

TL;DR: Este artigo analisa as novas capacidades de processamento de dados do Foundry IQ (Azure AI Search) em preview: indexação expandida do SharePoint (páginas ASPX, listas, subsites), extração aprimorada com Content Understanding (chunking semântico, descrições de imagens) e image serving para recuperação multimodal. Conclusão: essas melhorias no pipeline de dados reduzem engenharia customizada e aumentam a qualidade do grounding em sistemas RAG empresariais.
Respostas excelentes começam antes da recuperação. Elas dependem de quão bem seu pipeline de dados consegue acessar conteúdo corporativo, preservar a estrutura do documento e carregar contexto textual e visual para o índice. Como parte da plataforma Microsoft Foundry, a versão 2026-05-01-preview do Foundry IQ (Azure AI Search) foca exatamente nessa fundação: indexação mais ampla do SharePoint, extração mais rica com Content Understanding e image serving para recuperação multimodal e agentic.
Muitas limitações em sistemas RAG e agentic retrieval vêm do pipeline de dados. Lacunas na cobertura de conteúdo, perda de estrutura documental e ausência de contexto visual impactam diretamente o grounding e a qualidade das respostas. Esta release ataca esses gargalos para que desenvolvedores e equipes de plataforma construam sistemas de retrieval mais confiáveis e prontos para produção com menos engenharia customizada.
O que há de novo?
- Indexação do SharePoint mais abrangente com atualizações no indexador (em preview)
- Melhor compreensão e extração de documentos com integração do Content Understanding em Foundry Tools (em preview)
- Disponibilização de imagens incorporadas em documentos durante recuperação agentic com image serving
Essas novas capacidades são expostas por meio de capacidades de indexação nativas e de knowledge sources. O foco é prático: tornar mais conteúdo corporativo utilizável, preservar mais o significado original do documento e dar aos agentes acesso a evidências visuais junto com o texto. A release também destaca capacidades relacionadas que agora estão em GA na API de abril de 2026.
Como a indexação do SharePoint foi expandida?
Muitas organizações dependem do SharePoint para armazenar páginas de intranet, comunicados, listas operacionais, conteúdo de equipe e documentos. No entanto, pipelines de IA para retrieval tradicionalmente focam em bibliotecas de documentos, deixando páginas e listas subutilizadas.
Com a API 2026-05-01-preview, o SharePoint indexer adiciona suporte para páginas ASPX modernas e SharePoint Lists, além de bibliotecas de documentos. Também inclui descoberta recursiva de subsites e rastreabilidade da URL original.
Isso expande a superfície de conhecimento corporativo disponível para sistemas de retrieval. Um assistente de suporte pode usar listas operacionais, um assistente de funcionário pode referenciar conteúdo de intranet e workflows de negócio podem recuperar de páginas, arquivos e dados estruturados por meio de uma única camada de retrieval. Também reduz a configuração manual e preserva links para o conteúdo original.
Exemplo: SharePoint ASPX and Lists
Como o Content Understanding melhora a extração de documentos?
Uma limitação comum em sistemas RAG é a perda de estrutura durante a ingestão. Tabelas, layout e ordem de leitura são frequentemente achatados, o que reduz a qualidade das respostas.
Foundry IQ agora suporta semantic chunking e descrições de imagens geradas por IA em preview, por meio da integração com Content Understanding em Foundry Tools.
Semantic chunking respeita a estrutura do documento para produzir segmentos de conteúdo mais coerentes. As descrições de imagens convertem gráficos, diagramas e outros elementos visuais em texto recuperável.
Definir a propriedade contentExtractionMode como standard em indexed knowledge sources baseadas em arquivo (Azure blob, SharePoint, OneLake) ativa a funcionalidade no pipeline de ingestão. Isso é especialmente útil para PDFs complexos onde a estrutura importa.
Essas atualizações melhoram como o conteúdo é preservado antes da indexação, resultando em grounding mais forte em diferentes cenários.
Como o image serving permite recuperação multimodal?
Documentos corporativos frequentemente contêm informações importantes em imagens, como diagramas, gráficos, screenshots e formulários escaneados. A recuperação baseada apenas em texto pode perder ou deturpar esse conteúdo.
Image serving preserva imagens extraídas durante a ingestão e as disponibiliza no momento da recuperação. Isso permite que modelos raciocinem sobre conteúdo visual junto com o texto.
Por exemplo, um técnico pode interpretar um diagrama de fiação, um analista pode validar um formulário escaneado, e um usuário financeiro pode analisar um gráfico dentro de um relatório. Isso melhora o grounding em cenários onde a informação crítica é visual.
