

Anyscale on Azure: IA empresarial em escala massiva com Ray no AKS
TL;DR: Anyscale on Azure traz o runtime open‑source Ray como um serviço nativo Azure, executando no AKS. Ele unifica preparação de dados, treinamento distribuído, fine‑tuning e inferência em um único programa Python. Para empresas brasileiras, a promessa é concreta: redução de 40 a 60% nos gastos com GPU, utilização sustentada acima de 80% e soberania total dos dados – modelos e pesos nunca saem da sua assinatura Azure. O modelo de precificação é usage‑based com desconto via MACC.
Em algum lugar do seu time de plataforma de IA, um engenheiro está de plantão neste fim de semana — não pelo modelo, não pelo treinamento, mas pelo código de integração que mantém cinco sistemas separados de processamento de IA juntos. Preparação de dados em um. Treinamento em outro. Avaliação em um terceiro. Serving em um quarto. Observabilidade atrelada a todos eles. A cola entre esses sistemas evoluiu silenciosamente para um sistema de produção próprio, com seus próprios modos de falha e seu próprio pager.
É assim que a IA em escala se parece para a maioria das empresas em 2026. Para processar toda a gama de workloads de IA, os times não têm uma plataforma, mas uma pilha de múltiplos engines de computação — costurados e monitorados 24 horas por dia. Falhas de treinamento se tornam cada vez mais caras à medida que clusters multi‑node de GPU ficam subutilizados e difíceis de operar. Custos de inferência sobem em linha reta quando deveriam estar curvando na direção oposta. E os aceleradores por baixo, com preços de seis dígitos por nó ao ano, operam com 30 a 40% de utilização.
Nada disso é um problema de modelo. É um problema de sistemas — e expõe uma divisão que está se alargando na indústria.
O que muda quando a IA deixa de ser apenas chamadas de API?
A maioria das empresas começa sua jornada de IA chamando APIs de modelos hospedados. É a maneira mais rápida de experimentar e colocar em produção. Mas, à medida que a adoção cresce, os custos de inferência aumentam linearmente enquanto a diferenciação continua limitada. As organizações que estão se destacando fazem mais do que consumir modelos. Elas os personalizam com dados proprietários, operam‑nos em escala e são donas da infraestrutura entre seus dados e seus modelos. Sua economia unitária melhora conforme escalam. A linha divisória não é orçamento. Não é ambição. É uma única decisão arquitetural: se a camada entre seus dados e seus modelos é algo que você aluga em pedaços ou executa como um sistema único.
Esse sistema unificado para IA de ponta a ponta, quase sem exceção, é construído sobre um runtime: Ray, um framework open‑source amplamente adotado por nativos de IA como Cursor, Mistral e xAI para atuar como o motor que alimenta muitas de suas workloads, desde processamento multimodal de dados até reinforcement learning.
Como o Anyscale on Azure unifica o ciclo de vida da IA?
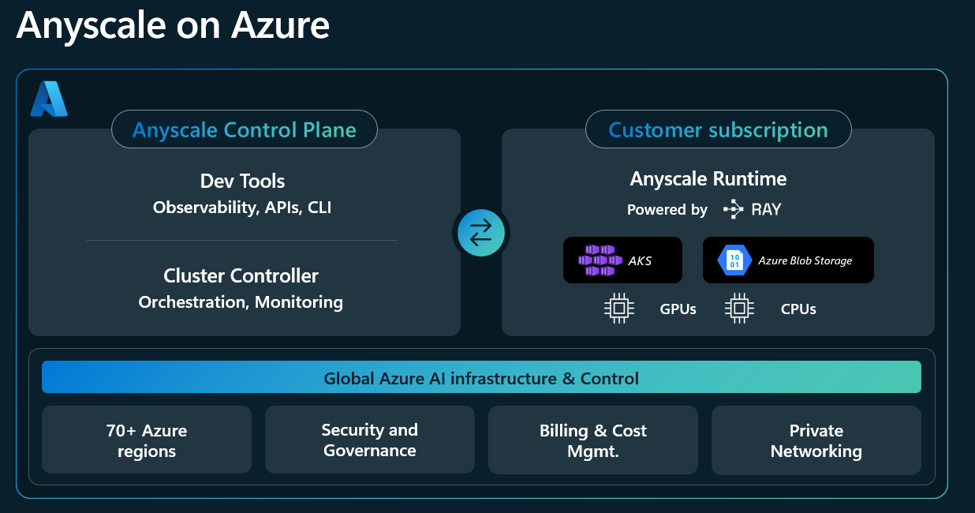
O Anyscale on Azure traz o runtime de computação distribuída no qual a indústria de AI convergiu — Ray — para dentro do seu tenant Azure como um serviço Azure Native, que inclui ferramentas de desenvolvimento específicas e um painel unificado para gerenciamento de clusters, construído através de uma colaboração profunda de engenharia entre Anyscale e Microsoft.
