

Inferência On-Prem em Produção: Foundry Local no Azure Local Ganha Suporte Multi-Node e vLLM
TL;DR: Com as novas capacidades de agendamento multi-node e runtime vLLM, o Foundry Local no Azure Local permite distribuir workloads de inferência por múltiplos GPUs no cluster, suportar alta concorrência de usuários e executar modelos maiores on-premises. A operação desconectada mantém o endpoint funcionando mesmo sem WAN. O catálogo agora inclui modelos como Phi-4, Mistral e Nemotron, com suporte a BYOM. Ideal para indústrias reguladas, soberania de dados e borda.
Desde o anúncio da prévia pública do Foundry Local no Azure Local para single-node, a Microsoft observou forte adoção em indústrias reguladas e demanda consistente para expandir a plataforma com deployments escaláveis. Agora, três novas funcionalidades ampliam onde e como você pode utilizá-lo:
- Agendamento multi-node — distribua workloads de inferência pela capacidade de GPU em todo o cluster Azure Local, não apenas em um único nó.
- Suporte ao runtime vLLM — um motor de serving de alta throughput, projetado para grandes modelos de linguagem e workloads concorrentes.
- Catálogo de modelos expandido — novos modelos disponíveis no formato otimizado vLLM, junto com as ofertas ONNX existentes.
Juntas, essas adições permitem escalar para maior concorrência, servir mais usuários a partir de um único endpoint e executar modelos maiores on-premises. Elas transformam o Foundry Local no Azure Local em uma plataforma de inferência on-premises mais completa e pronta para produção, cobrindo um leque maior de tamanhos de modelo, perfis de concorrência e hardware, enquanto preservam os mesmos padrões Kubernetes-native e compatíveis com OpenAI que você já utiliza.
Por que a operação desconectada é crítica para cenários de borda e soberania?
Foundry Local no Azure Local foi projetado para rodar completamente on-premises, inclusive em ambientes desconectados ou com conectividade intermitente. Os pesos dos modelos, prompts e tráfego de inferência permanecem inteiramente dentro do cluster habilitado por Arc — não há chamada por requisição ao Azure, nem exfiltração de dados para a nuvem, nem dependência de WAN ativa para servir inferência.
- Modelos são cacheados localmente em Persistent Volumes após o primeiro pull. Uma vez cacheados, o endpoint de inferência continua servindo mesmo quando a WAN cai — através de reboots, falhas de rede e operação desconectada prolongada.
- A autenticação por API-key continua funcionando ininterruptamente durante períodos desconectados. A autenticação Microsoft Entra ID retoma perfeitamente quando a conectividade é restabelecida.
- O control plane é local ao cluster: o operador Foundry Local, o catálogo de modelos e os runtimes de inferência vivem dentro do Azure Local — o Arc é usado para gerenciamento de frota e atualizações, não para o data path de inferência.
Para chão de fábrica, plataformas offshore, data centers soberanos, sites classificados e filiais remotas onde a conectividade em nuvem é não confiável, restrita ou proibida, isso é o que torna a inferência de IA on-premises viável em produção.
Como o agendamento multi-node muda o jogo?
Foundry Local no Azure Local agora expande para suportar múltiplos nós em seu cluster. O operador de inferência agenda e gerencia deployments pela capacidade de GPU disponível em todo o cluster, permitindo:
- Capacidade de GPU de qualquer nó do cluster, não apenas os recursos de um único nó.
- Posicionar workloads de inferência onde o hardware está, com o operador gerenciando deployments entre os nós.
O mesmo ModelDeployment que você já usa define o workload, servido através do endpoint padrão compatível com OpenAI (POST /v1/chat/completions). Aplicações existentes funcionam contra deployments multi-node sem nenhuma alteração de código.

Por que o runtime vLLM é essencial para workloads de produção?
Junto com o ONNX-GenAI, o Foundry Local agora oferece vLLM como runtime de inferência de primeira classe. O vLLM é um motor de serving open-source de alta throughput que se tornou o padrão para inferência de LLMs em produção na nuvem. Trazê-lo para o Foundry Local no Azure Local significa que as mesmas características de performance estão disponíveis em seu chão de fábrica, data center soberano ou site remoto.
