

Spanner Graph Algorithms: inteligência de grafos do Google Research nativa no Spanner — análise e impactos para empresas brasileiras
TL;DR: Este artigo analisa o lançamento dos algoritmos de grafos nativos no Spanner Graph, que trazem capacidades de graph mining do Google Research diretamente no banco de dados operacional. A conclusão principal é que empresas brasileiras podem realizar análises estruturais complexas — como detecção de fraudes, entity resolution e recomendação — sem movimentar dados para engines externas, reduzindo custos operacionais e mantendo baixo impacto transacional, com escalabilidade para bilhões de arestas.
Durante o Google Cloud Next, foi anunciada a preview dos algoritmos de grafos com o Spanner Graph, trazendo capacidades de graph mining do Google Research diretamente para dentro do seu banco de dados. Essas funcionalidades permitem extrair insights valiosos de dados conectados de forma mais rápida, econômica e em escala.
Empresas estão cada vez mais usando tecnologias de grafos para descobrir relacionamentos complexos em dados — casos como detecção de fraudes, análise de redes sociais, resolução de entidades e pesquisa em saúde. Algoritmos de grafos (centralidade, detecção de comunidades etc.) são métodos computacionais que quantificam padrões e força das conexões entre entidades. Historicamente, executá-los em escala era desafiador e custoso, exigindo pipelines ETL complexos para soluções analíticas dedicadas ou arriscando a performance transacional do banco de grafos.
A Nuvem Online, como especialista em cloud e dados, reforça que a proposta do Spanner Graph algorithms é justamente atacar workloads corporativos exigentes sem comprometer a performance operacional. A arquitetura oferece:
- Integração estreita com GQL: Invocar algoritmos diretamente usando ISO Graph Query Language (GQL) para análises estruturais sobre seus dados. Ao combinar algoritmos e queries padrão sequencialmente, o Spanner Graph minimiza a movimentação de dados para engines externos, simplificando a arquitetura e acelerando o tempo até o insight.
- Impacto transacional próximo de zero e menor TCO: A execução dos algoritmos ocorre em recursos de computação dedicados, sem afetar o tráfego de produção. O Spanner provisiona recursos automaticamente e roteia dados de forma segura via Data Boost, sem criar pipelines ETL customizados. Você paga apenas pelo que usa, evitando licenciamento caro e overhead operacional de soluções legadas.
- Insights globais em grafos com bilhões de arestas em minutos: Construído para escala e velocidade, o engine consegue executar algoritmos em grafos com dezenas de bilhões de arestas em minutos. A codificação de topologias em formato denso otimizado para acesso aleatório permite análises estruturais de alta performance em datasets massivos.
Embora o Google Research já tenha publicado diversos papers, realizado workshops e lançado projetos open-source baseados em suas ferramentas de graph mining (ex.: clustering multi-core), esta é a primeira vez que essas capacidades ficam amplamente disponíveis para clientes Google Cloud. Vamos aprofundar nos algoritmos e em como usá-los com Spanner Graph.
Como os algoritmos de grafos entregam insights mais profundos para dados conectados?
Quando lançamos Spanner Graph, o objetivo era reimaginar o gerenciamento de dados de grafos com uma experiência nativa de banco de grafos dentro do Spanner, o banco de dados distribuído altamente escalável do Google. Spanner Graph unifica modelos relacionais e de grafos, permitindo consultar dados conectados usando ISO GQL, interoperando com as capacidades tabulares, de busca e vetoriais do Spanner. Isso permite construir aplicações inteligentes sem criar pipelines complexos, duplicar dados ou aumentar riscos de segurança e governança.
Com essa base, os algoritmos Spanner Graph ajudam a extrair insights ainda mais profundos dos dados conectados. Eles analisam relacionamentos e conexões, revelando padrões ocultos que métodos analíticos tradicionais podem perder. Com este lançamento, você pode analisar conectividade para, por exemplo, detectar anéis de fraude, realizar clustering para resolução de entidades, identificar pontos de falha em redes complexas ou recomendar produtos com base nas preferências de usuários conectados.
Usamos grafos extensivamente no Google. Na verdade, algoritmos populares como PageRank, tecnologia fundamental do Google Search, foram inventados aqui. Com suporte nativo a algoritmos no Spanner Graph, estamos trazendo algumas das principais capacidades de inteligência de grafos do Google diretamente para clientes Google Cloud, com um conjunto essencial de algoritmos:
- Centralidade: Identificar os nós mais influentes e centrais na rede usando betweenness centrality, closeness centrality e PageRank.
