lentos ou opacos, exigindo troubleshooting extra em estados não saudáveis. A Trustpilot segue trabalhando com o product team da plataforma para moldar futuras funcionalidades de observabilidade.
- Escassez de GPUs: Conseguir GPUs A100 na região europeia é difícil; VMs on-demand muitas vezes não estão disponíveis. Reservas são preferíveis, mas equilibrá-las entre desenvolvimento, produção, treinamento, inferência e experimentos é um grande desafio.
Resultados obtidos
Em parceria com o Google Cloud, a Trustpilot aproveitou todo o potencial do Gemma no Gemini Enterprise Agent Platform para processar milhões de reviews por dia em tempo real. Com isso, alcançou performance similar à do Gemini por uma fração do custo. Isso permitiu que a Trustpilot Business Platform transformasse milhões de reviews de clientes em insights instantâneos e acionáveis. Mais detalhes podem ser lidos no post do Medium da Trustpilot.
Artigo originalmente publicado por Assulan Nurkas (Trustpilot) em Cloud Blog.
Perguntas Frequentes
- Por que a Trustpilot optou por fine-tune de modelos abertos em vez de APIs fechadas?
Para ter total independência sobre o ciclo de retraining, evitar surpresas com mudanças de API ou preços por token, e prever custos fixos de infraestrutura. Além disso, modelos abertos permitem incorporar o "diferencial competitivo" da análise de reviews e manter continuidade arquitetural com futuras versões do modelo base. - Quais foram os principais desafios de infraestrutura enfrentados?
Três desafios se destacaram: a falta de suporte nativo para comunicação privada direta entre endpoints (Private Service Connect), lentidão e opacidade nos deployments que dificultam observabilidade, e a escassez de GPUs A100 na região europeia, exigindo reservas e balanceamento cuidadoso entre ambientes. - Como a Trustpilot garantiu a performance para processar milhões de reviews em tempo real?
Eles otimizaram o backend vLLM ajustando parâmetros do engine, escolhendo o tipo de dado adequado e ativando prefix caching. Também criaram um framework de load testing para determinar a capacidade ideal de serviço e ajustaram o auto-scaling baseado na métrica de requisições em espera do vLLM. - Que métrica de auto-scaling se mostrou mais eficaz para o pipeline?
Além da métrica tradicional de contagem de requisições, a equipe identificou que a métricavLLM number of requests waiting(número de requisições aguardando) é ainda mais adequada para dimensionar automaticamente os endpoints de inferência. - Qual o resultado prático da arquitetura para o negócio da Trustpilot?
A plataforma passou a processar milhões de reviews por dia em tempo real com performance similar aos modelos Gemini, mas a custo muito menor. Isso permitiu que a Trustpilot transformasse reviews em insights acionáveis instantaneamente, fortalecendo seu diferencial de inteligência de dados.