Diferente de outros engines de processamento que suportam apenas um tipo de hardware (ex.: CPUs) ou focam em uma única workload (ex.: inferência), o Ray transforma um cluster heterogêneo de CPUs e GPUs em um runtime Python único, compondo preparação de dados, treinamento distribuído, fine‑tuning, reinforcement learning, inferência de alta taxa e execução de agentes como um único programa — não cinco sistemas interligados. O Anyscale Runtime é a camada de produção que as empresas podem utilizar em caminhos críticos desde o primeiro dia, trazendo operações gerenciadas de cluster, suporte enterprise e a confiabilidade operacional necessária para rodar workloads de IA e dados em escala.
No Azure, esse runtime executa nos seus clusters Azure Kubernetes Service (AKS), dentro da sua assinatura, e sob a identidade de workload do Microsoft Entra ID. Seus dados, modelos e pesos nunca saem da sua nuvem, e o consumo é faturado através do Azure com desconto contra seu compromisso existente (MACC).
Soberania não é um rótulo adicionado depois. É o ponto de partida arquitetural: dados e modelos do cliente no tenant do cliente, dentro do limite de governança. A economia variável por token das APIs hospedadas é substituída por computação que você governa diretamente. Seus dados proprietários se tornam uma vantagem composta, em vez de um payload enviado a um endpoint de terceiros.
Um único runtime para todo o ciclo de vida — como isso funciona na prática?
O perfil de custo da IA empresarial é em grande parte arquitetural. Stacks fragmentadas — sistemas separados para prep, treinamento, avaliação e serving — produzem um conjunto previsível de modos de falha: tempo ocioso de GPU, código de integração e movimentação de dados entre sistemas.
O resultado: utilização de GPU em produção na faixa de 30 a 40%, contra aceleradores que custam seis dígitos por nó ao ano.
Na mesma frota, clientes do Anyscale rodam esses aceleradores com utilização sustentada acima de 80% e reportam redução de 40 a 60% nos gastos com GPU em comparação com clusters estáticos single‑tenant — impulsionada por alocação fracionada de GPU (até 0,2 de um dispositivo), bin‑packing entre perfis complementares de memória e computação, gang scheduling para treinamento distribuído, preempção por prioridade que permite que inferência de produção tenha precedência sobre treinamento ad‑hoc, e integração com spot instances com checkpoint‑aware para que jobs de longa duração sobrevivam à recuperação sem perda de trabalho.
O Anyscale on Azure substitui isso por um único runtime baseado em Ray que abrange todo o ciclo de vida como um grafo de computação distribuída:

Ray Data (preparação distribuída) → Ray Train (treinamento com tolerância a falhas) → Ray Tune (busca de hiperparâmetros) → Ray Serve (inferência) — sob um único control plane gerenciado.
Além do Ray open‑source, o Anyscale Runtime adiciona treinamento tolerante a falhas com checkpoint/restart, scheduling otimizado, inicialização mais rápida de cluster, auto‑scaling consciente de inferência e observabilidade por estágio.
Ray é a camada unificadora que, em vez de substituir, simplifica o processamento distribuído da stack de frameworks que a indústria de IA já usa: PyTorch, Hugging Face Transformers, FSDP, DeepSpeed e Megatron para treinamento; vLLM e SGLang para inferência de alta taxa com continuous batching, paged attention e speculative decoding. Ray Train orquestra os três padrões de paralelismo que o treinamento moderno exige — data parallel, model parallel e hybrid 3D parallel (data + tensor + pipeline) — para modelos com trilhões de parâmetros, sem que os times precisem escrever código distribuído customizado.