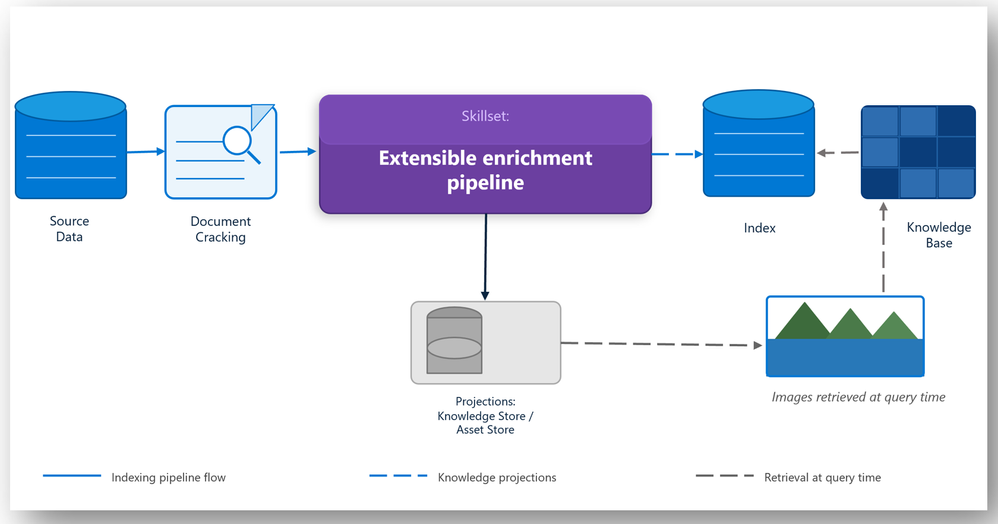
Figura 1 - Fluxo de alto nível do image serving
Exemplo: https://aka.ms/FoundryIQ-data-samples
Outras atualizações relevantes
- Suporte a Azure API Management para skills baseadas em Azure OpenAI no Foundry IQ: GenAI prompt (chat completions) / embedding e vectorizers – incluindo domínio customizado, conectividade de rede privada e managed identities. Permite maior quota de modelo, controle de políticas centralizado, observability e roteamento de tráfego para cenários empresariais com grandes requisitos de escala.
- Conectividade privada para comunicação Search-to-model: permite comunicação segura com recursos Foundry (tipo de recurso
Microsoft.CognitiveServices/accountse grupofoundry_account). - Novas opções de knowledge source:
- Indexed: File, Azure SQL.
- Remote: Fabric Data Agent, Fabric Ontology, MCP Server e Work IQ.
O que já está disponível em produção (GA): API REST 2026-04-01
A REST API 2026-04-01 inclui as seguintes capacidades agora disponíveis para produção:
- GenAI Prompt skill: permite execução de chat models dentro de pipelines de indexação.
- Content Understanding skill e modo de extração de documentos 'standard' para indexed knowledge sources: melhora a extração sensível a layout e o tratamento de tabelas para cenários complexos.
- Knowledge bases e múltiplas knowledge sources: suporte à recuperação em várias fontes de dados empresariais.
- Markdown parsing modes: melhora a ingestão de documentação e repositórios.
- Atualizações de segurança e governança: Foundry IQ integra-se com capacidades de segurança da Microsoft como SharePoint ACLs, sensitivity labels em múltiplas fontes e private networking.
Veja mais em: https://aka.ms/FoundryIQ-security
O que vem a seguir?
Perguntas Frequentes
-
O que muda na indexação do SharePoint com essa preview?
O indexador agora suporta páginas ASPX modernas e SharePoint Lists, além de bibliotecas de documentos. Também inclui descoberta recursiva de subsites e rastreabilidade da URL original, ampliando o conteúdo empresarial disponível para sistemas de retrieval. -
Como o semantic chunking beneficia sistemas RAG?
O semantic chunking respeita a estrutura do documento (tabelas, layout, ordem de leitura) para produzir segmentos mais coerentes, evitando a perda de contexto que ocorre com chunking baseado em caracteres. Isso melhora a qualidade das respostas geradas. -
O image serving é útil apenas para documentos com imagens?
Sim, mas tem grande impacto em cenários onde informações críticas estão em diagramas, gráficos ou formulários escaneados. O image serving preserva as imagens extraídas durante a ingestão e as disponibiliza no momento da recuperação, permitindo que modelos raciocinem sobre conteúdo visual junto ao texto. -
Essas funcionalidades já estão disponíveis para produção?
A maior parte está em preview na API 2026-05-01-preview. A API 2026-04-01, agora GA, inclui o GenAI Prompt skill, Content Understanding skill, knowledge bases e suporte a Markdown parsing, entre outros.
Artigo originalmente publicado por gia_mondragon em Azure Updates - Latest from Azure Charts.
