

TL;DR: A AWS lançou os modelos GPT-5.5 e GPT-5.4 da OpenAI, além do agente Codex, no Amazon Bedrock. Para empresas brasileiras, isso significa acesso a modelos de fronteira para coding e agentic workflows sem custos fixos por desenvolvedor, com processamento permanecendo na região escolhida do Bedrock. A latência varia conforme esforço de reasoning e cache; a AWS prioriza workloads steady-state e faz fila de requests em picos de demanda. O CTA consultivo é sobre otimização de custos e governança.
Como já havíamos antecipado no What’s Next with AWS 2026, a AWS disponibilizou em disponibilidade geral os modelos OpenAI GPT-5.5, GPT-5.4 e o agente de codificação Codex dentro do Amazon Bedrock. Para times de engenharia no Brasil, isso representa um salto na capacidade de integrar LLMs de fronteira diretamente nas pipelines de desenvolvimento, sem depender de APIs externas ou modelos hospedados fora do ecossistema AWS.
Segundo a OpenAI, os modelos GPT-5.5 e GPT-5.4 são excelentes para coding, reasoning, agentic workflows e trabalho profissional complexo. O GPT-5.5 é voltado para workloads de maior criticidade; o GPT-5.4 busca o melhor price-performance. Ambos são acessados via a API Responses no novo motor de inferência do Bedrock, construído para alta performance, confiabilidade e segurança.
O Codex, por sua vez, é o agente de codificação da OpenAI para desenvolvimento de software orientado por IA. Mais de 4 milhões de desenvolvedores já o utilizam semanalmente para escrever, refatorar, debugar, testar e validar código em bases grandes. Com o GPT-5.5 alimentando a inferência, o Codex introduz uma nova classe de inteligência otimizada para workflows complexos e de longo horizonte. Você pode usar o Codex App, o Codex CLI e integrações com IDEs como Visual Studio Code, JetBrains e Xcode — toda inferência roteada pela API Responses no Amazon Bedrock.
Um ponto crítico para empresas com exigências de residência de dados: todo processamento permanece dentro da região Bedrock selecionada. E o modelo de precificação é por token, sem licenças por seat ou compromissos por desenvolvedor.
Como acessar os modelos GPT-5.5 e GPT-5.4 no Bedrock?
O acesso programático é feito via OpenAI Responses API, usando os endpoints bedrock-mantle pelo SDK da OpenAI ou ferramentas de linha de comando como curl.
Exemplo com Python:
pip install -U openai
Configure as variáveis de ambiente:
export OPENAI_BASE_URL="https://bedrock-mantle.us-east-2.api.aws/openai/v1"
export OPENAI_API_KEY="<BEDROCK_API_KEY>"
export BEDROCK_OPENAI_MODEL_ID="openai.gpt-5.5"
Código Python para chamar o GPT-5.5:
import os
from openai import OpenAI
client = OpenAI(
base_url=os.environ["OPENAI_BASE_URL"],
api_key=os.environ["OPENAI_API_KEY"],
)
response = client.responses.create(
model=os.environ["BEDROCK_OPENAI_MODEL_ID"],
input=[
{
"role": "developer",
"content": "You are a software engineer with excellent AWS cloud knowledge. Be concise and practical.",
},
{
"role": "user",
"content": "Design a distributed architecture on AWS in Python that should support 100k requests per second across multiple geographic regions.",
},
],
reasoning={"effort": "medium"},
text={"verbosity": "low"},
)
print(response.output_text)
Também é possível chamar diretamente com curl:
curl "$OPENAI_BASE_URL/responses" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "openai.gpt-5.5",
"input": [
{
"role": "developer",
"content": "You are a software engineer with excellent AWS cloud knowledge."
},
{
"role": "user",
"content": "Design a distributed architecture on AWS in Python that should support 100k requests per second across multiple geographic regions."
}
],
"reasoning": {"effort": "medium"},
"text": {"verbosity": "low"}
}'
A API Responses é recomendada quando você precisa de multi-turn state gerenciado pelo modelo, ferramentas hospedadas, function tools ou execução em background. Consulte o OpenAI Cookbook para exemplos.
