

A nova biblioteca open-source gcs-analytics-core promete reduzir em até 71% o tempo de scan de dados no Google Cloud Storage, com impacto direto na performance de workloads Apache Iceberg e Spark. Entenda os ganhos reais para empresas brasileiras.
TL;DR: O Google Cloud lançou a biblioteca open-source gcs-analytics-core para otimizar operações de leitura em data lakes baseados em GCS. Integrada ao Apache Iceberg 1.11+, ela introduz I/O vetorizado com múltiplas threads e prefetching inteligente de metadados Parquet. Em benchmarks TPC-DS, o tempo de scan caiu até 71,5% (1 GB) e o tempo de execução até 32,6%. Para empresas brasileiras que lidam com grandes volumes analíticos, a adoção pode significar redução direta de custos com compute e melhoria de SLA em consultas complexas.
Muitos engenheiros de dados gastam tempo significativo gerenciando compatibilidade e buscando melhor performance entre múltiplos analytics engines. Para ajudar a resolver esse problema, a Google anunciou a gcs-analytics-core, uma nova biblioteca Java open-source projetada para centralizar e acelerar otimizações analíticas para o Google Cloud Storage (GCS).
Com ela, você mantém a flexibilidade de escolher seu analytics engine preferido enquanto obtém alta performance no GCS. A biblioteca oferece otimizações para diversos engines que você já usa hoje no GCS, como o Iceberg Spark engine, com planos de expansão para outros até o fim deste ano.
Construída para ser compartilhada entre frameworks de processamento de dados como Apache Spark, essa biblioteca consolida e melhora a performance de workloads analíticas no GCS. Disponível nativamente no runtime Java do Apache Iceberg a partir da versão 1.11.0, ela melhora operações de leitura para formatos colunares como Parquet.
O que é a biblioteca gcs-analytics-core?
A gcs-analytics-core é uma camada de otimização centralizada que fica entre seus analytics engines — como Apache Spark, Trino e Apache Hive — e o SDK Java do GCS. Ela intercepta chamadas de leitura e injeta melhorias de performance, proporcionando uma experiência consistente sem exigir tuning específico por framework.
Para usuários do Apache Iceberg, ela se integra à implementação GCSFileIO, substituindo leituras sequenciais tradicionais por estratégias paralelizadas que minimizam latency e maximizam throughput.
Principais otimizações técnicas
A biblioteca introduz otimizações específicas para reduzir o tempo gasto em I/O e o tempo total de execução:
- Vectored I/O (threaded): Essa funcionalidade melhora a performance de leitura ao buscar múltiplos intervalos de dados em paralelo dentro de uma única operação, reduzindo o overhead de chamadas ao GCS. Sem ela, o sistema precisa emitir uma chamada separada para cada intervalo, aumentando o número de operações e a latência de arquivos abertos.
- Smart Parquet prefetching: Ao ler dados Parquet, os analytics engines normalmente fazem uma leitura inicial do footer do arquivo, que contém a estrutura de dados e informações sobre onde os intervalos específicos estão localizados. A biblioteca pré-carrega automaticamente esses dados do footer em um único chunk (tipicamente 50KB–100KB), evitando as múltiplas chamadas de rede que ocorrem quando os engines buscam metadados repetidamente.
Spotlight: integração com Apache Iceberg
A primeira grande integração dessa biblioteca foi no Apache Iceberg. Com Iceberg 1.11.0 ou superior, os analytics engines que utilizam o GCSFileIO do Iceberg podem aproveitar essas melhorias de performance. Para adotar a biblioteca no seu ambiente, verifique se seu catálogo Iceberg está configurado para usar o GCS FileIO nativo:
# Spark configuration example
spark.sql.catalog.my_catalog.io-impl=org.apache.iceberg.gcp.gcs.GCSFileIO
Como as otimizações principais estão embutidas no runtime atualizado do Iceberg e na arquitetura do conector GCS, você se beneficia automaticamente do prefetching de footer Parquet e das leituras vetorizadas multi-threaded — sem necessidade de tuning customizado complexo.
Você pode acompanhar os detalhes específicos da integração no Issue #14326 do Apache Iceberg.
Compatibilidade com catálogos
A biblioteca gcs-analytics-core é compatível com todos os catálogos Iceberg, incluindo REST catalog, Hive e outros sistemas de gerenciamento de metadados. Ao desacoplar as otimizações de performance da camada de gerenciamento de catálogo, a biblioteca oferece melhorias de leitura consistentes sem exigir ajustes na sua infraestrutura existente, permitindo escalar em diversas arquiteturas de data lake.
Benchmarks TPC-DS com Spark
Para validar essas melhorias, foram realizados benchmarks end-to-end usando um cluster Apache Spark open-source com um catálogo Iceberg configurado para usar GCSFileIO junto com a biblioteca gcs-analytics-core.
O benchmark utilizou o schema TPC-DS (padrão da indústria) em diversos tamanhos de dataset (de 1 GB a 10 TB), comparando especificamente as otimizações da nova biblioteca contra a implementação padrão do GCSFileIO, que usa leituras vetorizadas sequenciais.
Ao aliviar o gargalo de I/O na camada de storage, os compute engines gastam menos tempo esperando respostas de rede (scan time) e mais tempo processando dados (execution time).
