

A Foundry IQ (motor de busca da Azure AI Search) acaba de receber uma atualização significativa em seu mecanismo de agentic retrieval. O resultado prático para quem desenvolve AI agents corporativos: respostas mais completas, menor consumo de tokens e uma redução drástica na taxa de 'não sei'.
TL;DR: A Foundry IQ (Azure AI Search) lançou uma nova versão de suas knowledge bases que substitui o RAG estático por um loop de retrieval agentic. Os ganhos são expressivos: até 54% de melhoria no recall de evidências e 34% de redução no custo de tokens. Para empresas brasileiras que dependem de AI agents com fontes de conhecimento internas, isso significa respostas mais precisas com menor gasto operacional — um trade-off que vale a pena avaliar.
Agentes só são valiosos quando têm acesso ao conhecimento da organização. O ponto de partida comum é dar ao agente uma ferramenta de retrieval para encontrar contexto relevante. Mas o que fazer quando o agente não encontra o contexto necessário?
As knowledge bases do Foundry IQ resolvem esse problema ao orquestrar o retrieval de forma agentic: conectam o agente a uma ou mais fontes de conhecimento, recuperam o contexto necessário e produzem respostas fiéis e precisas. A Microsoft comparou ferramentas de retrieval standalone com as knowledge bases usando o desafiador benchmark BrowseComp-Plus e encontrou:
- Substituir RAG de etapa única por uma knowledge base melhora o recall de evidências em até 46%.
- Combinar um modelo de agente menor com retrieval agentic melhora o recall em até 54%, controlando custos e aumentando a responsividade.
- Em ambos os casos, o número de chamadas de ferramenta de retrieval é reduzido, resultando em 34% de economia de tokens.
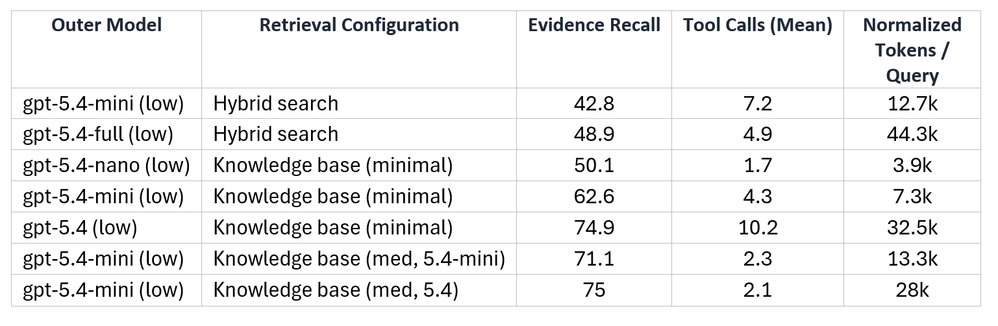
Tabela 1: Comparação de retrieval orquestrado por agente usando knowledge bases ou uma ferramenta de busca híbrida standalone.
Desde o último lançamento do motor agentic, as melhorias no recall de evidências em conteúdo empresarial multilíngue foram de 10% (minimal), 8% (low) e 9% (medium) nos respectivos níveis de esforço de raciocínio.
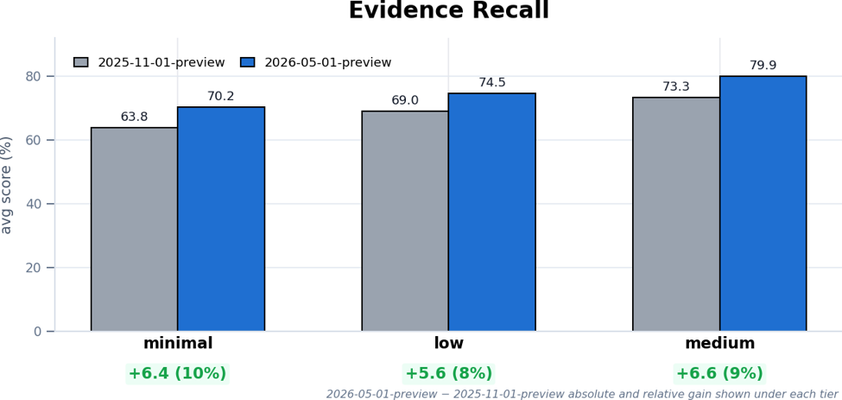
Figura 1: Média de recall de evidências em datasets com fonte única usando gpt-5.4-mini, por nível de esforço de retrieval-reasoning.
Também houve avanços na qualidade das respostas: 20% (minimal), 8% (low) e 10% (medium).