Por que o vLLM importa para inferência em edge e on-premises
| Capacidade | ONNX-GenAI | vLLM |
|---|---|---|
| Hardware | CPU e GPU | Apenas GPU |
| Throughput | Otimizado para single-user, baixa latência | Otimizado para alta throughput, multi-usuário |
| Gerenciamento de memória | Alocação padrão | PagedAttention — gerenciamento eficiente de KV-cache reduz desperdício de VRAM |
| Continuous batching | Não suportado | Suportado — requisições são agrupadas dinamicamente para maior utilização da GPU |
| FP8 KV cache | Não suportado | Suportado em modelos e GPUs compatíveis — aproximadamente dobra a capacidade de tokens |
| Melhor para | Modelos compactos, nós apenas CPU, cenários single-client | Modelos maiores, workloads multi-usuário, clusters com GPU |
Como o vLLM planner resolve o problema de configuração?
Um dos desafios operacionais com vLLM é o tuning de configuração — definir utilização de memória GPU, tamanho de contexto, batch sizes e outros parâmetros para um dado modelo em um perfil de hardware específico. Errar a configuração faz o pod sofrer OOM ou desperdiçar capacidade da GPU.
Foundry Local resolve isso com o vLLM planner, um componente automático de tuning que inspeciona os recursos GPU disponíveis, analisa o footprint do modelo alvo e gera uma configuração segura para memória e de alta performance antes de o servidor de modelo iniciar. Você declara o modelo que deseja rodar; o planner descobre como rodá-lo otimamente em seu hardware.
A referência completa está na documentação do vLLM planner.

Como a autenticação baseada em identidade funciona para workloads multi-usuário?
Servir mais usuários concorrentes não é apenas um problema de throughput — é também um problema de controle de acesso. Foundry Local suporta dois modos de autenticação lado a lado no mesmo endpoint:
- API keys — chaves primária e secundária por deployment, com rotação sem downtime. Ideal para tráfego service-to-service e pipelines automatizados.
- Microsoft Entra ID com Azure RBAC — acesso por identidade usando o papel
Cognitive Services OpenAI User(ou qualquer papel que conceda ação equivalente no data plane). A validação JWT roda dentro do pod de inferência; a autorização é aplicada através da identidade gerenciada pelo Arc do cluster.
Habilite ambos e os clientes podem apresentar qualquer tipo de credencial no mesmo header Authorization: Bearer — a plataforma detecta qual foi enviada e roteia para o caminho de validação correto. Chamadas com API key continuam funcionando se a conectividade externa for perdida, oferecendo uma degradação natural para sites de borda e desconectados.
Para um assistente de IA multi-usuário no chão de fábrica ou em um data center soberano, isso é a diferença entre uma conta de serviço compartilhada e uma trilha de auditoria por usuário.
Catálogo expandido: ONNX e vLLM lado a lado
O catálogo de modelos do Foundry Local agora inclui modelos nos formatos ONNX e vLLM. Um mesmo modelo pode aparecer várias vezes — uma por runtime/compute target — permitindo escolher a versão que corresponde ao seu hardware sem sair da plataforma. O operador seleciona automaticamente a imagem de contêiner correta com base na entrada referenciada.
Suporte ampliado a modelos abertos
Além das famílias Phi e GPTOSS, o catálogo agora inclui modelos adicionais de várias linhagens open-source solicitados por clientes para deployments on-prem e soberanos, incluindo Mistral e NVIDIA Nemotron. Ambos estão disponíveis como entradas de catálogo, servidos pelo runtime vLLM em GPU e acessíveis pelo mesmo endpoint compatível com OpenAI.

Em colaboração com a NVIDIA, o Foundry Local agora suporta os modelos Nemotron mais recentes, otimizados para performance empresarial em hardware Azure Local com NVIDIA RTX Pro 6000. Modelos Nemotron são ajustados para raciocínio, seguimento de instruções e workflows agentic, rodando no runtime vLLM com PagedAttention, continuous batching e FP8 KV cache em GPUs compatíveis. O vLLM planner lida automaticamente com a utilização de memória GPU e dimensionamento de contexto — você declara a entrada do catálogo, a plataforma dimensiona o deployment para seu hardware.
Modelos disponíveis no formato vLLM
(Consulte a documentação do catálogo para a lista completa e atualizada)
| Modelo | ONNX | vLLM | Notas |
|---|---|---|---|
| Phi-4 | ✓ | ✓ | SLM flagship da Microsoft |
| Phi-4-mini | ✓ | ✓ | Compacto, inferência rápida |
| Phi-4-mini-reasoning | ✓ | ✓ | Raciocínio chain-of-thought |
| Phi-4-reasoning | — | ✓ | Apenas vLLM, foco em raciocínio |
| gpt-oss-20b | ✓ | ✓ | Generativo intermediário |
| gpt-oss-120b | — | ✓ | Generativo grande, apenas vLLM |
| Mistral-7B-v0.2 | ✓ | ✓ | LLM open-source popular |
| DeepSeek-R1 (7b/14b) | ✓ | — | Foco em raciocínio |
| Qwen2.5 (0.5b–14b) | ✓ | — | Multilíngue, variantes de código |
| Qwen3 (0.6b–14b) | ✓ | — | Geração mais recente |
| Whisper (vários tamanhos) | ✓ | — | Fala para texto |
| Nemotron | ✓ (CPU) | ✓ | — |
O catálogo agora inclui uma lista crescente de modelos em ambos os runtimes. Modelos no formato vLLM são servidos pelo engine vLLM com todos os seus benefícios de performance — PagedAttention, continuous batching, FP8 KV cache — enquanto modelos ONNX continuam servindo em CPU ou GPU pelo runtime ONNX-GenAI.
