

TL;DR: Este guia prático mostra como, em cerca de 10 minutos, você sai de um cluster Kubernetes com o Foundry Local instalado a um endpoint OpenAI‑compatível servindo inferência de modelos como Phi‑4 (CPU) ou Mistral (GPU via vLLM). O operador gerencia todo o ciclo de vida do deployment, desde o pull da imagem até a geração da chave de API. Para empresas brasileiras, a principal vantagem é executar inferência de modelos de IA on‑premises, reduzindo latência, evitando dependência exclusiva da nuvem pública e atendendo requisitos de conformidade (LGPD, setor financeiro). O mesmo fluxo serve para ambientes de teste, CI/CD e automação com GitOps.
Foundry Local on Azure Local está em preview pública no momento desta análise.
Você instalou o Foundry Local no seu cluster Azure Local. Os pods do operador estão rodando, os CRDs foram registrados, você já verificou com kubectl get pods. E agora?
Este artigo cobre exatamente a etapa que vem antes de tudo isso — o padrão de ciclo de vida que você usará para implantar qualquer modelo no Foundry Local no Azure Local. O anúncio recente aborda o quadro geral: inferência multi‑node, vLLM como runtime de primeira classe junto com ONNX‑GenAI e um catálogo expandido. Manteremos este guia em single‑node para clareza, mas o mesmo padrão ModelDeployment escala sem alterações no seu código cliente ou workflow.
Ao final deste guia, você terá ido de um prompt kubectl vazio a um endpoint de inferência funcional compatível com OpenAI servindo Phi‑4. Tudo em cerca de dez minutos, usando apenas kubectl, Python e um pequeno script de exemplo. Mostraremos também como mudar para o novo runtime vLLM alterando aproximadamente cinco linhas de YAML.
Todo o código está em Azure-Samples/foundry-local-model-catalog. Clone e acompanhe.
O que você vai construir?
O exemplo percorre cinco etapas, cada uma acionada pelo mesmo script Python com flags diferentes:
- Consultar o catálogo de modelos – ler o ConfigMap que o operador sincroniza da API do catálogo Microsoft Foundry.
- Implantar um modelo – criar um recurso personalizado
ModelDeploymentapontando para uma entrada do catálogo. - Aguardar o status ready – o operador baixa a imagem do modelo, agenda os pods e reporta o estado.
- Executar inferência – chamar o endpoint compatível com OpenAI
/v1/chat/completionscom uma chave de API gerada pelo operador. - Limpar – deletar o deployment.
As mesmas cinco etapas se aplicam esteja você servindo um modelo ONNX em um nó CPU ou um modelo vLLM em um nó GPU. Começaremos com o caminho mais simples: Phi‑4 em CPU no runtime ONNX e, no final, mostraremos a variante vLLM.
O que você precisa antes de começar?
Você precisará de:
- Um cluster Azure Local (ou qualquer cluster Kubernetes habilitado para Arc) com a extensão Foundry Local instalada. Se ainda não configurou, o guia de instalação do Foundry Local no Azure Local aborda os requisitos de cluster, extensão e recursos.
kubectlconfigurado contra esse cluster, com permissões para ler ConfigMaps e Secrets e criar recursosModelDeploymentno namespacefoundry-local-operator.- Python 3.9 ou superior.
Verifique se o operador está ativo antes de prosseguir:
kubectl get pods -n foundry-local-operator
kubectl get crd | grep foundry
Você deve ver pods do operador em estado Running e pelo menos um CRD chamado modeldeployments.foundrylocal.azure.com. Caso contrário, volte ao guia de instalação.
Em seguida, clone e instale:
git clone https://github.com/Azure-Samples/foundry-local-model-catalog.git
cd foundry-local-model-catalog
python3 -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt
Etapa 1 – Como consultar o catálogo?