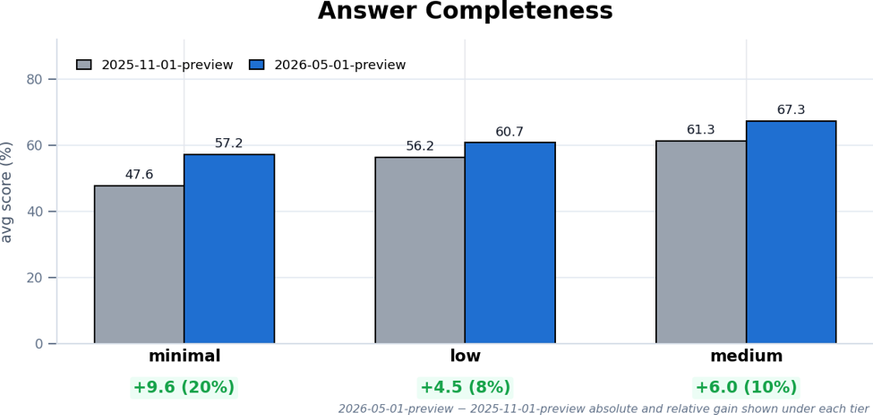
Figura 2: Completude média das respostas em datasets com fonte única usando gpt-5.4-mini.
O que está por trás das melhorias?
- Retrieval de fonte de conhecimento aprimorado: o workflow estático de orquestração foi substituído por um loop agentic dinâmico. Agora o agente agrupa requisições e customiza consultas para cada fonte, podendo revisar o conteúdo e determinar se novas consultas são necessárias.
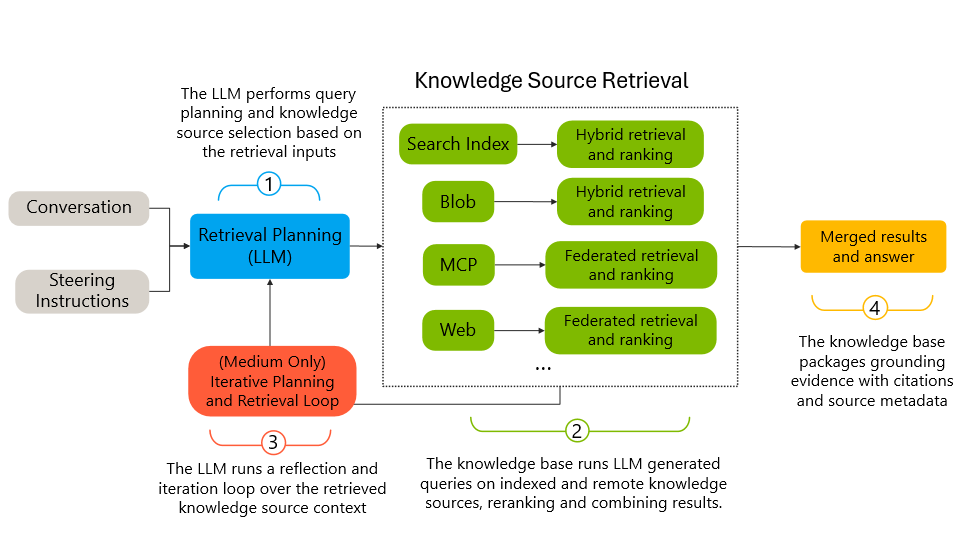
- Ranker semântico melhorado: o modelo de reranking foi retreinado para destacar passagens mais relevantes de grandes coleções de documentos, retornando contexto de maior qualidade com menos passagens irrelevantes.
- Síntese de respostas aprimorada: as diretrizes de geração foram refinadas para produzir respostas mais completas e estruturadas, sempre ancoradas nas evidências recuperadas.
- Token caching e eficiência de prompt: as chamadas LLM foram otimizadas para se beneficiar de caching do provedor, reduzindo o processamento sem sacrificar qualidade.
- Especialização de schema para chamadas MCP: a descrição da ferramenta MCP para knowledge bases agora se adapta automaticamente ao modelo e configuração. Modelos menores recebem orientações mais rígidas para evitar consultas redundantes; modelos maiores têm mais flexibilidade, mas com diretrizes para evitar divisão excessiva de consultas.
Métricas
Em vez de depender apenas de LLM-as-a-judge, a equipe adotou métricas baseadas em ground-truth, inspiradas no TREC 2024 RAG Track. Agora é possível medir: quão bom é o resultado em relação à resposta ideal, o que falta para ser perfeito e qual parcela do ground truth foi coberta. A principal métrica usada é o Evidence Recall — a proporção de nuggets de ground truth cobertos pelos documentos recuperados pelo agente.