- Detecção de comunidades: Agrupar automaticamente entidades altamente conectadas para revelar segmentos ocultos com label propagation, correlation clustering, modularity clustering, weakly connected components e clique aggregator.
- Similaridade e path finding: Encontrar rotas ótimas com set-to-set shortest paths, ou medir similaridades entre nós usando Jaccard, cosseno, common neighbors e total neighbors.
Experiência integrada para o desenvolvedor: como invocar algoritmos diretamente no GQL?
Você pode invocar os algoritmos de grafos diretamente usando GQL em todo o grafo, subgrafos ou um conjunto selecionado de nós e arestas. O Spanner oferece um workflow integrado: resultados das execuções podem ser escritos de volta no Spanner Graph, permitindo encadear algoritmos e queries padrão sequencialmente, usando a saída de uma operação como entrada da próxima. Também é possível armazenar resultados em buckets do Cloud Storage.
Exemplo prático: desmascarando o líder de uma rede fraudulenta
Considere um cenário de análise de transações financeiras para combater lavagem de dinheiro. Fraudadores geralmente manipulam contas “laranja” (intermediárias) que interagem entre si para cometer fraudes. Para capturar o trabalho em equipe entre contas detectadas e ocultas, especialistas antifraude recorrem à análise de links e algoritmos de detecção de comunidades. Veja como usar algoritmos e consultas juntos no Spanner Graph para capturá-los.
Passo 1: Identificar comunidades de contas (algoritmo)
Primeiro, aplicamos um algoritmo de modularity clustering para agrupar contas em comunidades. Em seguida, escrevemos o community_id resultante de volta na tabela Account no Spanner Graph.
-- Runs community detection and update results to the graph
EXPORT DATA OPTIONS(
format ='CLOUD_SPANNER',
table = 'Account',
write_mode = 'update_ignore_all'
) AS
GRAPH FinGraph
CALL ModularityClustering(
node_labels => ['Account'],
edge_labels => ['Transfer']
)
YIELD node, cluster
RETURN node.id, cluster AS community_id;
Passo 2: Identificar a comunidade suspeita (query)
Agora que toda conta pertence a uma comunidade, usamos uma consulta GQL para analisar cada comunidade e descobrir comportamentos anômalos. Por exemplo, verificar o total de contas fraudulentas conhecidas dentro de cada comunidade.
-- Finds the community with the highest concentration of flagged fraud
GRAPH FinGraph
MATCH (a:Account)
WHERE a.community_id IS NOT NULL
AND a.fraud_flag = TRUE
RETURN a.community_id AS community_id, COUNT(*) AS fraud_count
ORDER BY fraud_count DESC;
Passo 3: Calcular influência para encontrar o “líder” (algoritmo em subgrafo)
Suponha que a consulta acima revele que a Comunidade 2 tem um pico massivo de atividade fraudulenta. Neste passo, filtramos o grafo para isolar apenas as contas dessa comunidade e executamos o algoritmo PageRank para encontrar o líder central dentro desse grupo.
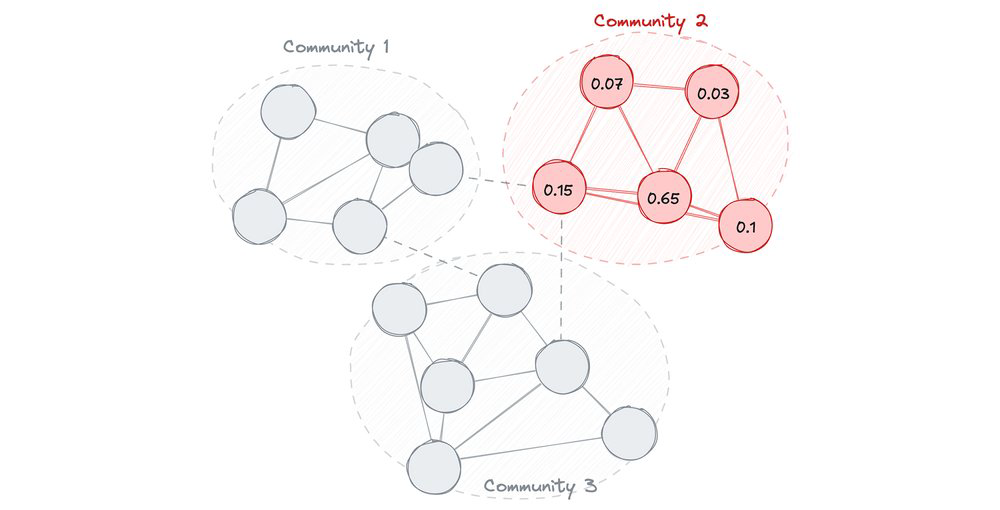
EXPORT DATA OPTIONS(
format = 'CLOUD_SPANNER',
table = 'Account',
write_mode = 'update_ignore_all'
) AS
-- Specifies a suspicious subgraph
GRAPH FinGraph
MATCH (n:Account {community_id: 2})
RETURN n
FULL UNION ALL
MATCH -[e:Transfer]->
RETURN e
NEXT
-- Runs PageRank
CALL PER() PageRank(max_iterations => 20)
YIELD node, score
RETURN node.id, score AS pagerank_score;
Passo 4: Investigar o alvo (query)
Agora que as contas da Comunidade 2 têm um pagerank_score, escrevemos uma consulta que isola a conta mais central e rastreia imediatamente para onde esse líder transferiu fundos recentemente.
