

TL;DR: O ACR Artifact Cache transforma imagens e artefatos de registries upstream (Docker Hub, GitHub Container Registry, Quay, etc.) em conteúdo local servido pelo Azure Container Registry, sem que o cliente precise alterar seus pipelines. A Microsoft revela a arquitetura por trás desse cache distribuído: mais de 100 milhões de pulls por dia, hidratação assíncrona, circuit breaking contra upstreams instáveis e fallback graceful. Para empresas brasileiras que dependem de Kubernetes em produção, o ganho real é eliminar rate limits de terceiros e manter a previsibilidade do pull path mesmo quando o upstream cai.
Por: Akash Singhal, Luis Dieguez, Kiran Challa, Nathan Anderson, Tony Vargas, Caroline Barker, Ren Shao, Mabel Egba, Toddy Mladenov, Johnson Shi
O que o ACR Artifact Cache resolve na prática?
Para muitos clientes, o Azure Container Registry (ACR) é o único registry em que suas workloads confiam, mesmo quando imagens e artifacts se originam de outros registries como Docker Hub, Microsoft Artifact Registry, GitHub Container Registry, Quay, outro ACR, ou um registry privado. O ACR Artifact Cache torna esse modelo many-to-one prático ao permitir que um time de plataforma mapeie um caminho downstream de repositório ACR para um repositório upstream. Aqui, upstream significa o registry e repositório de origem que o ACR contata em nome do cliente; downstream significa o caminho voltado para o ACR de onde os clientes puxam as imagens.
Do ponto de vista externo, a experiência é a de um pull normal do ACR. Internamente, esse pull percorre a mesma plataforma multi-tenant que atende o tráfego ACR entre regiões, nuvens e data plane stamps. Esta série de artigos aborda a lacuna entre essa experiência externa simples e o sistema interno. O objetivo é mostrar o que acontece dentro do ACR, por que o sistema foi projetado dessa forma e como essas escolhas de design moldam o comportamento que os clientes observam.
Alguns detalhes de implementação foram simplificados e o sistema continua evoluindo. Os caminhos de requisição e as restrições de design são representativos, mas este artigo evita intencionalmente detalhes internos serviço por serviço que não são necessários para entender o recurso.
Para esta visão geral, o modelo mental útil é: serve now, hydrate for later (sirva agora, hidrate depois). As seções seguintes mostrarão onde esse modelo ajuda e onde ele cria pressão de engenharia.
Por que servir conteúdo upstream a partir do ACR?
Puxar diretamente de um upstream geralmente é suficiente para desenvolvimento, mas sistemas em produção precisam de garantias mais fortes no caminho do pull.
Os modos de falha são familiares a quem já operou workloads conteinerizadas em escala:
- um upstream está lento ou temporariamente indisponível
- um upstream aplica rate limits ou burst protection
- credenciais para várias fontes upstream precisam ser tratadas com segurança
- cenários ACR-to-ACR devem evitar credenciais gerenciadas pelo cliente usando managed identity
- a política de rede espera que os pulls permaneçam dentro de um perímetro de rede aprovado
- um time de plataforma deseja um catálogo compartilhado e saneado de conteúdo público para consumo interno, enquanto times individuais puxam apenas o que precisam
Vamos usar o Docker Hub como exemplo concreto. Os rate limits de pull do Docker Hub significam que usuários não autenticados e usuários Docker Personal podem esgotar seus pulls permitidos em uma janela de tempo, fazendo com que build agents compartilhados ou nodes Kubernetes recebam erros de rate limit em vez de imagens. Esse é um exemplo útil porque torna a dependência upstream visível, mas não é a história completa. O problema de engenharia mais amplo é que artifacts originados de upstream devem se comportar como dependências locais do registry assim que um cliente opta por roteá-los através do ACR.
O Artifact Cache resolve esse problema permitindo que os clientes mapeiem um namespace downstream do ACR para um namespace upstream, puxem através do ACR e permitam que o ACR materialize o conteúdo localmente à medida que é solicitado.