Para avaliação agentic, o sistema simula um usuário sem acesso à resposta, que interage com um agente de busca conectado a um índice ou knowledge base. Um juiz independente observa a interação e gera métricas como recall e correção.
Como as knowledge bases equilibram recall e custo?
Desenvolvedores têm trade-offs diferentes entre custo incremental de tokens e ganho de recall. A Microsoft comparou exaustivamente knowledge bases e índices de busca standalone para demonstrar que as knowledge bases operam na fronteira de eficiência:
- Menor custo: uma knowledge base minimal com gpt-5.4-mini (low reasoning) é mais barata e de maior qualidade que qualquer ferramenta híbrida standalone.
- Maior recall: uma knowledge base minimal com gpt-5.4 (medium reasoning) oferece o maior recall testado.
- Equilíbrio: uma knowledge base medium com gpt-5.4 para retrieval e gpt-5.4-mini para orquestração (low reasoning) combina baixo custo com alto recall.
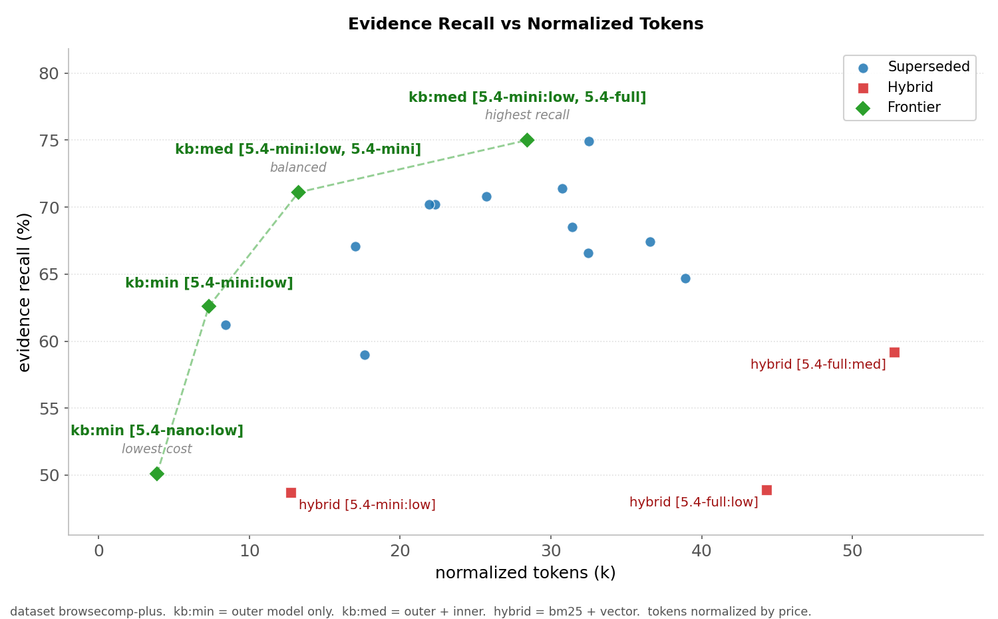
Figura 3: Diagrama de fronteira de Pareto mostrando custo (tokens) vs cobertura de evidências. Knowledge bases (verde) claramente estão na fronteira de eficiência; opções standalone (vermelho) ficam atrás.
Schemas MCP melhorados para retrieval agentic
As knowledge bases podem ser consultadas via REST API ou como ferramenta MCP. A nova preview apresenta um schema dinamicamente especializado conforme o tamanho do modelo orquestrador e as configurações de retrieval:
- Variantes por tamanho de modelo: nano, mini e full-size. Modelos menores recebem orientações mais rígidas para preservar termos-chave; modelos maiores ganham flexibilidade, mas com restrições para evitar chamadas desnecessárias.
- Variantes por modo de retrieval: em minimal, o modelo é direcionado a gerar consultas preservando palavras-chave. Em low e medium, o schema exige delegação completa da tarefa, incluindo todas as restrições.
Como a geração de consultas pelo modelo pode distorcer a intenção?
Considere esta pergunta contábil:
“Para que servem os swaptions no contexto de derivativos não designados e instrumentos derivativos?”
O modelo externo gera a seguinte consulta:
“swaptions usados para atingir uma combinação alvo de dívida de taxa fixa e variável”
A ausência do termo “derivativos não designados” e a adição de “dívida” alteram completamente o alvo da busca. Em vez de documentos sobre tratamento contábil, a busca puxa para taxas de juros. Para o usuário, parece um retrieval ruim, mas a falha oculta está na distorção da tarefa pelo modelo. Esse comportamento é surpreendentemente comum — e é o que esta atualização busca corrigir.
