

GKE Standby Buffers: como reduzir latência de inicialização de nós sem estourar o orçamento
TL;DR: O Google anunciou os GKE standby buffers, uma camada de capacidade sobressalente que mantém nós pré-inicializados e suspensos, retomando 2 a 3 vezes mais rápido que a criação de nós frios. O custo é apenas de armazenamento e IP, sem computação ativa. Para empresas brasileiras que lidam com picos de tráfego, batch jobs ou agentes de IA, a funcionalidade elimina a necessidade de over-provisioning ou workarounds como balloon pods, combinando performance próxima à de buffers ativos com economia significativa.
Application owners e platform engineers sempre enfrentaram uma escolha difícil: gastar excessivamente com over-provisioning para garantir startups rápidas, ou minimizar custos mas suportar cold starts lentos.
Anunciamos hoje uma solução para esse dilema: Google Kubernetes Engine standby buffers. Isso complementa o lançamento dos GKE active buffers no início do ano — uma implementação nativa da CapacityBuffers API do Kubernetes que provisiona capacidade pronta para uso, entregando latência de startup próxima de zero para novos pods. No entanto, active buffers ainda impõem um trade-off entre performance e custo. Os novos GKE standby buffers resolvem isso mantendo um buffer de capacidade suspensa de baixo custo para seus clusters GKE. Com um overhead na casa de poucos pontos percentuais, os standby buffers ajudam a atingir scheduling quase imediato para suas workloads com custo negligenciável. Isso é útil para todos os tipos de workload — uso geral, agentes de IA e tudo mais.
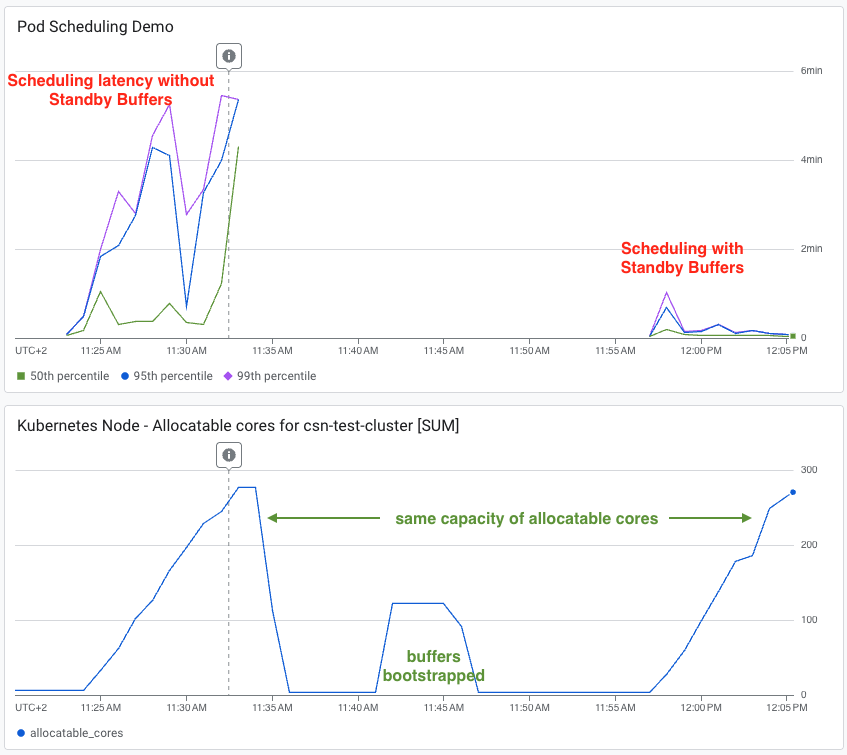
O problema: altos custos e latência
Tradicionalmente, o autoscaling com Kubernetes padrão é eficaz mas lento. Picos de tráfego ou batch jobs fazem o cluster autoscaler provisionar nós novos, deixando Pods em estado pending. Para contornar atrasos, você precisa de workarounds complicados como reduzir thresholds do Horizontal Pod Autoscaler (HPA) ou gerenciar os chamados balloon pods. Esses workarounds são caros:
- Gerenciar balloon pods é operacionalmente complexo, exigindo configuração manual e manutenção contínua de classes de prioridade e resource requests para garantir que funcionem corretamente.