Comece com o comando de menor risco no exemplo — ele consulta o cluster, mas não altera nada:
python catalog_sample.py --catalog-only
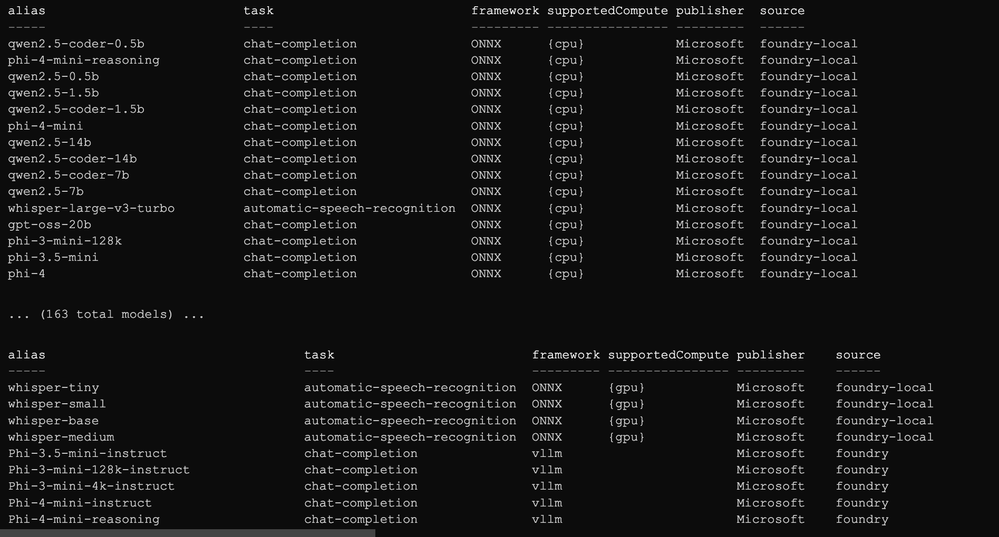
Alguns pontos para observar na tabela:
- A maioria dos modelos aparece mais de uma vez. O mesmo modelo é empacotado para diferentes combinações de runtime/hardware, e o operador escolhe a imagem de container correta com base na entrada que você referenciar.
- Existe uma coluna
RUNTIME. Voltaremos ao vLLM no final deste artigo; por ora, a entrada padrãoPhi-4-generic-cpu(ONNX) é a que vamos implantar. - O catálogo em si é apenas um ConfigMap. Sem mágica, sem registry oculto. O operador sincroniza da API do catálogo Microsoft Foundry via um CronJob, e o exemplo o lê da mesma forma que você faria:
kubectl get configmap foundry-local-catalog -n foundry-local-operator -o yaml
Se você ficar na dúvida sobre o que está realmente disponível no seu cluster, essa é a fonte da verdade.
Etapa 2 – Como implantar o modelo?
Agora a parte com efeitos colaterais. Vamos pedir ao operador que implante o Phi‑4 em CPU:
python catalog_sample.py --deploy-only
Por baixo dos panos, o exemplo constrói e aplica um manifesto ModelDeployment como este:
apiVersion: foundrylocal.azure.com/v1
kind: ModelDeployment
metadata:
name: phi-4-generic-cpu
namespace: foundry-local-operator
spec:
model:
catalog:
name: Phi-4-generic-cpu
workloadType: generative
compute: cpu
replicas: 1
port: 5000
O operador assume o controle a partir daí. Ele baixa a imagem do modelo, agenda um pod, gera um Secret com a chave de API chamado phi-4-generic-cpu-api-keys e percorre os estados Pending → Creating → Running. O exemplo faz polling até que status.state == Running e status.deploymentReady == true.
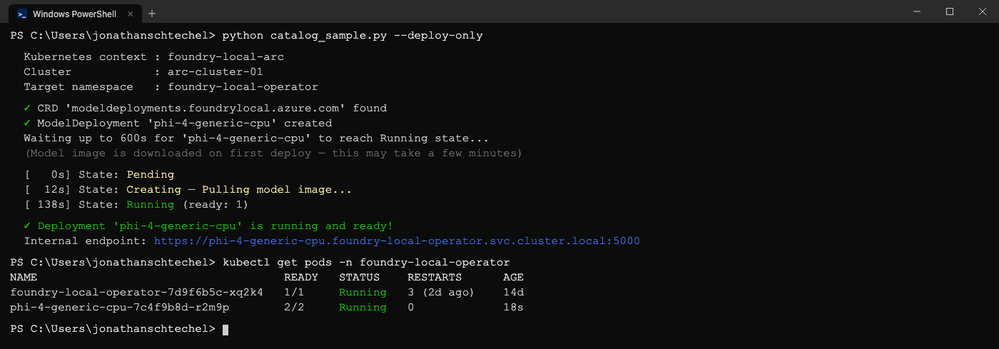
Atenção! O primeiro deployment de um modelo baixa a imagem, o que pode levar alguns minutos dependendo do tamanho do modelo e da velocidade da rede. A imagem fica cacheada em um PersistentVolume, então o segundo deploy do mesmo modelo é muito mais rápido.