Um pull-through cache dentro do ACR
O Azure Container Registry opera em mais de 60 regiões Azure e 6 nuvens públicas e soberanas, atende centenas de milhares de registries e processa bilhões de requisições por dia. O Artifact Cache é apenas uma parte desse serviço maior, mas é grande o suficiente para ser um problema de sistemas distribuídos por si só: mais de 100 milhões de pulls de imagem por dia, egress em escala de petabytes, upstreams com comportamentos diferentes e clientes que esperam que os pulls do registry permaneçam previsíveis.
Essa escala importa porque o Artifact Cache não é implantado ao lado do ACR como um serviço separado. Ele faz parte do mesmo sistema de registry que atende pushes, pulls, listagem de tags, operações de catálogo, fluxos de autenticação, cenários de rede privada e outro tráfego da API do registry.
Isso significa que o Artifact Cache precisa se encaixar no modelo de recursos e no modelo de serviço de requisições existentes do ACR. Os clientes configuram cache rules e limites de autenticação através do control plane; em seguida, seus pulls são servidos através do data plane. As próximas seções seguem essas duas partes em ordem: primeiro os recursos que os clientes criam, depois o caminho runtime que esses recursos afetam.
Como o fluxo de configuração do cliente funciona?
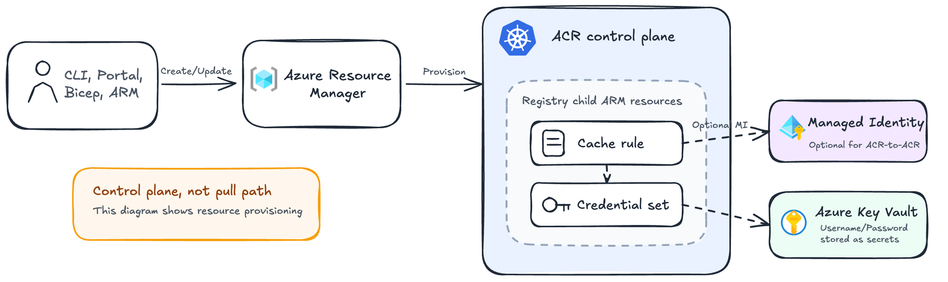
A configuração começa no control plane, onde os clientes definem o relacionamento entre um namespace ACR e uma fonte upstream.
Um cliente começa com um ACR e escolhe um repositório upstream. Nos exemplos abaixo, myregistry.azurecr.io é o login server do ACR do cliente. O caminho dockerhub/library/node é o namespace downstream do ACR que o cliente deseja usar para conteúdo em cache.
O modelo de autenticação depende do upstream:
- Para um upstream público, a cache rule pode não precisar de credenciais.
- Para um upstream privado, o cliente armazena as credenciais upstream em seu Azure Key Vault, cria um credential set que referencia esses segredos e associa esse credential set a uma cache rule. No momento do acesso, o ACR usa a system-assigned managed identity associada à cache rule para ler os segredos do Key Vault referenciados, de modo que o cliente controla o acesso concedendo as permissões necessárias a essa identity. O ACR materializa essas credenciais apenas quando precisa contatar o upstream; o Key Vault do cliente permanece como o secret store.
- Para um upstream ACR-to-ACR, o cliente pode usar uma user-assigned managed identity. Nesse cenário, credential sets não fazem parte do fluxo; a managed identity substitui o caminho do credential set e do Key Vault.
Em alto nível, o cliente define um mapeamento de namespace:
docker pull myregistry.azurecr.io/dockerhub/library/node:latest
que mapeia para:
docker pull docker.io/library/node:latest
No ACR, esse mapeamento é armazenado como uma cache rule: um recurso do control plane que mapeia um caminho downstream do ACR para um caminho fonte upstream. Se o upstream exigir autenticação, a cache rule vincula-se ao credential boundary apropriado: um credential set apoiado por segredos do Key Vault do cliente, ou uma user-assigned managed identity para ACR-to-ACR.