- Reduzir o threshold do HPA adiciona espaço vazio (desperdiçado) que escala linearmente com o tamanho do node pool.
Tanto active buffers quanto standby buffers do GKE permitem definir capacidade de forma declarativa, eliminando a necessidade de workarounds pesados e operacionalmente complexos.
Além disso, os standby buffers reduzem custos de infraestrutura ao salvar o estado do nó em disco, liberando custos de computação e memória, mantendo apenas os custos de persistent disk e endereço IP. Combinados com um active buffer, é possível atingir scheduling de pods quase instantâneo com performance similar ao over-provisioning, mas a um preço muito acessível.

Active e standby buffers trabalhando juntos
Todos os capacity buffers do GKE operam com um princípio similar ao streaming de vídeo: provisionando e gerenciando capacidade disponível antes da demanda (como pré-carregar um vídeo), o GKE ajuda a garantir que recursos estejam prontos quando necessários.
Com o lançamento de hoje, os dois tipos de buffer podem trabalhar em harmonia:
- Active buffer: O Cluster Autoscaler reserva capacidade suficiente para uma quantidade predefinida de pods nos nós existentes e, se necessário, provisiona nós extras. Escolha este buffer pronto para uso para workloads mais sensíveis à latência.
- Standby buffers: Os nós são pré-provisionados e totalmente inicializados com componentes necessários como DaemonSets do Kubernetes, e têm tempo para preload de imagens, mas depois são suspensos, liberando a capacidade de computação subjacente para economizar custos. Quando a demanda aumenta, esses nós retomam 2 a 3 vezes mais rápido que criar um nó novo, preenchendo a lacuna entre cold starts e capacidade sempre ligada.
O active buffer cobre o pico inicial até que os standby buffers sejam retomados. O sistema prioriza reabastecer o active buffer a partir do standby buffer. O standby buffer lida com cargas prolongadas e protege contra cold starts mais lentos. Conforme os standby buffers são reabastecidos, eles inicialmente entram em estado ativo por um período configurável antes de serem suspensos, fornecendo um boost de capacidade ativa durante cargas sustentadas.
Benchmarks iniciais
Em nossos testes, usar standby buffers permitiu entregar latência de scheduling de Agent Sandbox de subsegundo com até 90% menos custo em comparação com over-provisioning completo.
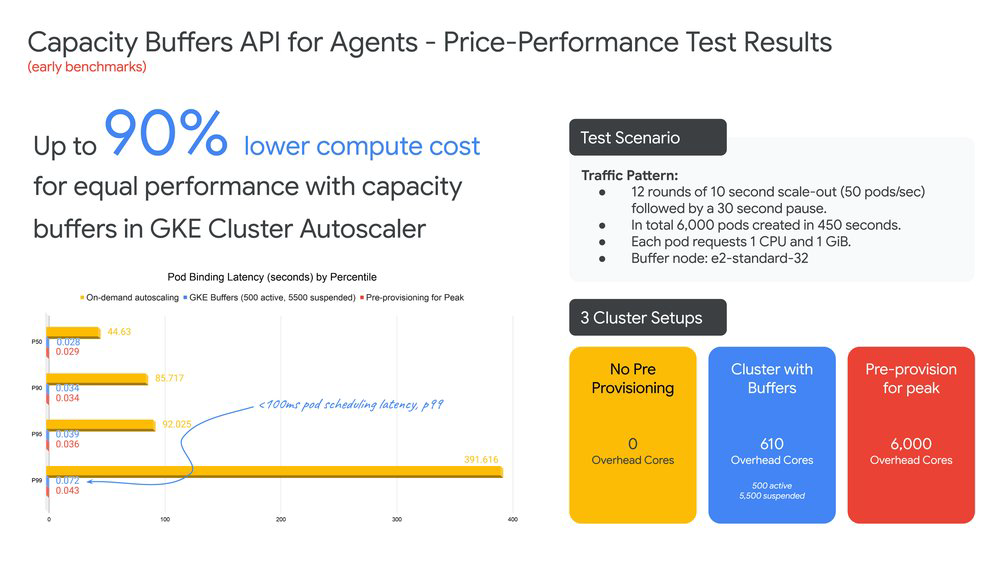
Otimizado para necessidades de negócio