Medindo a precisão da delegação de subagentes
Para medir, a equipe rotulou um dataset de perguntas e follow-ups com a semântica crítica de retrieval (entidades, palavras-chave, unidades, tokens alfanuméricos, filtros). A precisão da delegação é calculada com base nas restrições preservadas na tarefa delegada — penalizando tanto restrições descartadas quanto adicionadas sem suporte.
Resultados: a delegação via knowledge base melhora o recall em todos os datasets
Comparando knowledge bases medium com agentes que usam índice de busca standalone, em mais de 4.000 cenários, as knowledge bases consistentemente melhoram o recall e a correspondência de respostas, além de reduzir o número de tool calls.
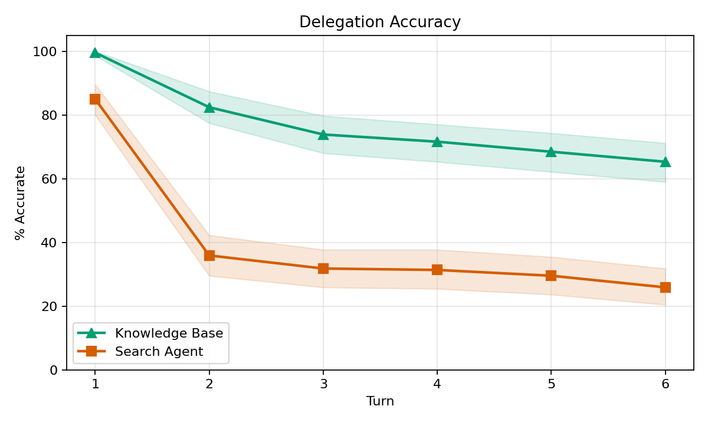
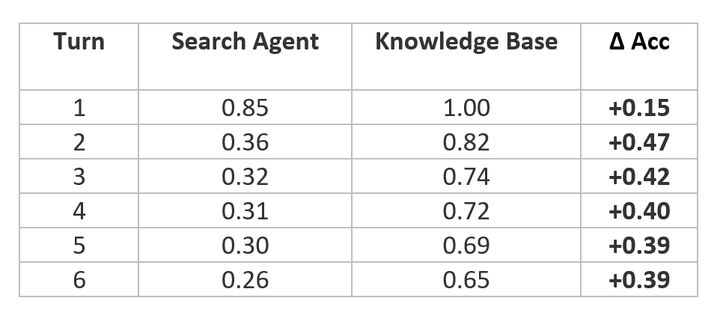
Figura 4: Precisão da delegação por turno. Knowledge bases preservam mais semântica crítica que search agents, com gap médio de +0,370.
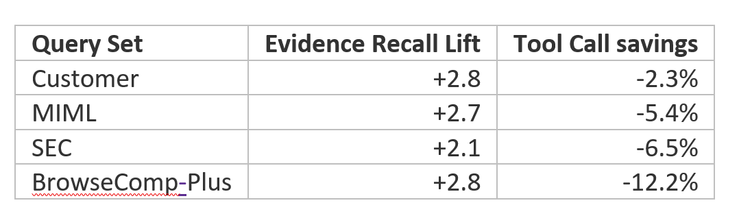
Tabela 2: Comparação entre search agent e knowledge base em quatro datasets, 4.100 cenários.
As knowledge bases melhoram a qualidade das respostas?
Sim. A Microsoft comparou a qualidade de respostas sintetizadas entre RAG tradicional (BM25, híbrido) e knowledge bases em aproximadamente 3.300 consultas empresariais. As configurações avaliadas:
- BM25: retrieval por palavras-chave.
- Híbrido: BM25 + vetorial.
- Knowledge Bases: Minimal (híbrido + reranking semântico + filtragem de irrelevantes + mesclagem entre índices); Low (Minimal + uma rodada agentic); Medium (até duas rodadas agentic).
Cada nível adicional melhora o stack RAG. O benefício principal é a capacidade de escalar o esforço de retrieval com uma única configuração. No geral, comparado ao BM25, o sistema completo reduz a taxa de 'não sei' em 94,5% e melhora o recall de evidências em 37,9%.
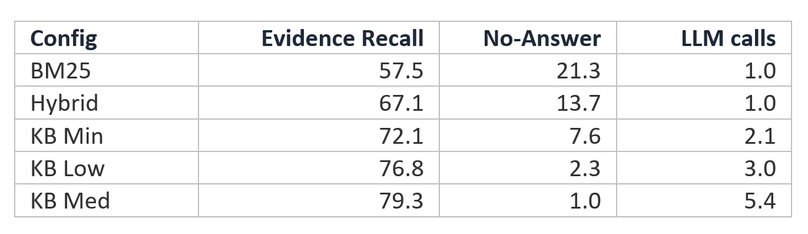
Tabela 3: Valores absolutos para BM25, Híbrido, knowledge base Minimal, Low e Medium com gpt-5.4-mini.