Bring-Your-Own-Model (BYOM)
Quando você precisa de um modelo que não está no catálogo, o BYOM funciona da mesma forma: empacote seu modelo como um artifact OCI em qualquer registry compatível com ORAS (Azure Container Registry, GitHub Container Registry, Docker Hub) e referencie-o a partir de seu ModelDeployment. O operador o cacheia localmente e reutiliza a cópia cacheada em deployments subsequentes.
Escolhendo o runtime certo
- ONNX-GenAI quando você está rodando em hardware apenas CPU, servindo uma única aplicação com um modelo compacto, ou precisa da maior compatibilidade de modelos, incluindo speech e workloads preditivos.
- vLLM quando você tem hardware GPU, precisa servir usuários concorrentes, quer rodar modelos maiores, ou precisa de throughput de produção a partir de seu endpoint de inferência.
Ambos os runtimes expõem a mesma API REST compatível com OpenAI — a escolha é transparente para o código da aplicação.
Um ModelDeployment com vLLM é tão simples quanto:
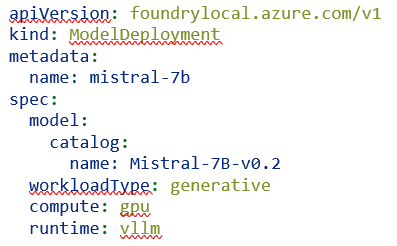
Todo o resto — utilização de memória, tamanho de contexto, batch sizing — é tratado pelo vLLM planner. Consulte a documentação do catálogo para o padrão BYO e opções completas de configuração.
O que não mudou?
Tudo da prévia pública permanece totalmente suportado:
- Dois caminhos de instalação — extensão Azure Arc (recomendada para gerenciamento de frota) e Helm chart (para engenheiros de plataforma que precisam de controle total)
- Endpoints REST compatíveis com OpenAI —
POST /v1/chat/completionse padrões comuns - Autenticação via API key e Microsoft Entra ID — protegida com bearer tokens, com modelo RBAC por identidade
- Ingress habilitado com TLS — tráfego criptografado em trânsito
- Operação desconectada — modelos cacheados em PersistentVolumes continuam servindo quando a conectividade WAN cai
- Modelos preditivos BYO — deploy de modelos ONNX personalizados de registries OCI
- Orquestração multi-modelo — padrões agent-like coordenando múltiplos modelos locais
Seus manifests ModelDeployment existentes continuam funcionando. Aplicações que visam o runtime ONNX-GenAI não precisam de alterações. As novas capacidades são aditivas.

Cenários reais, agora em escala
Nos últimos meses, a Microsoft fez parceria com clientes em prévia para construir e validar cenários reais. Um tema consistente é a necessidade de rodar IA onde os dados residem — on-premises — mantendo a governança e consistência proporcionadas pelo Azure Arc.
"Em operações de energia, a IA precisa rodar onde o trabalho acontece — em instalações remotas, plataformas offshore e locais de campo onde a conectividade é frequentemente limitada e a segurança é primordial. O Foundry Local nos dá um caminho para trazer a tomada de decisão baseada em IA para mais perto de nossos dados operacionais, com a governança que nossa indústria exige. A capacidade de implantar e rodar workloads de IA de forma consistente em ambientes de borda e campo, mesmo quando desconectados, é crítica para avançar a visão da Chevron para operações autônomas e inteligentes."
— Ed Moore, OT Strategist and Distinguished Engineer, Chevron
Com multi-node e vLLM, os cenários da prévia inicial escalam para atender demandas de produção:
Manufatura: inspeção de qualidade multi-usuário
Um sistema de controle de qualidade em uma linha de produção rodava Phi-4-mini para explicação de anomalias em uma única estação. Com o continuous batching do vLLM, o mesmo endpoint do Foundry Local agora atende 10+ estações de inspeção simultaneamente — cada uma enviando imagens de defeitos e telemetria de sensores para análise de causa raiz em tempo real — sem degradação no tempo de resposta.