-- Finds the top scorer (ringleader) and trace their money
GRAPH FinGraph
MATCH (ringleader:Account {community_id: 2})
ORDER BY ringleader.pagerank_score DESC
LIMIT 1
WITH ringleader
MATCH (ringleader)-[e:Transfer]->{1, 5}(receiver:Account)
WHERE e.ts > '2025-12-01'
RETURN ringleader.id AS ringleader_id, receiver.id AS receiver_id, e.amount, e.ts;
Ao permitir combinar algoritmos de alta performance com queries GQL padrão, o Spanner Graph elimina a necessidade de mover dados entre bancos operacionais e engines analíticos externos. Essa abordagem unificada simplifica drasticamente a arquitetura de dados e acelera o tempo até o insight.
Confiança de líderes do setor
Clientes como DaVita, Yahoo!, SoundCloud e WPP já estão usando algoritmos Spanner Graph para resolver desafios complexos de dados.
“Leveraging Spanner Graph for our Patient 360 initiative has allowed us to consolidate complex healthcare data into a single, unified view. The addition of native graph algorithms like community detection and centrality is a major step forward, enabling us to uncover deep insights within our patient networks faster and at scale. These fully managed capabilities allow our team to focus on driving innovation in patient care without the operational burden of managing complex data pipelines.” — Sam Ghosh, Chief Enterprise Architect at DaVita Kidney Care
“Operating at global scale across Yahoo’s iconic consumer properties requires us to unify billions of user profiles into a single, real-time view. With Spanner Graph, we’ve modeled our Unified User Profile (UUP) as a graph, bringing together previously distributed systems into a centralized source of truth. The addition of fully managed graph algorithms on Spanner further accelerates our ability to deliver personalization at scale. By leveraging algorithms such as community detection and PageRank, we can drive deeper audience segmentation and power more relevant, engaging user experiences across our platform.” — Chris James, Director of Engineering, Yahoo
“With 500+ million tracks from 40+ million artists across 190+ countries, SoundCloud is where emerging artists find their sound, hidden gems are discovered, and music culture is shaped in real time. We have been running graph algorithms in batch mode for years, with processes often taking multiple hours on custom clusters to analyze our massive, multi-billion-edge music graph. The launch of Spanner Graph algorithms is a true game-changer: It not only provides the massive scalability we need, but also allows us to move away from complex custom Python workflows to a fully managed service. Most importantly, it unlocks the ability to run graph algorithms on our most up-to-date data for use cases like identifying creator hubs and improving recommendations, without requiring complex ETL pipelines or impacting the low-latency transactional workloads running on Spanner today.” — Sergey Chekanskiy, VP of Engineering - Data Foundation, SoundCloud
“We've been eager to leverage advanced graph algorithms for Open Intelligence, our foundational intelligence layer that securely connects trillions of live data points from clients, partners and WPP in a privacy-first way and that is now integrated and powers WPP’s agentic marketing platform, WPP Open. In order to have instant, exploratory access to complex relationships across billions of entities – driving planning, modelling, and experimentation — we need native support for deep graph traversal, structural pattern recognition, and advanced algorithms. Algorithm support on Spanner Graph provides the performance and scalability to tackle our most challenging graph analytics problems without operational overhead or expensive licensing.” — Rob Marshall, Head of Strategy, Data & Intelligence, WPP
Construa aplicações mais inteligentes
Agora, com suporte nativo a algoritmos no Spanner Graph, você pode ir além de travessias básicas de relacionamentos e executar análises estruturais profundas diretamente sobre seus dados transacionais mais recentes. Ao aplicar esses algoritmos clássicos de grafos em escala, você pode desbloquear novas capacidades para suas aplicações empresariais:
- Detecção proativa de fraudes e combate à lavagem de dinheiro: Expor anéis de fraude organizados agrupando automaticamente contas laranja com Community Detection (modularity clustering) e, em seguida, aplicar centralidade (PageRank) para identificar o líder que controla o fluxo ilegal de fundos.