O payoff arquitetural é direto: um único programa Python define um grafo que abrange preparação pesada em CPU e treinamento pesado em GPU. O modelo produzido pelo Ray Train é servido pelo Ray Serve no mesmo cluster, contra o mesmo armazenamento. A superfície operacional, de identidade e observabilidade é unificada em vez de fragmentada.
Quais workloads as empresas estão rodando com o Anyscale on Azure?
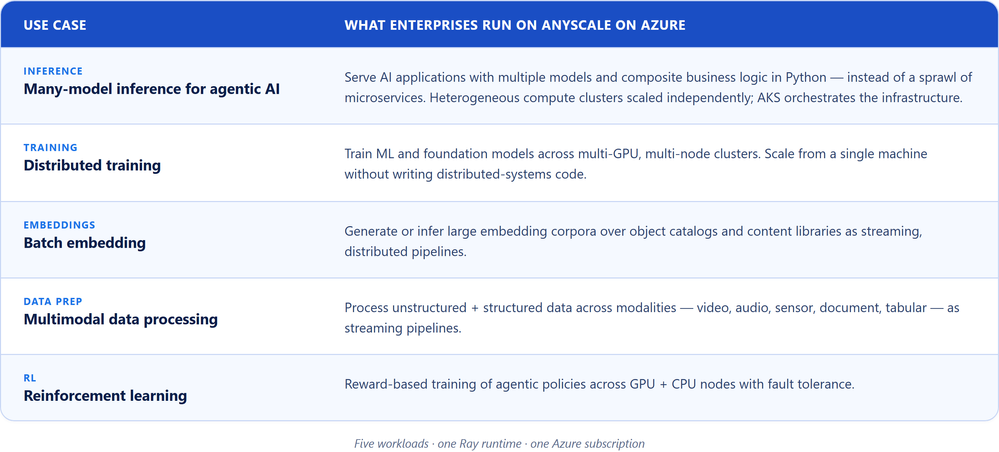
Existem cinco workloads que impulsionam o desenvolvimento de sistemas modernos de IA, abrangendo processamento de dados, treinamento, inferência e simulação. Mas na maioria dos ambientes, cada uma depende de engines, frameworks e camadas de orquestração separados. A fragmentação resultante aumenta gastos com infraestrutura, latência e complexidade de engenharia. Isso torna um runtime único baseado em Ray sob o control plane gerenciado da Anyscale a escolha operacionalmente racional.
O Anyscale on Azure fornece uma plataforma completa para construir e implantar aplicações de IA usando as mesmas APIs do Ray open‑source. Enquanto o data plane roda dentro do cluster AKS do cliente, o control plane gerenciado fornece uma interface unificada para desenvolvimento, debugging e operações de cluster.
Como a arquitetura garante soberania de dados?
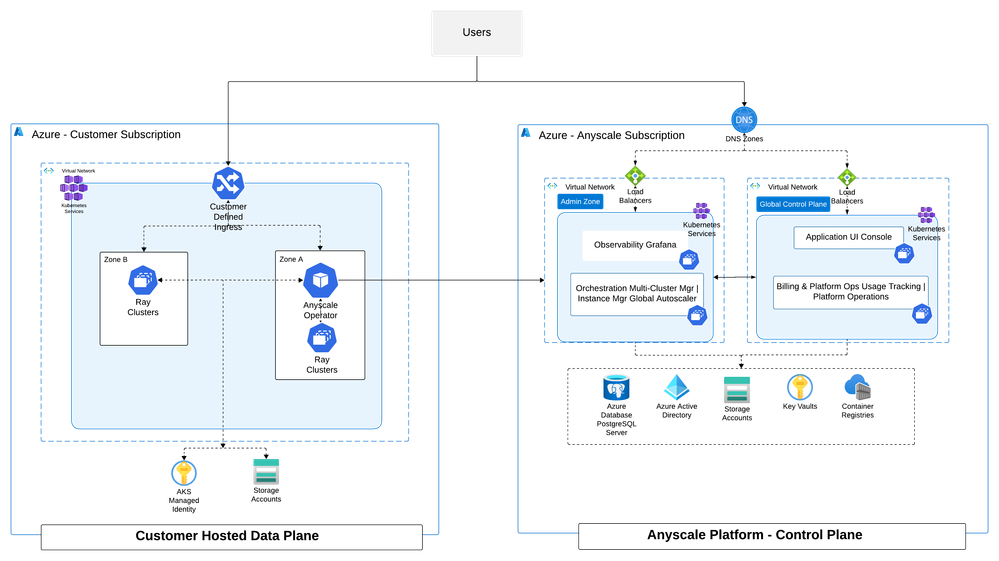
O Anyscale on Azure é um produto Azure Native — descoberto através do portal Azure e provisionado via Azure Resource Manager, com todos os recursos tagueados, escopados e sujeitos a políticas como qualquer outro na sua assinatura.