É aqui que a separação control-plane/data-plane se mostra. O control plane gerencia a configuração do registry através de superfícies como CLI, portal, Bicep, ARM templates e outros clientes do Azure Resource Manager. O ARM envia essas operações de recurso para o control plane do ACR, que cria ou atualiza a cache rule e, quando necessário, o credential set como recursos filhos sob o registry. Esses recursos não possuem segredos ou identidades do cliente diretamente; eles vinculam-se a recursos Azure existentes, como o Key Vault do cliente ou uma user-assigned managed identity opcional. Posteriormente, o data plane usa essa configuração persistida para decidir se uma requisição runtime do registry, como um pull ou listagem de tags, deve ser tratada pelo Artifact Cache.
Após a configuração, o caminho runtime começa com o pull mais simples possível:
docker pull myregistry.azurecr.io/dockerhub/library/node:latest
Para entender o que acontece depois desse comando, precisamos de um mapa dos componentes ACR que participam do caminho da requisição.
Quais componentes do ACR estão envolvidos?
A arquitetura necessária para esta visão geral é muito menor do que o grafo de serviços internos completo do ACR.
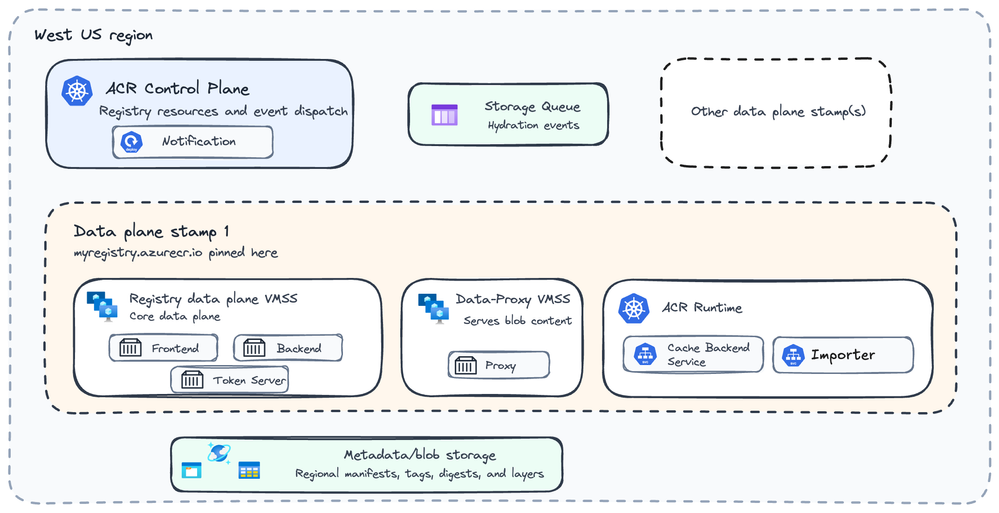
O ACR é um serviço regionalizado. O control plane opera no nível regional, enquanto os data plane stamps atendem o tráfego de registro hot-path para os registries atribuídos a eles. Um registry é fixado a um stamp, e regiões de alto tráfego podem ter mais de um stamp. A arquitetura de stamp é um conceito do ACR abordado em mais detalhes no post sobre stamp rebalancing; este artigo precisa apenas do modelo simplificado abaixo.
Para este artigo, o ACR tem três limites importantes:
- O control plane regional gerencia recursos do registry e operações de provisionamento.
- O data plane stamp atende o tráfego de registro hot-path para registries fixados naquele stamp.
- A camada de armazenamento contém metadados downstream do registry, blobs e filas de eventos baseadas em armazenamento.
Neste nível de detalhe, um data plane stamp é composto por alguns substrates runtime principais. O registry data plane VMSS (Virtual Machine Scale Set) é o core do data plane do ACR. Ele executa serviços conteinerizados, incluindo o frontend, o ponto de entrada da API do registry que recebe e roteia requisições OCI e específicas do ACR. O data proxy VMSS também executa serviços conteinerizados e atende caminhos selecionados de blob content. Ele atende tráfego elegível de blob content por trás do data endpoint dedicado do ACR. O stamp também inclui um runtime cluster para serviços adicionais do data plane, incluindo serviços que não estão no hot path.
