

Compreender as relações subjacentes em conjuntos de dados complexos tornou-se um diferencial competitivo para a construção de aplicações inteligentes. Contudo, o cenário atual impõe um desafio operacional severo: a gestão de workloads de grafos OLTP (transacionais) e OLAP (analíticos) em silos, o que força engenheiros a gerirem pipelines frágeis e integrações custosas. Essa fragmentação não apenas eleva a sobrecarga operacional, mas atua como um teto para a escalabilidade.
A proposta apresentada com a solução unificada de Spanner Graph e BigQuery Graph endereça essa lacuna técnica, oferecendo um ecossistema coeso para navegar entre o dado em movimento e o dado histórico. Ao invés de redesenhar arquiteturas, a estratégia aqui foca na interoperabilidade, utilizando blueprints recomendados que permitem transitar entre a alta disponibilidade do Spanner e a pujança analítica do BigQuery.
Spanner Graph para workloads operacionais
O Spanner Graph redefine a gestão de grafos ao fundir capacidades relacionais, busca, e IA generativa em um único banco de dados. Para as equipes de engenharia brasileiras, o ganho de eficiência está na forma como ele lida com a escala: sem necessidade de particionamento manual e mantendo a consistência forte.
Principais diferenciais:
- Mapping Table-to-Graph Integrado: Permite modelar grafos sobre tabelas relacionais existentes, eliminando a duplicação de dados.
- Interoperabilidade GQL e SQL: O suporte a ISO GQL permite que desenvolvedores misturem pattern matching de grafos com consultas relacionais em um único comando, reduzindo a complexidade de queries.
- Integração com AI/Vector Search: A inclusão de recursos de busca semântica e Vertex AI remove a necessidade de camadas intermediárias para aplicações baseadas em IA.
BigQuery Graph para workloads analíticos
Onde o operacional para, a análise de escala começa. O BigQuery Graph leva a inteligência de grafos para dentro do data warehouse, permitindo explorar relações entre bilhões de nós sem a necessidade de migração ou ETL complexo.
A arquitetura permite aplicar a mesma linguagem (GQL) utilizada no Spanner diretamente no seu ambiente analítico. Isso garante que o conhecimento adquirido no time de engenharia de dados seja reaproveitável, reduzindo o tempo de rampa para novas análises sobre datasets históricos massivos, agora enriquecidos por funções de IA e análise geoespacial.
Spanner Graph e BigQuery Graph como solução unificada
A verdadeira potência dessa integração reside na conexão entre o real-time e o insight histórico. Em cenários de fraude financeira, por exemplo, o Spanner bloqueia a transação suspeita no checkout (edge de ação), enquanto o BigQuery identifica o padrão complexo de um cartel de fraude que opera há meses (edge de histórico).
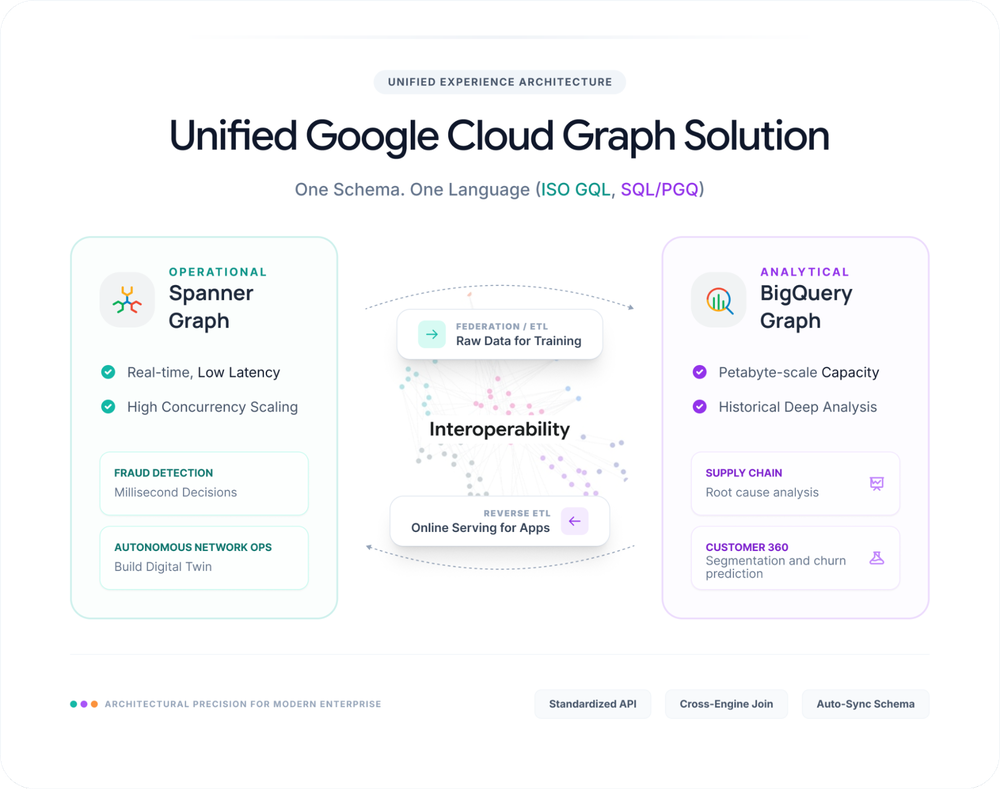
Destaques da integração técnica:
- Uniformidade de GQL: A sintaxe de consulta permanece consistente, reduzindo o custo de contexto técnico.