Como usar o OpenAI Codex com GPT-5.5 no Amazon Bedrock?
Baixe o Codex CLI, Codex App ou a extensão para VS Code e configure a inferência via Bedrock. O Codex suporta dois caminhos de autenticação: API Key do Bedrock ou cadeia de credenciais do SDK AWS. Se a variável AWS_BEARER_TOKEN_BEDROCK estiver definida, ela é usada primeiro; caso contrário, o Codex usa a cadeia padrão.
Configure a variável:
export AWS_BEARER_TOKEN_BEDROCK=<your-bedrock-api-key>
Depois, defina a região e o model ID (openai.gpt-5.5, openai.gpt-5.4, openai.gpt-oss-120b ou openai.gpt-oss-20b) no arquivo ~/.codex/config.toml:
model = "openai.gpt-5.5"
model_provider = "amazon-bedrock"
[model_providers.amazon-bedrock.aws]
region = "us-east-2"
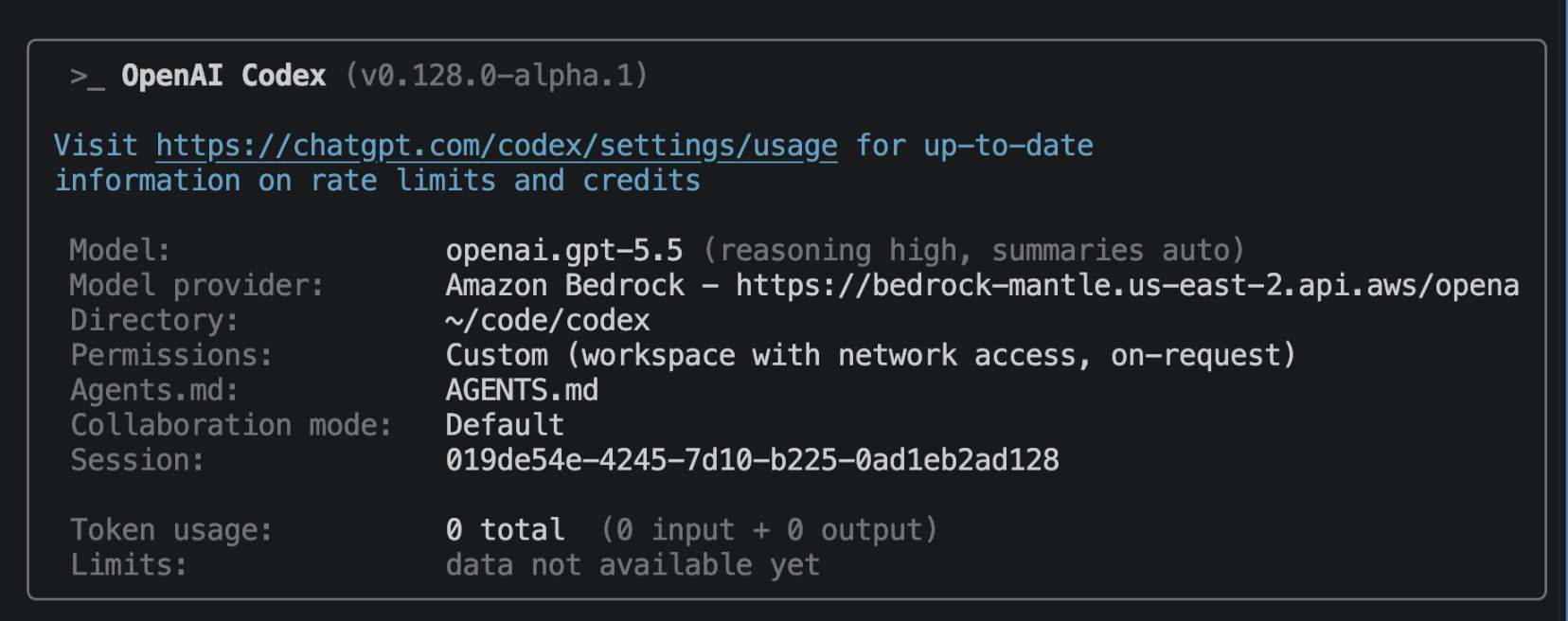
Reinicie o app desktop ou a extensão VS Code após alterar o config. No Codex CLI, a aba /status deve exibir algo como:
No Codex App, você pode usar o GPT-5.5 via inferência do Bedrock:
Pontos de atenção para engenheiros e gestores
Latência: não confie apenas nos rótulos de velocidade
A OpenAI classifica o GPT-5.5 como “rápido” e o GPT-5.4 como “médio”, mas a latência percebida pelo cliente depende de múltiplos fatores: esforço de reasoning, tamanho da saída, chamadas de ferramentas, modo background, região, cotas, throttling, tamanho do prompt e cache hits. Recomenda-se iniciar o GPT-5.5 com effort medium e o GPT-5.4 com effort definido explicitamente — jamais confie no default none.