Este artigo não explicará por que o ACR usa tanto serviços baseados em VMSS quanto um runtime cluster dentro do data plane stamp. Esse trade-off é um contexto útil, mas pertence a um mergulho separado. Para o Artifact Cache, o ponto importante é mais restrito: o stamp contém os substrates runtime que participam do atendimento do data plane, incluindo serviços do runtime cluster que processam trabalho assíncrono de import e hydration.
A lista de componentes é:
| Componente | Função |
|---|---|
| Region control plane | Gerencia recursos do registry e operações de provisionamento |
| Data plane stamp | Atende registries fixados em uma região |
| Registry data plane VMSS | Core do data plane ACR para APIs OCI e específicas do ACR |
| Frontend | Lida com tráfego da API OCI do registry dentro do data plane |
| Data proxy VMSS | Atende caminhos selecionados de blob content, incluindo o Artifact Cache |
| Runtime Kubernetes Cluster | Hospeda serviços adicionais do data plane, incluindo workers de import e hydration assíncronos |
| Cache rule | Mapeia o caminho downstream do ACR para o caminho upstream |
| Credential set ou managed identity | Fornece o limite de autenticação upstream quando necessário |
| Cache Backend service | Lida com pulls apoiados por cache rule |
| Storage queue | Recurso de armazenamento regional usado para eventos de hydration |
| Metadata/blob storage | Armazena manifests downstream, tags, digests e layer blobs |
| Import workers | Executam no runtime cluster do data plane e hidratam conteúdo downstream assincronamente |
| Upstream registry | Registry público, privado ou outro ACR usado como fonte |
O diagrama abaixo é um mapa de componentes, não um trace de pull passo a passo. Ele mostra um data plane stamp visível em West US para myregistry.azurecr.io, com um marcador suave para indicar que regiões maiores podem conter múltiplos stamps. O stamp contém um registry data plane VMSS, um data proxy VMSS e um runtime Kubernetes cluster. O armazenamento regional de metadata/blob e a storage queue ficam fora do limite do stamp. A storage queue também está fora do cluster do control plane regional; é um recurso de armazenamento consumido pelos workers do runtime cluster do data plane.
O que acontece no primeiro pull de um artifact?
Agora, voltemos ao pull request:
docker pull myregistry.azurecr.io/dockerhub/library/node:latest
A requisição chega ao data plane stamp onde myregistry está fixado. O frontend no registry data plane VMSS lida com a requisição da API do registry e a encaminha para o Cache Backend Service, que verifica se o caminho do repositório requisitado corresponde a uma cache rule.
Se não houver cache rule correspondente, a requisição segue o caminho normal do ACR. Se uma cache rule corresponder, a lógica do Artifact Cache é aplicada.
A próxima verificação é o estado local. O ACR consulta o metadata e o blob storage downstream para determinar se o manifest e os blobs requisitados já estão disponíveis localmente. Se o conteúdo estiver presente, o ACR pode servi-lo a partir do caminho downstream do registry.
Se o conteúdo não estiver disponível localmente, o ACR resolve o caminho do repositório upstream a partir da cache rule. Se o upstream exigir autenticação, o ACR usa o auth boundary configurado para aquele upstream: um credential set para upstreams privados, ou uma user-assigned managed identity para upstreams ACR-to-ACR. A requisição pode então ser servida através do data path apoiado pelo upstream, com o data proxy lidando com o caminho do blob content.
O primeiro pull não precisa esperar que a hidratação durável seja concluída antes que o cliente receba o conteúdo. Servir o pull e hidratar o registry downstream são operações relacionadas, mas deliberadamente separadas.
