

TL;DR
O runtime 3.0 do Managed Service for Apache Spark serverless reduz drasticamente a fricção operacional: onboarding zero-setup (IAM, rede e APIs automatizados), startups 75% mais rápidos para workloads sensíveis a SLA, suporte a GPUs via DWS para evitar falta de capacidade, e multi-zona sem custo adicional de tráfego. Para empresas brasileiras que usam Spark para engenharia de features, RAG ou fine-tuning, a mensagem é clara: dá para focar no negócio sem gerenciar clusters.
Do que este artigo trata e por que ele importa para o seu time?
Seja para preparação de dados, consultas interativas em tempo real, treinamento de modelos de IA ou qualquer outra finalidade, executar Apache Spark em escala é exigente — e você não deveria precisar gerenciar a infraestrutura subjacente também.
No fim do ano passado, a Google Cloud anunciou a disponibilidade geral (GA) do runtime 3.0 do serverless Managed Service for Apache Spark, priorizando velocidade, simplicidade e confiabilidade. Desde então, o uso do serviço para data science quase dobrou ano a ano. Isso reforça a percepção de que o Google Cloud é o lugar mais fácil, inteligente e rápido para rodar workloads Apache Spark.
Neste artigo, vamos mergulhar em alguns recursos-chave que tornam a oferta serverless uma boa escolha para uma ampla gama de workflows, incluindo engenharia de features, treinamento e tuning de modelos acelerados por GPU, busca semântica, RAG (Retrieval-Augmented Generation), construção de agentes e aplicações de IA, entre outros.
Zero-setup onboarding: o fim da barreira de entrada
A maior barreira para adotar um serviço em nuvem é frequentemente o "tempo até o momento mágico" — o intervalo entre criar um projeto e executar a primeira workload. Antes, com o Spark serverless, você ainda precisava configurar manualmente papéis IAM, rede VPC e regras de firewall antes de submeter um único job.
No runtime 3.0, o zero-setup onboarding reduz significativamente esse tempo ao automatizar:
- Permissões: Papéis e permissões IAM necessários são provisionados automaticamente para as service accounts apropriadas.
- Rede: Private Google Access é ativado automaticamente nas subnets, e políticas de firewall do sistema são configuradas automaticamente.
- Gerenciamento de APIs: A ativação de APIs agora é mais eficiente: basta habilitar a API Managed Service for Apache Spark, em vez de ativar várias APIs diferentes manualmente.
Fast startup para workloads sensíveis a SLA
Latência importa, especialmente para data science interativo e pipelines batch sensíveis a SLA. Historicamente, os tempos de inicialização do Spark serverless podiam levar vários minutos. Com o runtime 3.0, os tempos de startup caíram 75% nos tiers standard e premium, entregues automaticamente sem alterações de código ou configuração e sem custo adicional.
Essa melhoria massiva qualifica o Spark serverless para uma gama muito maior de workloads sensíveis a SLA, e a equipe continua buscando otimizações adicionais.
"O Spark serverless nos permitiu colher benefícios rapidamente, eliminando a necessidade de gerenciamento granular de máquinas. Isso acelerou o desenvolvimento de modelos e reduziu significativamente nossos custos de processamento de dados." — César Narnajo, Principal Engineer, Moloco

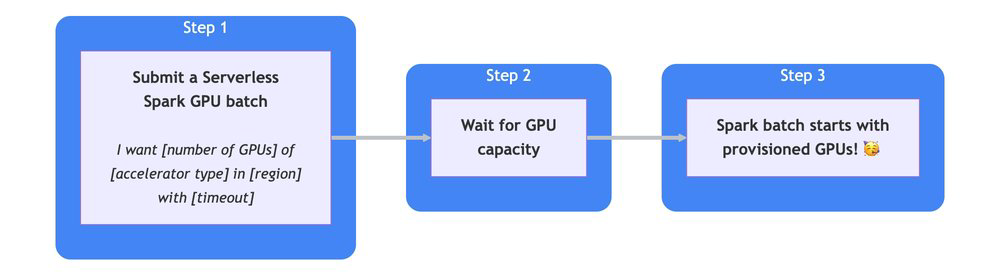
Melhor obtenção de GPUs com Dynamic Workload Scheduler
O suporte ao Dynamic Workload Scheduler (DWS) Flex Start Mode no runtime 3.0 permite que o Spark serverless enfileire requisições de clientes por uma duração configurável quando GPUs estão indisponíveis. Esse recurso enfrenta os desafios de obtenção de aceleradores de alta demanda, como NVIDIA A100 e L4, sujeitos a escassez regional frequente. Ao pausar workloads até que a capacidade necessária de GPU se torne acessível com DWS, você pode aumentar dramaticamente a obtenção e a confiabilidade para seus workloads de IA/ML sensíveis a latência.
Suporte de primeira classe para Apache Spark 4.x
O runtime 3.0 suporta as inovações atuais e futuras do Apache Spark 4.x, incluindo o Spark Connect, que oferece uma arquitetura cliente-servidor desacoplada, permitindo conectividade remota a partir de qualquer cliente.