A implantação é split‑plane:
- Control plane (gerenciado pela Anyscale) — scheduling, jobs, services, workspaces e observability.
- Data plane (sua assinatura Azure) — clusters Ray rodam no seu AKS, na sua VNet, no seu storage (Azure Blob / ADLS Gen2 via BlobFuse2).
O que importa é o trust boundary — mais do que qualquer feature individual do data plane — para workloads reguladas (serviços financeiros, saúde, setor público) e qualquer empresa onde dados proprietários são a diferenciação.
O modelo de execução:
- Workloads rodam dentro do seu cluster AKS — sua assinatura, sua VNet. Pesos de modelo, dados de treinamento, KV caches, checkpoints e tráfego de inferência nunca saem do limite.
- Provisionamento é ARM‑native — recursos são tagueados, escopados e herdam Azure Policy como qualquer outro item na assinatura.
- Identidade é Microsoft Entra ID de ponta a ponta — workload identity emite credenciais de pod; RBAC governa o acesso. Sem chaves de longa duração, sem secret store paralelo.
- Controles de rede são seus — Private Link, NSGs, políticas Cilium‑based Azure CNI e chaves de criptografia gerenciadas pelo cliente via Key Vault.
- Auditoria é o Azure Activity Log — a mesma superfície que seu time de compliance já monitora.
- O Anyscale Operator é o único componente controlado pela Anyscale no seu ambiente — ele roda dentro do seu AKS, comunica‑se com o control plane apenas via egress e não aceita inbound access da Anyscale.
Resultado: código e dados ficam na sua assinatura Azure. Sua postura de compliance existente, superfície de auditoria e certificações de residência de dados são mantidas — nada novo para atestar. O faturamento passa pela mesma invoice Azure com drawdown MACC — sem segunda invoice, sem procurement paralelo.
Evidências de produção
A Xoople utiliza imagens de satélite em escala planetária com Anyscale on Azure; IA multimodal transforma dados espectrais em inteligência operacional. "Anyscale permite que nossos times foquem em modelos e resultados em vez de infraestrutura, acelerando drasticamente o caminho da experimentação à implantação" — Milos Colic, VP de Engenharia, Xoople.
A Wayve treina a próxima geração de modelos fundamentais de direção autônoma no Anyscale on Azure, rodando pipelines distribuídos de ML e dados em grandes frotas de CPU e GPU. O motor operacional é a agregação de capacidade de GPU em uma escala que nenhuma região ou cluster único consegue entregar.
Além do Anyscale on Azure, o mesmo runtime Ray é usado em produção na Cursor, Physical Intelligence, xAI, Coinbase, Bedrock Robotics e Runway. A Bedrock Robotics escalou computação 85x no Anyscale sem aumentar custos linearmente. Com mais de 12 milhões de downloads semanais (+400% YoY) e mais de 42 mil estrelas no GitHub, e agora governado abertamente sob a PyTorch Foundation (Linux Foundation), Ray está se tornando o padrão open‑source de facto — não é um runtime de um único vendor.
Qual o modelo de precificação?
O pricing é usage‑based e consolidado na mesma invoice Azure do resto da assinatura do cliente, incluindo drawdown contra compromisso Azure existente (MACC):
- Infraestrutura Azure — cobranças padrão de compute e GPU para o substrato AKS onde a workload roda, escalando diretamente com o uso real.