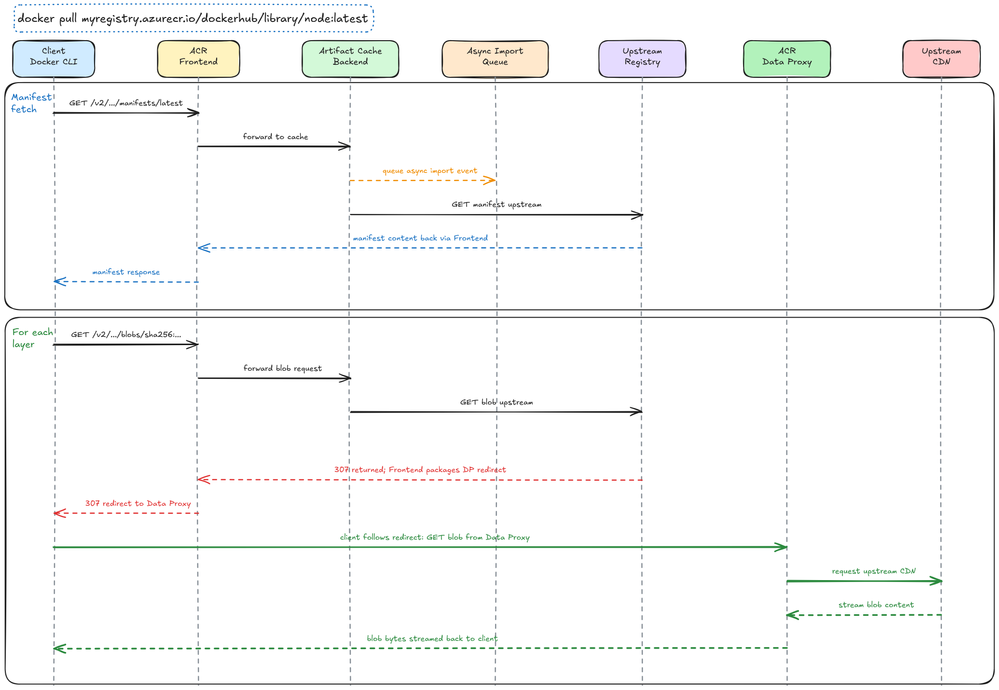
O trace acima segue a mesma imagem node:latest usada no exemplo de configuração. Em um cache miss, o data plane enfileira um evento de import assíncrono para a imagem requisitada enquanto ainda atende a requisição do cliente. O conteúdo do manifest retorna através do caminho do frontend. Para layer blobs, o frontend retorna um redirect para o data proxy, e o cliente segue esse redirect enquanto o data proxy faz streaming do blob content a partir da CDN upstream.
O data plane atende a requisição do cliente, mas também detecta que o estado downstream durável precisa ser populado. Esse trabalho durável é onde a hidratação entra.
Como a hidratação assíncrona funciona?
Hydration é o processo que materializa o conteúdo upstream no registry ACR downstream.
O ACR realiza a hidratação de forma assíncrona porque a carga de trabalho do data plane pode ser intermitente e variável. Um evento de deployment ou scale-out pode fazer com que muitos clientes requisitem a mesma imagem ainda não hidratada quase ao mesmo tempo. Tamanho da imagem, número de layers, árvores de manifest multi-plataforma, comportamento do upstream, profundidade da fila e comportamento de retry são fatores importantes em um serviço multi-tenant.
O norte é coordenar essas requisições: colapsar trabalho duplicado, hidratar o conteúdo do upstream e atender todos os clientes que esperam sem transformar uma ação de um cliente em carga upstream desnecessária. Esse problema de coordenação é desafiador na escala do ACR, e a Microsoft continua melhorando-o.
O caminho de import assíncrono existente dá ao Artifact Cache uma base durável e escalável enquanto o caminho de atendimento continua evoluindo. Em alto nível, o data plane enfileira um evento de import. Um serviço de notificação consome o evento e despacha o trabalho para import workers no runtime cluster do data plane. Esses workers buscam o conteúdo necessário do registry upstream e escrevem manifests, tags, digests e layer blobs no metadata e blob storage do ACR.