Etapa 3 – Como executar a inferência?
O endpoint está no ar. Hora de usá-lo.
Se você estiver executando este script de dentro do cluster (por exemplo, de um pod de debug), o endpoint fica no DNS do serviço interno e o exemplo o detecta automaticamente. A maioria dos leitores, porém, estará executando de um laptop — então vamos cobrir esse caminho explicitamente.
Em um terminal, faça port‑forward do serviço do deployment:
kubectl port-forward svc/phi-4-generic-cpu 5000:5000 -n foundry-local-operator
Em outro terminal, execute o modo de inferência do exemplo contra o endpoint encaminhado:
python catalog_sample.py --infer-only \
--endpoint https://localhost:5000 \
--insecure
O exemplo lê a chave de API do Secret gerado automaticamente e a envia como Authorization: Bearer <key> — mesmo padrão da OpenAI em nuvem.
Atenção! A flag
--insecureignora TLS auto‑assinado. Junto comkubectl port-forward, isso é uma configuração de smoke test. Para tráfego real, exponha o deployment via Ingress ou LoadBalancer.
O corpo da requisição segue o formato padrão de chat‑completions da OpenAI:
{
"model": "Phi-4-generic-cpu:1.0.0",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is the capital of France? Reply in one sentence."}
],
"max_tokens": 256
}
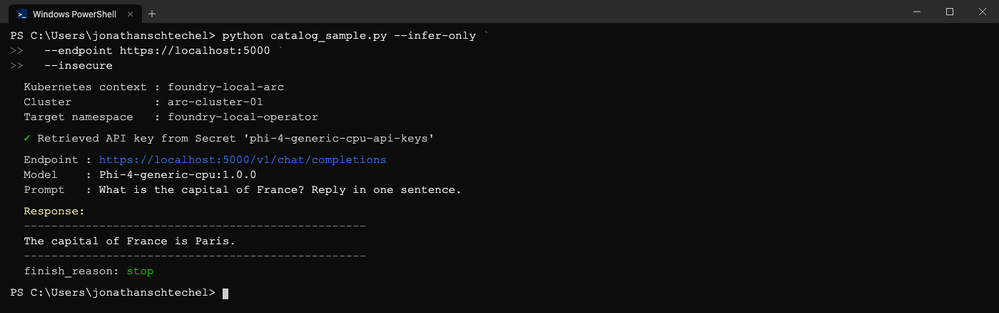
Essa resposta viajou do seu terminal, passou pelo kubectl port-forward, chegou a um modelo servindo dentro do seu cluster Azure Local e voltou.
Etapa 4 – Como limpar?
O fluxo padrão do exemplo deleta o deployment ao sair — se você executou o python catalog_sample.py completo (sem flags), já está limpo. Se usou --deploy-only ou --skip-cleanup, delete explicitamente:
kubectl delete modeldeployment phi-4-generic-cpu -n foundry-local-operator
O operador coleta o pod, o serviço e o Secret de chave de API. A imagem do modelo cacheada permanece no PersistentVolume, então o próximo deploy do mesmo modelo pula o download.
Indo além da CPU: vLLM em 5 linhas
Agora a variante para a qual estávamos apontando. O mesmo CR ModelDeployment, o mesmo endpoint compatível com OpenAI, agora com um runtime construído para usuários concorrentes, demonstrado em um modelo open‑source popular.