- Customer 360 e entity resolution: Unificar dados fragmentados multicanal em um perfil canônico usando funções de similaridade como Jaccard e detecção de comunidades como label propagation. Esses perfis podem ser enriquecidos para treinamento de ML downstream com features topológicas como PageRank.
- Operações autônomas de rede e digital twins: Modelar sua infraestrutura de TI ou telecom como um gêmeo digital, usando similaridade e path finding (set-to-set shortest path) para identificar vulnerabilidades críticas e prever falhas em cascata.
- Recomendações de produtos hiperpersonalizadas: Ir além de históricos de compra analisando comportamentos mais amplos. Use algoritmos de similaridade (common neighbors) para encontrar preferências sobrepostas e centralidade (personalized PageRank) para surfar as recomendações mais relevantes.
- Supply chain e logística resilientes: Proteger sua cadeia de suprimentos de gargalos ocultos usando centralidade (betweenness centrality) para identificar hubs de distribuição superutilizados e path finding para calcular rotas alternativas eficientes durante disrupções.
- Caça a ameaças de cibersegurança e análise de blast radius: Acelerar a caça a ameaças aplicando detecção de comunidades (correlation clustering) para isolar comunicações anômalas entre máquinas e path finding para rastrear o movimento lateral exato do atacante e o raio de explosão.
- Análise preditiva de churn de clientes: Parar o churn contagioso mapeando grupos de assinantes muito unidos com detecção de comunidades e, em seguida, aplicar centralidade para identificar e atingir influenciadores principais com promoções de retenção antes que o churn se espalhe.
Como começar hoje
Os algoritmos Spanner Graph são suportados nas edições Enterprise e Enterprise+ do Spanner. Para saber mais, veja a documentação ou experimente este codelab. Você também pode assistir a este vídeo para um resumo do suporte a algoritmos de grafos com Spanner Graph.
Perguntas Frequentes
-
O que são algoritmos de grafos e como eles funcionam no Spanner Graph?
São métodos computacionais que analisam conexões entre entidades (como PageRank, detecção de comunidades e similaridade) para revelar padrões ocultos. No Spanner Graph, eles são invocados diretamente via GQL, executados em recursos dedicados (Data Boost) sem impactar tráfego transacional, e os resultados podem ser escritos de volta ao banco ou ao Cloud Storage. -
Quais são os principais casos de uso para empresas brasileiras?
Detecção de fraudes e lavagem de dinheiro (mapeamento de contas laranja), Customer 360 (unificação de perfis), recomendações personalizadas, análise de resiliência em supply chain, e cibersegurança (análise de blast radius). O artigo cita exemplos reais como SoundCloud (música) e DaVita (saúde). -
Como os algoritmos de grafos impactam a performance transacional do Spanner?
O impacto é próximo de zero, pois os algoritmos são executados em recursos dedicados provisionados automaticamente pelo Data Boost, sem ETL para engines analíticos externos. Isso mantém a baixa latência das operações transacionais mesmo durante análises pesadas em grafos com bilhões de arestas. -
Preciso criar pipelines ETL para usar os algoritmos de grafos?
Não. A integração nativa com o Spanner Graph elimina a necessidade de ETLs complexos. Você invoca os algoritmos diretamente sobre os dados já armazenados, e os resultados podem ser persistidos no mesmo banco ou exportados para Cloud Storage, simplificando a arquitetura. -
Quais edições do Spanner suportam os algoritmos de grafos?
Os algoritmos de grafos do Spanner Graph estão disponíveis nas edições Enterprise e Enterprise+ do Spanner. Para começar, basta ter uma instância Spanner com uma dessas edições e consultar a documentação oficial ou o codelab fornecido pelo Google Cloud.
Artigo originalmente publicado por Vahab MirrokniVP, Google Fellow, Graph Mining, Google Research em Cloud Blog.