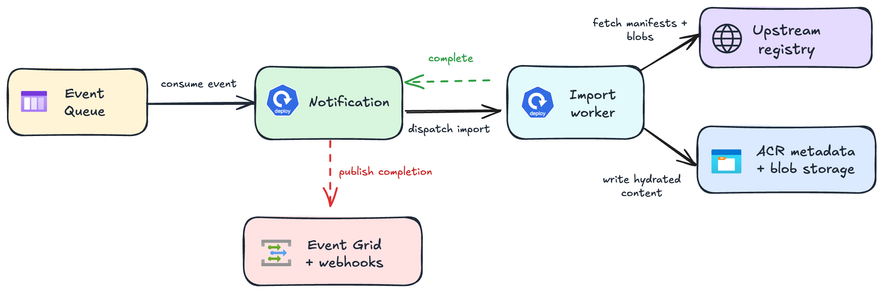
Quando os import workers concluem, eles notificam o serviço de notificação, que pode publicar sinais de conclusão através das superfícies de eventos do ACR, como Event Grid e webhooks. Isso permite que os clientes usem webhooks para detectar quando o conteúdo em cache está totalmente disponível localmente.
O modelo mental é que o primeiro pull pode servir imediatamente, enquanto a hidratação torna o atendimento local futuro durável. Um post futuro aprofundará o trabalho que o ACR faz para reduzir a carga upstream durante essa janela de hidratação.
E os pulls posteriores?
Após a hidratação ser concluída, pulls posteriores para o mesmo conteúdo podem ser servidos a partir do ACR.
Para referências de digest, o modelo é relativamente direto porque um digest é content-addressed. Se o ACR tiver o digest solicitado e seus blobs downstream, o data plane pode servir esse conteúdo localmente.
Tags são mais sutis porque tags podem mudar. Uma tag como latest é um nome que pode apontar para conteúdo diferente ao longo do tempo. O Artifact Cache, portanto, deve se preocupar com semânticas de frescor para pulls baseados em tag. Esta é uma das razões pelas quais um pull-through cache se torna mais complexo do que "fetch once and forget".
O benefício não é apenas menor latência. O ACR também reduz a dependência repetida do upstream para conteúdo que já foi materializado downstream.
Como o ACR protege o caminho do pull?
Uma vez que o conteúdo é hidratado, o ACR deve servir esse conteúdo a partir do limite do registry do cliente mesmo quando o upstream está lento, indisponível ou retornando erros. Essa distinção é importante para pulls baseados em tag: o ACR pode precisar de verificações upstream para raciocinar sobre o frescor, mas uma falha upstream não deve impedir automaticamente que o ACR sirva conteúdo que já está disponível downstream.
O Artifact Cache também deve ser cuidadoso sobre como se comporta quando os upstreams estão não saudáveis. Se um upstream começar a retornar erros 5xx ou throttling, o ACR deve evitar amplificar o problema enviando requisições acionadas pelo cliente repetidamente para o upstream. Circuit breaking e minimização de trabalho upstream são parte de ser um bom steward tanto do tráfego do cliente quanto dos limites do registry upstream. Mais detalhes virão em posts subsequentes.
Há uma questão de disponibilidade separada dentro do ACR: o que acontece se componentes específicos do Artifact Cache, como o caminho do cache backend, estiverem operacionalmente indisponíveis? O ACR lida com esse caso graciosamente, caindo de volta para o comportamento normal de pull do registry: ele verifica o estado do registry do cliente e serve a imagem se o conteúdo solicitado já existir no ACR. Em outras palavras, a indisponibilidade do cache backend não deve bloquear pulls para conteúdo já presente no registry.
O que exploraremos a seguir?
Esta visão geral é o mapa para o resto da série. Os posts seguintes aprofundarão as partes do sistema onde a pressão de design é mais alta.