Empresas estão sob pressão constante para otimizar o consumo de recursos enquanto simplificam operações. Reconhecendo que organizações precisam de ferramentas mais inteligentes para gerenciar workloads esporádicas e com picos, trabalhamos duro para entregar standby buffers rapidamente. Agora, seja executando agentes, batch jobs, pipelines de CI/CD, servidores de jogos ou workloads com picos, os capacity buffers do GKE permitem balancear dinamicamente performance e custo. Você finalmente pode definir sua "apólice de seguro" contra picos de tráfego sem pagar um prêmio alto por isso. Com os standby buffers do GKE você pode:
- Evitar cold starts: Nós suspensos por standby buffers retomam 2 a 3 vezes mais rápido que provisionar nós novos, reduzindo a latência de scheduling de pods durante picos de tráfego e carga sustentada.
- Aproveitar custos mais baixos: Um standby buffer custa uma fração do custo de capacidade ativa porque a VM subjacente está suspensa. Você paga por armazenamento e um endereço IP, em vez de compute-hours completos.
- Obter controle declarativo: Substitua workarounds complexos de balloon pods pela API CapacityBuffers nativa e declarativa, explicitando exatamente quanto headroom você precisa, e deixando o GKE cuidar do resto.

“Usar os standby capacity buffers do GKE reduziu nosso time-to-ready de vários minutos para 30 segundos a um preço muito acessível.”
- Pedro Spagiari, Chief Architect at Unico
Como começar
Pronto para melhorar sua performance e economizar em custos?
- Comece definindo um recurso
CapacityBufferno seu cluster para especificar o tamanho alvo do buffer. - Tente balancear entre standby buffers (para reduzir latência de scheduling de pods em cargas sustentadas) e active buffers (para atender necessidades de capacidade imprevisíveis e imediatas).
Vamos ver um exemplo de como configurar buffers para um Deployment usando também ComputeClasses personalizadas.
Configuração básica
Começando com uma configuração básica, crie um namespace:
apiVersion: v1
kind: Namespace
metadata:
name: my-namespace
Depois, crie uma ComputeClass personalizada (opcional):
apiVersion: cloud.google.com/v1
kind: ComputeClass
metadata:
name: my-ccc
namespace: my-namespace
spec:
# Buffers will also be created according to these priorities
priorities:
- machineFamily: n4
- machineFamily: n4d
- machineFamily: c4
- machineFamily: c4d
nodePoolAutoCreation:
enabled: true
Defina o tamanho da unidade do buffer
Você pode usar um PodTemplate como referência para o tamanho da unidade do buffer. Também pode criar um buffer para um deployment específico ou qualquer objeto que defina scale subResource.
# Defines the resource requirements for one unit of buffer.
apiVersion: v1
kind: PodTemplate
metadata:
name: my-buffer-unit-template
namespace: my-namespace
template:
spec:
terminationGracePeriodSeconds: 0
tolerations:
# Optional: Ensures buffer pods can land on any node.
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: buffer-container
image: registry.k8s.io/pause:3.9
resources:
requests:
cpu: "1"
memory: "1Gi"
limits:
cpu: "1"
memory: "1Gi"
# Optional: Using buffers with a custom ComputeClass /
# controls the properties of the nodes GKE provisions.
nodeSelector:
cloud.google.com/compute-class: my-ccc
Crie os buffers
Por fim, crie um objeto CapacityBuffer referenciando seu PodTemplate. Aqui, você cria um standby buffer de 50 CPUs e 50 GB de RAM:
apiVersion: autoscaling.x-k8s.io/v1beta1
kind: CapacityBuffer
metadata:
name: my-standby-buffer-resource-limits
namespace: my-namespace
annotations:
# Optional: Time after which buffer nodes are suspended.
# Default is 5 minutes.
buffer.gke.io/standby-capacity-init-time: "5m"
# Optional: Time after which standby buffers are recreated.
# Default is 1 day, "never" avoids refreshing.
buffer.gke.io/standby-capacity-refresh-frequency: "1d"
spec:
podTemplateRef:
name: my-buffer-unit-template
# The desired state is 20 standby buffer units.
# When a standby buffer gets used, a new one gets created.
limits:
cpu: "50"
memory: "50Gi"
provisioningStrategy: "buffer.gke.io/standby-capacity"
E um active buffer de 5 CPUs e 5 GB de RAM (opcional):
apiVersion: autoscaling.x-k8s.io/v1beta1
kind: CapacityBuffer
metadata:
name: my-active-buffer-resource-limits
namespace: my-namespace
spec:
podTemplateRef:
name: my-buffer-unit-template
# The desired state is 2 active buffer units.
# When an active buffer gets used, a new one gets created.
limits:
cpu: "5"
memory: "5Gi"
provisioningStrategy: "buffer.x-k8s.io/active-capacity"
Finalmente, aplique os objetos acima ao seu cluster. Pronto!
Agora, qualquer deployment existente ou futuro que possa ser escalonado no espaço reservado pelos buffers se beneficiará de latências de scheduling de pods mais rápidas.
Teste os buffers
Você pode verificar o status dos seus buffers. No Kubernetes, nós suspensos podem ser identificados pela condição Suspended.
kubectl get nodes -o custom-columns='NAME:.metadata.name,SUSPENDED:.status.conditions[?(@.type=="Suspended")].status'
Espere uma saída como esta, e aguarde os standby buffers serem suspensos.
NAME SUSPENDED
gke-my-cluster-nap-n4-standard-8-k960-...-ffbx False # Node has been resumed.
gke-my-cluster-nap-n4-standard-4-k960-...-h2x4 <none> # Node was never suspended.
gke-my-cluster-nap-n4d-standard-8-1cip-...-74jf True # Node is suspended.
Para testar os buffers, crie um deployment e escale-o.
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment
namespace: my-namespace
spec:
replicas: 1
selector:
matchLabels:
app: my-deployment
template:
metadata:
labels:
app: my-deployment
spec:
containers:
- name: busybox
image: busybox
command: ["sleep", "inf"]
resources:
requests:
cpu: "500m"
memory: "500Mi"
# Optional: Using buffers with a custom ComputeClass /
# controls the properties of the nodes GKE provisions.
nodeSelector:
cloud.google.com/compute-class: my-ccc
Escalar esse deployment para duas réplicas permite que elas sejam atribuídas ao active buffer para scheduling imediato. O active buffer é então imediatamente reabastecido a partir do standby buffer. Simultaneamente, o standby buffer inicia o provisionamento de novos nós.
Se você escalar ainda mais o deployment para 50 réplicas, todas elas serão escalonadas no standby buffer assim que os nós retomarem. Novos nós provisionados para reabastecer o standby buffer funcionam brevemente como active buffers, fornecendo um boost temporário de capacidade ativa. Portanto, ao escalar ainda mais o deployment para 100 réplicas durante esse período, você pode notar que as novas réplicas se beneficiam de scheduling imediato.
Melhores práticas para standby buffers no GKE
Ao trabalhar com standby buffers no GKE, considere os seguintes pontos:
- Defina standby buffers suficientes para cobrir a carga estendida que você espera encontrar, para que os buffers possam ser reabastecidos em background a partir de um cold start. Um standby buffer de tamanho adequado pode reduzir sua latência máxima de scheduling de pods para o tempo de retomada de um nó — cerca de 30 segundos.