- Camada de serviço Anyscale — pay‑as‑you‑go através dos service meters do Azure, sem compromisso inicial, precificado por tipo de CPU, memória e GPU.
Onde o Anyscale on Azure se encaixa?
A inteligência de modelos base está convergindo. Empresas podem comprar acesso aos mesmos modelos de fronteira, então o modelo em si não é mais o fosso. O que separa as empresas que estão se destacando é a camada abaixo: quão eficientemente elas rodam o ciclo de vida completo de IA em escala, quanto de vantagem composta extraem de seus dados proprietários, e se possuem o runtime que une tudo. O Anyscale on Azure é a camada de runtime Azure Native para essa postura — trazendo o padrão de computação distribuída open‑source no qual a indústria de IA convergiu para dentro do mesmo modelo de governança, identidade e procurement do Azure que o resto do tenant.
A forma da IA empresarial está se definindo. Os times que estão se destacando não são os que alugam mais inteligência através de APIs — são os que constroem e operam sistemas de IA dentro da sua própria nuvem, com seus próprios dados, sob sua própria governança, e escalam esses sistemas no runtime distribuído aberto no qual a indústria já convergiu.
Anyscale on Azure é esse runtime, entregue como um produto Azure Native:
- Ray, em versão de produção — o padrão de computação distribuída open‑source para IA, endurecido com o Anyscale Runtime, um control plane gerenciado e observability projetada para workloads na escala de modelos fundamentais.
- Um runtime, todo o ciclo de vida de IA — preparação de dados, treinamento, fine‑tuning, reinforcement learning, inferência e workloads agentic em um único programa Python, em um único substrato, sem cola entre sistemas.
- Dentro do seu tenant Azure, no AKS que você já executa — dados, modelos e governança de propriedade do cliente. Identidade Entra, RBAC do Azure, Private Link, Activity Log audit e chaves gerenciadas pelo cliente de ponta a ponta.
- Uma única invoice Azure — pricing usage‑based através do Marketplace com drawdown MACC; sem procurement paralelo, sem segundo contrato de vendor.
Se seu time está lidando com baixa utilização de GPU, stacks fragmentadas de dados‑para‑serving, jobs de treinamento que excedem a capacidade de qualquer região única, ou custos de API hospedada que escalam mais rápido que seu uso — este é o runtime construído para esse problema.
Perguntas Frequentes
-
Como o Anyscale on Azure melhora a utilização de GPU?
Através de alocação fracionada de GPU (até 0,2 de um dispositivo), bin‑packing, gang scheduling para treinamento distribuído, preempção por prioridade e integração com spot instances com checkpoint‑aware. Clientes reportam utilização sustentada acima de 80% e redução de 40 a 60% no custo com GPU. -
Quais workloads de IA são suportadas pelo Anyscale on Azure?
São suportadas cinco categorias principais: processamento de dados, treinamento distribuído, fine‑tuning, reinforcement learning, inferência de alta taxa e execução de agentes. Tudo dentro do mesmo runtime Ray, sem necessidade de múltiplos engines. -
Como fica a segurança e a soberania dos dados?
O Anyscale on Azure é um produto Azure Native com arquitetura split‑plane: o data plane roda dentro do seu AKS, VNet e subscription. A identidade usa Microsoft Entra ID de ponta a ponta, sem chaves de longa duração. Dados, modelos e checkpoints nunca saem do seu tenant. O compliance existente (Azure Policy, Activity Log) é mantido. -
Qual o modelo de precificação?
O faturamento é usage‑based e consolidado na mesma invoice Azure, com possibilidade de drawdown contra MACC. Há dois componentes: infraestrutura Azure (compute/GPU padrão) e a camada de serviço Anyscale (priced por CPU, memória e tipo de GPU), sem compromisso inicial. -
Preciso migrar meu cluster AKS existente para usar o Anyscale on Azure?
Não. O Anyscale on Azure pode ser provisionado diretamente no portal Azure e vinculado a um cluster AKS já existente. Você configura storage e ACR, e o operador Anyscale é implantado dentro do seu cluster, comunicando‑se com o control plane apenas via egress.
Artigo originalmente publicado em Azure Updates - Latest from Azure Charts.