- Consulta via Data Boost: A capacidade de consultar dados do Spanner no BigQuery sem degradar a performance das instâncias transacionais é o divisor de águas para arquiteturas multi-tenant.
- Reverse ETL nativo: A capacidade de exportar cenários analíticos de volta ao banco de dados transacional permite que a inteligência gerada no BigQuery alimente a agilidade do Spanner.
Para visualização, o uso nativo no Spanner Studio e o suporte a notebooks facilitam a democratização do dado, enquanto integrações com ferramentas como Kineviz e Graphistry fecham o ecossistema para times de SecOps e analistas.
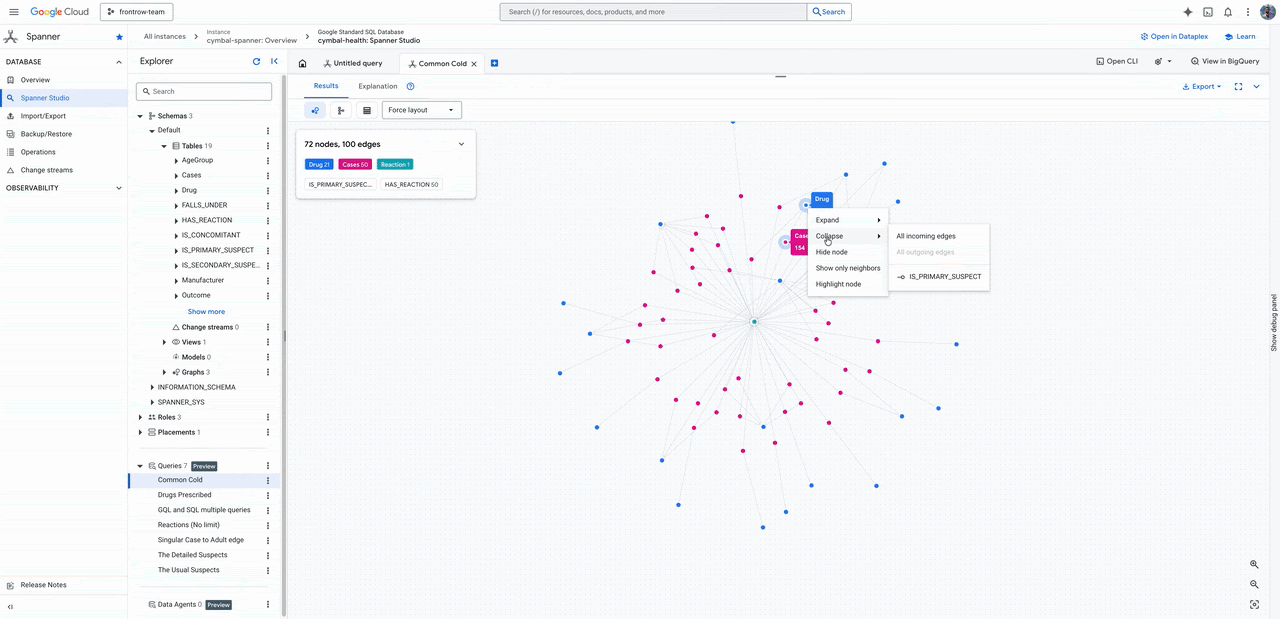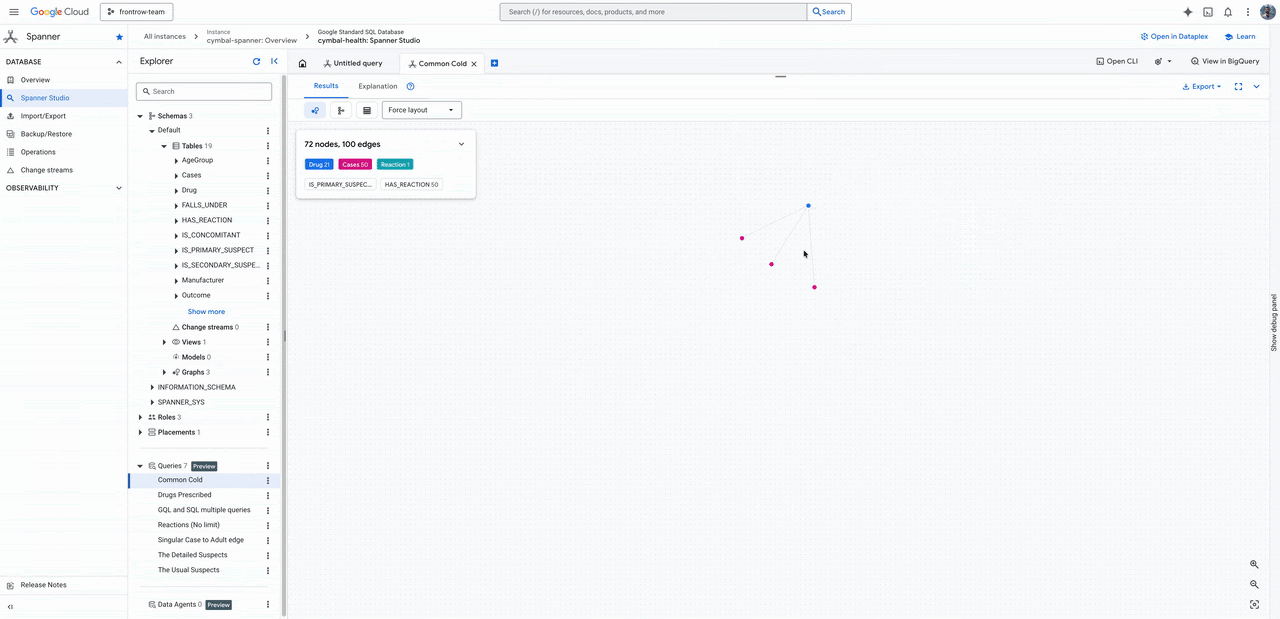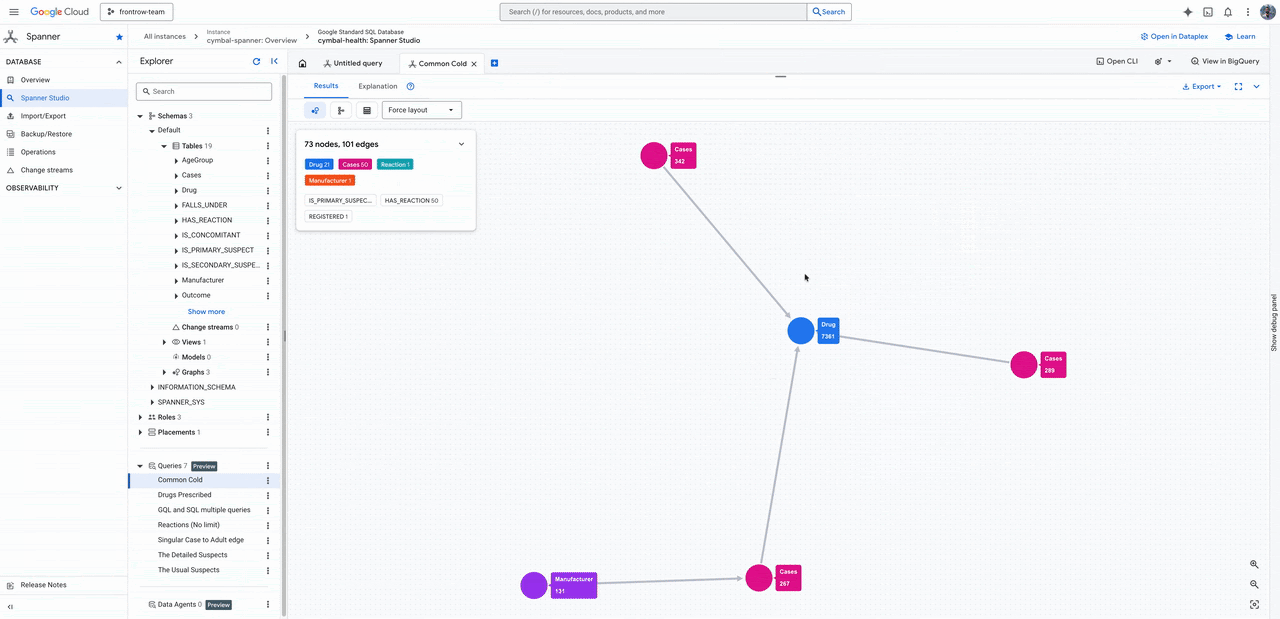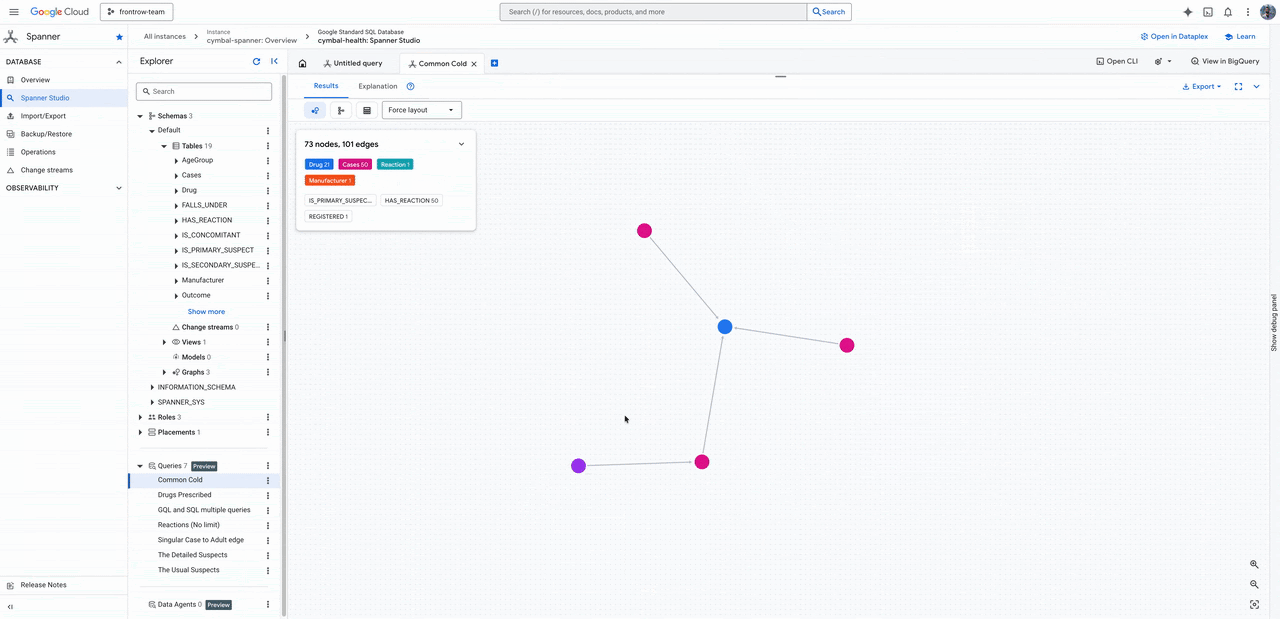
Essa abordagem unificada resolve o paradoxo da escalabilidade: você mantém a performance necessária para o usuário final, sem abrir mão da profundidade analítica necessária para o negócio. Para empresas em crescimento, este é o momento de revisar se o seu tech stack está sendo um acelerador ou, por causa de silos, uma barreira para a inovação.
Artigo originalmente publicado por Candice ChenProduct Manager em Cloud Blog.