Retrieval heterogêneo
Muitos cenários empresariais envolvem perguntas que cruzam conteúdo estruturado e não estruturado. A tabela abaixo mostra que as knowledge bases combinam eficazmente diferentes tipos de fontes para impulsionar o recall:
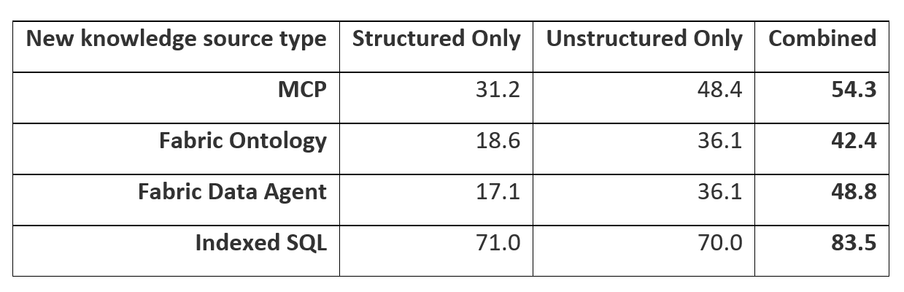
Tabela 4: Evidence recall para HFWIKI (MCP), FABRICIQ-SEC (Fabric), SEC-SQL-Hybrid (SQL).
Como começar?
A nova funcionalidade está disponível hoje na versão preview mais recente da API. Para testar: crie uma knowledge base, conecte uma ou mais fontes de conhecimento e chame a retrieve API com seu nível preferido de retrieval reasoning effort. Saiba mais sobre knowledge bases e agentic retrieval aqui.
Apêndice
Os benchmarks utilizados incluem datasets de clientes (relatórios corporativos, documentos de planos de saúde), DAYI (médico chinês), FDA (rótulos e documentos clínicos), SEC (arquivamentos de empresas públicas), MIML (multissetorial e multilíngue), FreshQA (sensível a atualidade), HFWIKI (documentação Hugging Face + Wikipedia), FABRICIQ-SEC (registros financeiros + SEC), SEC-SQL-Hybrid (metadados estruturados e narrativas) e BrowseComp-Plus (830 consultas verificadas, corpus indexado em chunks de 512 tokens com text-embedding-3-large).
Métricas utilizadas
| Métrica | O que mede |
|---|---|
| Evidence Coverage | Proporção de nuggets de ground truth cobertos pelos documentos recuperados |
| Answer Completeness | Proporção de nuggets de ground truth presentes na resposta gerada |
| No Answer Rate | Se o modelo se recusou a responder ou retornou "não sei" |
Métricas baseadas em ground-truth para avaliar conteúdo recuperado e respostas geradas.
Perguntas Frequentes
-
O que diferencia uma knowledge base de uma ferramenta de busca standalone?
Enquanto uma ferramenta standalone faz uma única consulta RAG, a knowledge base orquestra um loop agentic: o agente pode refinar a consulta, acionar múltiplas fontes e revisar o conteúdo recuperado, aumentando significativamente o recall de evidências. -
Como as knowledge bases reduzem o custo de tokens em 34%?
Elas reduzem o número de chamadas de retrieval tool ao concentrar a busca em um loop mais inteligente, além de usar token caching e prompts mais eficientes, diminuindo o processamento sem perder qualidade. -
O que significa retrieval reasoning effort e como escolher o nível ideal?
O esforço de raciocínio de retrieval (minimal, low, medium) controla quantas iterações o agente faz. Minimal é mais barato e rápido, medium oferece maior recall. A escolha depende do trade-off entre custo e acurácia desejada. -
Esse recurso já está disponível para clientes brasileiros?
Sim, a funcionalidade está disponível na versão preview mais recente da API do Azure AI Search. Basta criar uma knowledge base, conectar fontes de conhecimento e chamar a retrieve API com o nível de esforço desejado. -
Como a delegação de consultas evita distorções no retrieval?
O modelo anterior muitas vezes alterava a intenção da busca ao inserir suposições próprias. As novas knowledge bases preservam termos críticos da consulta original e penalizam tanto a omissão quanto a adição não suportada de restrições, mantendo o foco.
Artigo originalmente publicado por MattGotteiner (Microsoft) em Azure Updates - Latest from Azure Charts.