- Quando o buffer começa a ser usado e é reabastecido, novos nós de buffer entram inicialmente em estado ativo antes de suspender. Isso ajuda a aumentar a capacidade ativa durante uma carga prolongada.
- Se sua aplicação exige a menor latência possível de scheduling de pods, defina um active buffer de tamanho suficiente para cobrir quaisquer picos iniciais que você espera encontrar até que os nós do standby buffer consigam retomar. O sistema prioriza reabastecer o active buffer consumindo o standby buffer. Um active buffer e um standby buffer de tamanhos adequados podem ajudar a atingir latência de scheduling de pods de um segundo por uma fração do custo do over-provisioning.
- Experimente com diferentes tamanhos de buffer para obter o melhor resultado para sua workload.
Para ajudar, criamos um simulador para auxiliar no dimensionamento dos buffers para atingir suas metas de performance, disponível em https://github.com/gke-labs/buffers-simulator.
Teste você mesmo!
Active e standby buffers no GKE fornecem uma solução nativa para escalonamento de workloads com baixa latência e custo-efetivo, mantendo buffers de capacidade warm e standby. Ao evitar cold starts lentos de nós, os buffers ajudam aplicações críticas de performance a lidar com picos súbitos de tráfego. Este recurso substitui workarounds manuais complexos como balloon pods por uma API declarativa simples, e permite estratégias de buffer fixas, baseadas em porcentagem ou com limites de recursos para ajudar a manter objetivos de nível de serviço rigorosos de forma econômica e sem over-provisioning para pico.
Standby buffers estão disponíveis para clusters GKE rodando versão 1.36.0-gke.2253000 ou superior. Para começar com buffers, consulte a documentação.
Perguntas Frequentes
-
Qual a diferença entre active buffer e standby buffer no GKE?
O active buffer mantém nós ligados e prontos para uso imediato, ideal para workloads ultra-sensíveis à latência. O standby buffer mantém nós suspensos — o estado é salvo em disco, mas a VM não roda —, retomando em ~30 segundos com custo muito menor (apenas armazenamento e IP). Os dois podem ser combinados: o active cobre o pico inicial enquanto o standby é retomado. -
Quanto custa manter um standby buffer em comparação com over-provisioning?
Segundo a Google, os testes mostraram redução de até 90% no custo em relação ao over-provisioning completo para manter a mesma latência de scheduling. Isso porque você paga apenas pelo disco persistente e pelo endereço IP do nó suspenso, e não pelo compute-hour inteiro. O overhead fica na casa de poucos pontos percentuais sobre o custo do cluster base. -
Como configurar um standby buffer no meu cluster GKE?
Você define um recurso CapacityBuffer no namespace desejado, referenciando um PodTemplate que especifica requests de CPU e memória da unidade de buffer. No spec, use provisioningStrategy: buffer.gke.io/standby-capacity e defina limits de cpu e memory. O Cluster Autoscaler gerencia a criação e suspensão dos nós automaticamente. Exemplos completos de YAML estão disponíveis na documentação oficial. -
Quais workloads se beneficiam mais dos standby buffers?
Workloads com padrão de tráfego esporádico ou em picos — como agentes de IA, batch jobs, CI/CD pipelines, servidores de jogos e aplicações sujeitas a variação sazonal. Também são úteis para ambientes que precisam de escalabilidade rápida sem comprometer o orçamento, como fintechs, e-commerce e plataformas de streaming no Brasil. -
Preciso de uma versão específica do GKE para usar standby buffers?
Sim. Os standby buffers estão disponíveis para clusters GKE rodando a versão 1.36.0-gke.2253000 ou superior. É recomendável verificar a documentação de compatibilidade e testar em ambiente de staging antes de habilitar em produção.
Artigo originalmente publicado por Konrad KurdejStaff Software Engineer, Google Kubernetes Engine em Cloud Blog.
