

No esqui estilo livre e no snowboard, o replay de vídeo convencional é insuficiente para desvendar a física por trás de manobras complexas. Em alta velocidade, converter movimento em dados acionáveis — como ângulos articulares, velocidades rotacionais e compressão corporal — é um desafio monumental que exige um modelo tridimensional completo do atleta em tempo real.
Em uma colaboração com o Google DeepMind, um sistema foi desenvolvido para oferecer essa análise biomecânica aos atletas olímpicos dos EUA. O modelo de pose estimation transforma vídeo 2D em análise 3D, mapeando 63 articulações em um sistema de coordenadas localizado. Para o cenário de negócios, isso demonstra a migração definitiva de dados abstratos para insights objetivos e de alto valor.
O desafio: condições extremas quebram a visão computacional padrão
Gerar um esqueleto 3D de 63 articulações a partir de vídeo 2D é uma carga de trabalho computacional massiva. Fazer isso fora de um ambiente de laboratório, com atletas em alta velocidade e vestindo equipamentos volumosos, leva a computer vision ao seu limite. Quando um atleta realiza uma rotação, partes do corpo ficam ocultas (occlusion), fazendo com que modelos padrão percam a precisão.

A solução não trata cada frame isoladamente. Em vez disso, utiliza temporal reasoning e learned priors para inferir a posição de articulações ocultas com base na trajetória corporal. Isso mantém a integridade do esqueleto digital mesmo durante acrobacias invertidas e rápidas.
A infraestrutura: TPUs e Vertex AI
Resolver a oclusão é apenas parte do problema. Entregar insights segundos após a aterrissagem de um atleta exige uma arquitetura de alta performance. Desenvolvemos uma inference engine projetada para lidar com demandas intensas de MLOps.
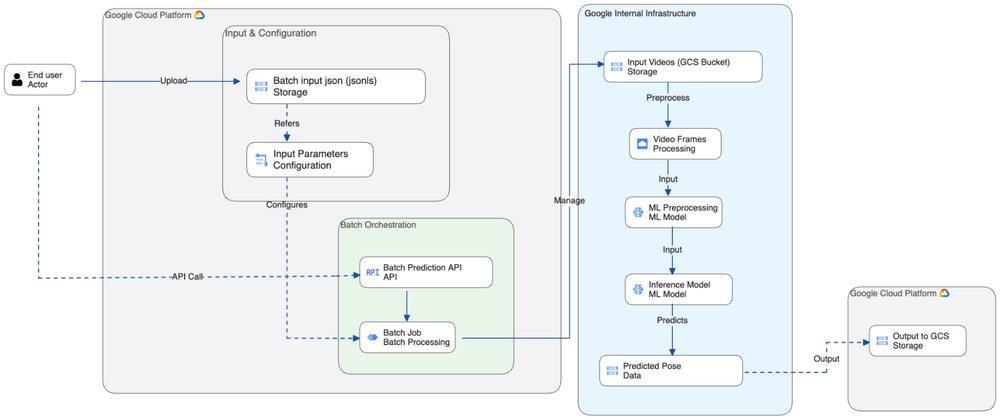
A base de hardware: TPUs
O pipeline utiliza Tensor Processing Units (TPUs) da Google para processar o pesado cálculo matricial. Para eliminar a latência de cold start típica da nuvem, foram provisionadas slices dedicadas de TPU, mantendo os modelos permanentemente carregados em High-Bandwidth Memory (HBM). O resultado é uma inferência preditiva e instantânea, sem a contenção de recursos comum em ambientes multi-tenant.
Orquestração em escala: Vertex AI
Fazer o deployment em um servidor local é simples; orquestrar dados em tempo real em um evento global não é. O Vertex AI atuou como o plano de controle para gerenciar volume e latência:
- Escalabilidade horizontal com batch prediction: Ao utilizar a Vertex AI Batch Prediction API, o sistema desacopla o carregamento do modelo da inferência, permitindo escalar horizontalmente para processar múltiplos feeds simultaneamente.
- Elasticidade sob demanda: As necessidades computacionais são "explosivas" (bursty). O Vertex AI provisiona recursos dinamicamente para absorver picos de dados, evitando desperdício de recursos always-on.
- Segurança e isolamento: Para proteger dados proprietários, foi estabelecido um Private Endpoint dentro de uma Virtual Private Cloud (VPC), garantindo que o tráfego utilize caminhos de rede dedicados, minimizando a superfície de ataque.
Além da neve
Um sistema capaz de realizar pose estimation confiável sob condições de alta velocidade e oclusão constante é, por definição, resiliente. A arquitetura de IA aplicada aqui, focada em inteligência generalizada a partir de fluxos de dados estruturados, possui aplicações vastas: desde fisioterapia baseada em IA generativa até assistência robótica em chão de fábrica. Para empresas brasileiras que buscam eficiência operacional, o aprendizado é claro: a combinação de um hardware especializado com uma orquestração robusta de MLOps é o diferencial competitivo para converter complexidade técnica em resultado de negócio.
Artigo originalmente publicado por The Google Cloud Project Team em Cloud Blog.