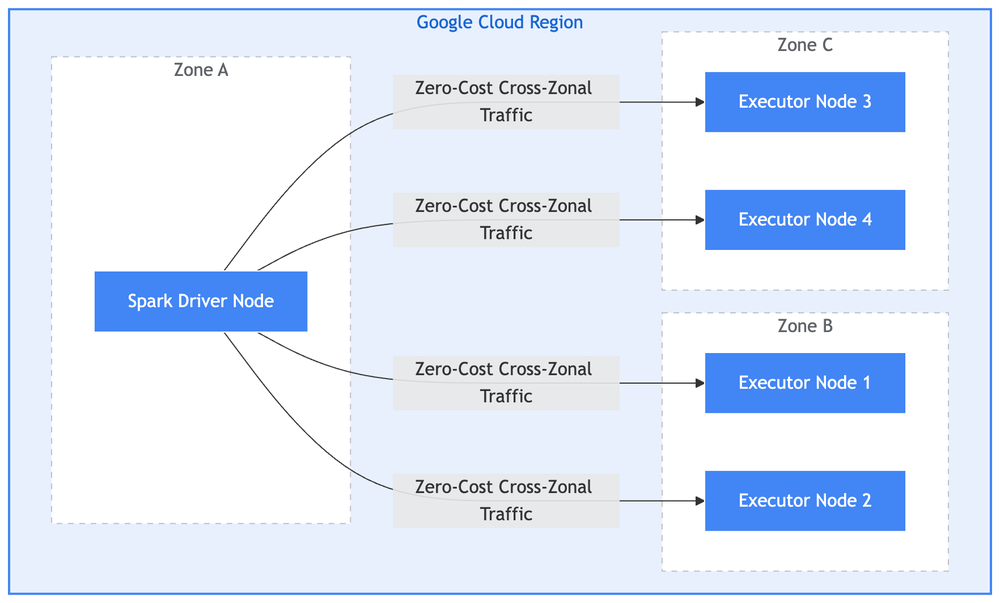
Multi-zonal aprimorado: alta disponibilidade sem custo extra
Para proteger workloads empresariais globais contra falhas zonais ou falta de hardware, o runtime 3.0 introduz suporte multi-zonal aprimorado por padrão. O serviço agora pode alocar automaticamente nós de execução em várias zonas dentro de uma única região para garantir a obtenção.
Crucialmente, a Google Cloud não cobra pelo tráfego de rede cross-zonal entre nós em uma região, proporcionando alta disponibilidade sem o tradicional imposto multi-zona. Esse é outro benefício que você pode obter ao trazer seus workloads globais de Apache Spark para o Google Cloud.
Olhando adiante
Além do que foi mencionado, a Google Cloud continua inovando e expandindo os limites da facilidade de uso em áreas como autotuning baseado em histórico e autoscaling baseado em objetivos.
Comece hoje
Você pode aproveitar esses recursos agora especificando runtime_version: 3.0 em suas workloads batch ou sessões interativas. Para executar sua primeira workload no Spark serverless, siga estes passos simples:
- Habilite a API Managed Service for Apache Spark.
- Se você não for o proprietário do projeto, peça ao administrador para conceder o papel de Editor (
roles/dataproc.serverlessEditor) no projeto.
Agora você está pronto para começar a executar suas workloads no runtime 3.0. Para mais detalhes, visite a documentação atualizada e acesse o Managed Service for Apache Spark no console do Google Cloud.
Perguntas Frequentes
-
O que significa 'zero-setup onboarding' na prática para um time de dados?
Antes, era necessário configurar IAM, VPC, firewall e várias APIs manualmente. Agora o runtime 3.0 provisiona automaticamente permissões, ativa Private Google Access nas subnets e unifica a ativação da API do Managed Service. Isso corta o tempo do primeiro job de horas para minutos. -
Como a redução de 75% no startup time impacta workloads interativos?
Para sessões interativas de data science e pipelines batch com SLA apertado, a latência de inicialização caía de vários minutos para segundos. Isso viabiliza cenários antes inviáveis, como queries ad-hoc em grandes volumes e re-treinos rápidos, sem precisar manter clusters ociosos. -
O Dynamic Workload Scheduler (DWS) realmente resolve o problema de falta de GPUs?
Sim. O DWS Flex Start Mode enfileira workloads quando GPUs como A100 ou L4 estão indisponíveis na região. O job é executado automaticamente assim que há capacidade, aumentando a taxa de sucesso para treinamento e tuning de modelos sem intervenção manual. -
A alta disponibilidade multi-zona realmente não custa mais caro?
Segundo o anúncio, o tráfego cross-zonal entre nós dentro de uma região não é cobrado. Isso elimina o 'multi-zone tax' tradicional, oferecendo resiliência contra falhas de zona sem impacto no orçamento de rede — um diferencial competitivo importante para workloads globais.
Artigo originalmente publicado por Bhooshan MogalSenior Product Manager em Cloud Blog.