O diff em relação ao manifesto da Etapa 2:
spec:
- compute: cpu
+ compute: gpu
+ runtime: vllm
model:
catalog:
- name: Phi-4-generic-cpu
+ name: Mistral-7B-v0.2
O mesmo script de exemplo lida com isso:
python catalog_sample.py \
--model Mistral-7B-v0.2 \
--compute gpu \
--runtime vllm
O que você recebe de volta é o mesmo endpoint compatível com OpenAI que seu código cliente já conhece, mas agora apoiado pelo PagedAttention do vLLM, continuous batching e configuração ajustada automaticamente pelo planner. Seu código de aplicação não precisa saber nada disso; continua sendo POST /v1/chat/completions com um Bearer token.
Essa é a razão de ser do padrão de ciclo de vida: ONNX ou vLLM, CPU ou GPU, o loop de deployment do engenheiro de plataforma é o mesmo.
O que você construiu?
Há dez minutos você tinha um cluster Foundry Local instalado, mas vazio. Agora você tem:
- Um endpoint de chat compatível com OpenAI funcional servindo Phi‑4.
- Uma compreensão clara do que o operador gerencia para você (CR
ModelDeployment, cache de imagem do modelo, Secret de chave de API) e o que fica nas suas mãos (qual modelo, qual runtime, qual destino de computação). - Um script pequeno e modular que pode ser conectado a:
- Um teste de smoke para cada novo cluster que você levantar (
--catalog-only→--deploy-only→--infer-onlyé uma etapa de CI de uma linha). - Uma demonstração interna quando você precisar mostrar a um time que o Foundry Local no Azure Local é real e acessível.
- A base para sua própria automação de deployment – copie o construtor de manifesto, remova a CLI e conecte‑o à sua ferramenta GitOps ou de plataforma existente.
- Um teste de smoke para cada novo cluster que você levantar (
Do endpoint à interface de chat
O deployment de modelo acima expõe uma API padrão compatível com OpenAI – suficiente para qualquer cliente de chat existente apontar. Se você quiser ver exatamente isso, Azure-Samples/local-chat-with-foundry-local continua de onde este guia termina: ele conecta o endpoint em execução à UI inicial do Sovereign Chat Experience. Mais cerca de dez minutos para ir de endpoint funcional a um chat funcional no navegador.
Próximos passos
- Experimente o restante do exemplo:
--catalog-only,--deploy-only,--infer-onlye--skip-cleanupse combinam em qualquer workflow que você esteja testando. - Leia o anúncio para entender a arquitetura por trás de multi‑node, vLLM e o catálogo expandido.
- Consulte a documentação completa do operador e a referência CRD.
- Compartilhe seu feedback com a Microsoft pelo e‑mail [email protected]. O produto está em preview pública, e seu feedback molda o que será lançado em seguida.
Perguntas Frequentes
-
O Foundry Local exige um cluster Azure Local?
Sim, o artigo menciona que é necessário um cluster Azure Local (ou qualquer cluster Kubernetes habilitado para Arc) com a extensão Foundry Local instalada. Para quem já tem ambiente on‑premises gerenciado pelo Azure Arc, a instalação é direta. -
Quanto tempo leva o primeiro deploy de um modelo?
O primeiro deploy pode levar alguns minutos porque o operador baixa a imagem do modelo (que pode ser grande). A imagem fica cacheada em um PersistentVolume, então deploys subsequentes do mesmo modelo são muito mais rápidos. -
Posso usar o mesmo client code que uso na OpenAI cloud?
Sim. O endpoint gerado pelo Foundry Local é compatível com a API de chat‑completions da OpenAI (POST /v1/chat/completions). Basta trocar a URL e a chave de API (Bearer token) – o formato do request é idêntico. -
Preciso de GPU para rodar o Foundry Local?
Não necessariamente. O artigo demonstra o deploy do Phi‑4 em CPU usando o runtime ONNX. Para modelos maiores ou maior throughput concorrente, o runtime vLLM exige GPU – o mesmo Custom Resource (ModelDeployment) permite trocar de CPU para GPU alterando apenas cinco linhas de YAML. -
Como expor o modelo para tráfego real?
O exemplo usa kubectl port‑forward para teste. Para produção, o artigo recomenda expor o deployment via Ingress ou LoadBalancer. Em ambientes brasileiros com restrições de rede, um Ingress com certificado TLS válido e acesso controlado por IAM é essencial.
Artigo originalmente publicado por JonathanSchtechel em Azure Updates - Latest from Azure Charts.