Minimizando o trabalho upstream
Começaremos com como o Artifact Cache evita fazer mais requisições upstream do que o necessário.
Isso se torna difícil quando muitos clientes requisitam a mesma imagem ainda não hidratada ao mesmo tempo. Um evento de scale-out do Kubernetes é o exemplo clássico: muitos nodes podem pedir a mesma imagem concorrentemente, e o sistema deve evitar transformar a ação de um cliente em trabalho duplicado upstream desnecessário.
Tornando o Artifact Cache observável para os clientes
Também veremos como os clientes entendem se sua cache rule está saudável, se as credenciais são utilizáveis e por que um pull falhou.
Isso é difícil porque um pull com falha pode envolver configuração do cliente, acesso ao Key Vault, configuração de managed identity, credenciais upstream, disponibilidade upstream, manipulação de requisição no data plane ou hidratação assíncrona. O desafio de engenharia é expor os sinais corretos de health e debug voltados ao cliente sem transformar a topologia interna na interface do usuário.
Semânticas de repositório no Artifact Cache
Finalmente, veremos as semânticas de repositório. Uma vez que o conteúdo upstream se torna local, o repositório não é mais apenas um mirror.
Tags podem se mover upstream, referências de digest são content-addressed, e os clientes podem fazer push de seu próprio conteúdo em repositórios downstream. O estado visível do repositório pode envolver tanto conteúdo derivado do upstream quanto writes downstream de propriedade do cliente.
Conclusão
O Artifact Cache é projetado para fazer com que artifacts originados de upstream se comportem como conteúdo servido pelo ACR uma vez que os clientes escolham rotear esses artifacts através de seu registry. O objetivo de design é que os clientes possam puxar do ACR e raciocinar sobre o resultado usando os limites do ACR: configuração do registry, atendimento local, health visível ao cliente e semânticas de repositório previsíveis.
Perguntas Frequentes
-
O ACR Artifact Cache funciona com qualquer upstream, como Docker Hub e GitHub Container Registry?
Sim. O cache pode ser configurado para upstreams públicos (sem credenciais), privados (com credenciais armazenadas em Azure Key Vault) e ACR-to-ACR (usando managed identity). O mapeamento é feito via cache rule no control plane. -
Qual é a diferença entre servir o conteúdo imediatamente e a hidratação assíncrona?
No primeiro pull, o ACR serve o conteúdo do upstream em tempo real (serve now) enquanto enfileira um evento de hidratação. A hidratação (hydrate for later) materializa o conteúdo no downstream de forma durável, permitindo que pulls futuros sejam servidos localmente sem depender do upstream. -
Como o ACR evita congestionar o upstream quando muitos nós do Kubernetes puxam a mesma imagem ao mesmo tempo?
O data plane coordena requisições concorrentes para o mesmo artifact ainda não hidratado, colapsando trabalho duplicado. Um sistema de filas e import workers no runtime cluster gerencia a carga. A Microsoft afirma que está melhorando continuamente esse coordination problem. -
O que acontece se o upstream ficar indisponível ou começar a retornar erros 5xx?
O ACR aplica circuit breaking para não amplificar o problema. Se o conteúdo já foi hidratado localmente, o cache continua servindo as imagens mesmo que o upstream esteja fora. Para tags, o ACR checa freshness, mas uma falha upstream não bloqueia o pull de conteúdo já materializado. -
Como faço para monitorar se minhas cache rules estão saudáveis e por que um pull falhou?
A Microsoft reconhece que esse é um desafio — falhas podem envolver configuração do cliente, acesso ao Key Vault, managed identity, credenciais upstream, disponibilidade do upstream ou o estado da hidratação assíncrona. Futuros posts prometem expor sinais de health e debug sem expor a topologia interna.
Artigo originalmente publicado por Akash Singhal, Luis Dieguez, Kiran Challa, Nathan Anderson, Tony Vargas, Caroline Barker, Ren Shao, Mabel Egba, Toddy Mladenov e Johnson Shi em Azure Updates - Latest from Azure Charts.