Soberania: processamento de documentos com escopo por identidade
Uma agência governamental processando casos sensíveis precisa de throughput de produção e trilha de auditoria rigorosa. O Foundry Local serve o workload on-premises em múltiplos nós GPU, com acesso por analista aplicado via Entra ID e Azure RBAC, de modo que toda chamada de inferência é vinculada a uma identidade real — e nenhum dado sai do cluster.
Energia: operações multi-usuário desconectadas
Uma plataforma offshore roda Foundry Local em um cluster Azure Local multi-node. Quando a conectividade WAN cai, o endpoint alimentado por vLLM continua servindo consultas de procedimentos de segurança, orientação de manutenção e perguntas operacionais para múltiplos membros da tripulação simultaneamente — cada um acessando o endpoint de inferência de sua aplicação local. A autenticação por API key continua funcionando durante a interrupção; o Entra ID retoma perfeitamente quando a WAN volta.
Como começar
Se você já está rodando Foundry Local no Azure Local na prévia pública:
- A extensão Foundry Local é mantida automaticamente atualizada, com suporte multi-node e vLLM incluído.
- Navegue pelo catálogo atualizado para descobrir modelos disponíveis no formato vLLM.
- Faça deploy de um modelo vLLM definindo
runtime: vllmem seu manifestModelDeployment. - Deixe o vLLM planner otimizar — sobrescreva apenas as preferências que importam e deixe o planner cuidar do resto.
Se você é novo no Foundry Local no Azure Local:
- Siga o blog de código-sample para começar para ver o fluxo completo.
- Solicite acesso à prévia para começar.
- Leia a documentação para visão geral da arquitetura e guia de deployment.
O que vem a seguir?
Multi-node e vLLM são apenas o começo. A Microsoft continua investindo em:
- LLM serving distribuído com LLM-D — roteamento consciente de KV-cache e serving desagregado para grandes modelos que abrangem múltiplos nós.
- Autoscaling para workloads de inferência — capacidade dinâmica que acompanha a demanda.
- Expansão do catálogo de modelos — mais famílias, tamanhos e tipos de task.
- Monitoramento e observabilidade aprimorados para workloads de inferência.
- Otimização de performance para perfis de hardware específicos do Azure Local.
- Validação expandida de hardware GPU em todo o catálogo Azure Local.
O Foundry Local está sendo construído para ser a plataforma de inferência de IA de produção para ambientes de borda e soberanos. Seu feedback está moldando cada release — continue enviando.
Saiba mais
Para mais informações, entre em contato com a equipe pelo e-mail [email protected].
Perguntas Frequentes
-
O que é o vLLM e por que ele é importante para inferência on-premises?
O vLLM é um runtime open-source de alta throughput para serving de LLMs, agora integrado ao Foundry Local. Ele oferece PagedAttention, continuous batching e FP8 KV cache, que juntos aumentam significativamente a concorrência e a utilização da GPU, permitindo servir múltiplos usuários simultaneamente em cenários de borda e soberania. -
Como funciona a operação desconectada do Foundry Local?
O Foundry Local foi projetado para rodar completamente on-premises, mesmo sem conectividade com a nuvem. Os modelos são cacheados em Persistent Volumes locais e continuam servindo inferência mesmo em quedas de WAN, reboots e desconexões prolongadas. A autenticação via API key segue funcionando sem interrupção. -
Quais modelos estão disponíveis no catálogo expandido?
O catálogo agora inclui modelos nos formatos ONNX e vLLM, como Phi-4, Phi-4-mini, Phi-4-reasoning, Mistral-7B, DeepSeek-R1, Qwen, Whisper e Nemotron (em parceria com a NVIDIA). Muitos modelos estão disponíveis em ambos os runtimes, permitindo escolher o melhor para seu hardware. -
Como funciona o autotuning do vLLM planner?
O vLLM planner é um componente automático que inspeciona os recursos de GPU disponíveis, analisa o footprint do modelo e gera uma configuração otimizada e segura para memória antes de iniciar o servidor. Você declara qual modelo quer rodar e o planner decide como executá-lo de forma eficiente. -
Como implementar multi-node scheduling no Foundry Local?
Basta usar o mesmo custom resource ModelDeployment que você já utiliza. O operador de inferência agora agenda e gerencia deployments através de múltiplos nós no cluster, distribuindo a capacidade de GPU. A API permanece compatível com OpenAI, sem necessidade de alterações no código da aplicação.
Artigo originalmente publicado por liranlyabock_microsoft em Azure Updates - Latest from Azure Charts.