Capacidade e scaling
O novo motor de inferência do Bedrock foi projetado para provisionar capacidade rapidamente para muitos modelos. A prioridade é manter workloads steady-state rodando. Em picos de demanda, as requisições são enfileiradas, não rejeitadas — o que é um alívio, mas exige planejamento de timeout e retry nas aplicações.
Disponibilidade regional e próximos passos
No momento, o GPT-5.5 está disponível na região US East (Ohio); o GPT-5.4 está em US East (Ohio) e US West (Oregon). A AWS promete expandir — consulte a lista oficial de regiões compatíveis. Para precificação, acesse a página de pricing do Amazon Bedrock.
Teste hoje mesmo o GPT-5.5, GPT-5.4 e o Codex no Amazon Bedrock e envie feedback pelo AWS re:Post ou seus contatos de suporte AWS.
Perguntas Frequentes
-
Quais regiões do AWS estão disponíveis para o GPT-5.5 e GPT-5.4 no Bedrock?
O GPT-5.5 está disponível atualmente na região US East (Ohio). O GPT-5.4 está disponível em US East (Ohio) e US West (Oregon). A AWS promete expandir para outras regiões — consulte a lista oficial de compatibilidade de regiões para futuras atualizações. -
Como funciona a autenticação do Codex com o Amazon Bedrock?
O Codex suporta dois caminhos de autenticação: API Key do Bedrock ou a cadeia de credenciais do SDK AWS. Se a variável de ambiente AWS_BEARER_TOKEN_BEDROCK estiver definida, ela é usada primeiro; caso contrário, o Codex recorre à cadeia de credenciais padrão do SDK AWS. -
Preciso adquirir licenças por desenvolvedor para usar os modelos OpenAI no Bedrock?
Não. O faturamento é por token consumido, sem licenças por seat ou compromissos por desenvolvedor. Isso permite escalar o uso de acordo com a demanda, sem custos fixos, o que é vantajoso para equipes que querem experimentar sem investimento inicial elevado. -
Qual a diferença prática entre GPT-5.5 e GPT-5.4 para uso em produção?
O GPT-5.5 é indicado para workloads mais complexas e de maior exigência, com latência considerada 'rápida' pela OpenAI, mas que na prática depende do esforço de reasoning definido (recomenda-se começar com 'medium'). O GPT-5.4 oferece melhor relação custo-desempenho, com velocidade 'média', e exige que o parâmetro effort seja definido explicitamente para evitar o default 'none'. -
Como a AWS lida com picos de demanda e throttling no Bedrock?
O novo engine de inferência do Bedrock foi projetado para provisionar capacidade rapidamente. A AWS prioriza manter workloads steady-state rodando e escala capacidade conforme a demanda. Em períodos de alta demanda, as requisições são enfileiradas, não rejeitadas, evitando perda de requests.
Artigo originalmente publicado por Channy Yun (윤석찬) em AWS News Blog.