Aqui estão os resultados end-to-end do benchmark TPC-DS mostrando a melhoria percentual ao habilitar a gcs-analytics-core:
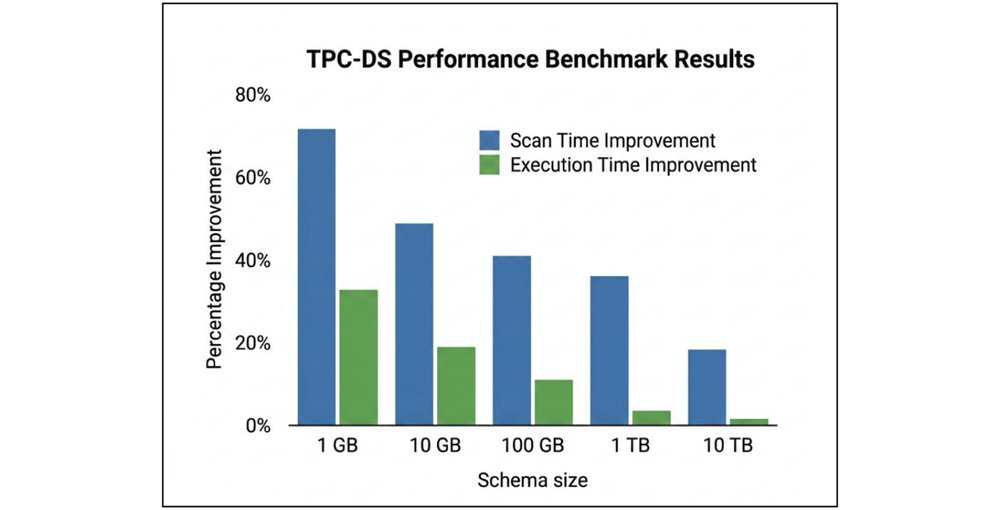
| TPC-DS schema size | Scan time improvement | Execution time improvement |
|---|---|---|
| 1 GB | 71.51% | 32.61% |
| 10 GB | 48.48% | 18.94% |
| 100 GB | 40.98% | 10.95% |
| 1 TB | 35.86% | 3.38% |
| 10 TB | 18.40% | 1.58% |
Como os dados mostram, há uma melhoria consistente em todos os tamanhos de dataset. A biblioteca é eficaz para os padrões de consulta complexa do TPC-DS, entregando reduções no tempo de scan que reduzem diretamente o tempo total de execução das queries.
Como começar a usar?
Antes de executar seus workloads Spark, confirme que os seguintes requisitos e configurações estão atendidos:
- Use Apache Iceberg Spark runtime 1.11.0+ e o iceberg-gcp-bundle 1.11.0+.
- Configure seu catálogo para usar GCSFileIO.
- Ative a flag de otimização da gcs-analytics-core (
spark.sql.catalog.$CATALOG_NAME.gcs.analytics-core.enabled=true). - Ative o I/O vetorizado (
spark.sql.iceberg.vectorization.enabled=true) para obter performance de leitura.
spark-submit \
--packages org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.11.0,org.apache.iceberg:iceberg-gcp-bundle:1.11.0 \
--conf spark.sql.catalog.$CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.$CATALOG_NAME.io-impl=org.apache.iceberg.gcp.gcs.GCSFileIO \
--conf spark.sql.catalog.$CATALOG_NAME.gcs.analytics-core.enabled=true \
--conf spark.sql.iceberg.vectorization.enabled=true \
<your-application-jar-or-script>
A biblioteca gcs-analytics-core é open-source e está disponível para contribuições da comunidade. O repositório inclui implementação e configurações de micro-benchmarks que podem ser referenciadas para suas contribuições ou validações.
- GitHub repository: GoogleCloudPlatform/gcs-analytics-core
- Documentation: Revise o design document para detalhes arquiteturais.
Queremos ouvir sobre sua experiência. Se você testar em seus próprios datasets, fique à vontade para abrir uma issue no GitHub ou compartilhar seus resultados com a comunidade.
Perguntas Frequentes
-
Preciso reconfigurar meu catálogo Iceberg para usar a gcs-analytics-core?
Não. A biblioteca é compatível com todos os catálogos Iceberg (REST, Hive, etc.). A única exigência é configurar o GCSFileIO como implementação de I/O no Spark, mantendo a estrutura de metadados existente. As otimizações funcionam de forma transparente após ativar a flag gcs.analytics-core.enabled=true. -
Quais versões do Iceberg e Spark são necessárias para usar a biblioteca?
É necessário Apache Iceberg Spark runtime 1.11.0+ e o pacote iceberg-gcp-bundle 1.11.0+. A biblioteca já vem embutida nativamente no runtime do Iceberg a partir da versão 1.11.0. Para Spark, não há restrição de versão específica além da compatibilidade com o runtime utilizado. -
Os ganhos de performance se aplicam a datasets muito grandes, como 10 TB?
Sim. Os benchmarks TPC-DS mostram melhoria consistente em todas as escalas testadas (1 GB a 10 TB). Para 10 TB, o tempo de scan reduziu 18,4% e o tempo de execução 1,58%. O ganho relativo é maior em datasets menores, mas ainda relevante em grandes volumes, especialmente quando o gargalo é I/O de armazenamento. -
A biblioteca funciona apenas com Parquet ou também com outros formatos?
Atualmente as otimizações principais — I/O vetorizado e prefetching de footer — são focadas em formatos colunares como Parquet, que é o formato mais comum em analytics engines. A Google planeja expandir o suporte a outros engines (Trino, Hive) até o fim do ano, o que pode abranger mais formatos.
Artigo originalmente publicado por Nivedita AggarwalEngineering Manager em Cloud Blog.
