

TL;DR: Escolher a estratégia de contexto certa para gpt-realtime pode cortar sua conta de tokens pela metade. Este artigo compara 7 abordagens num cenário real de 10 turnos: desde o stateless (mais barato, sem memória) até o in-session delete (ideal para voz ao vivo). A conclusão principal: otimize para total de tokens, não para taxa de cache. A estratégia vencedora depende do formato da sua chamada – lookup, suporte ou escalação.
Você está rodando Azure GPT Realtime em produção?
Se sim, já se deparou com a pergunta central: como gerenciar o contexto da conversa entre turnos? Parece um detalhe de implementação, mas não é. A resposta define se o custo por chamada será 30 ou 90 centavos, se a latência do contact center fica abaixo de dois segundos e se o cliente precisa repetir o número da conta cinco vezes na mesma ligação.
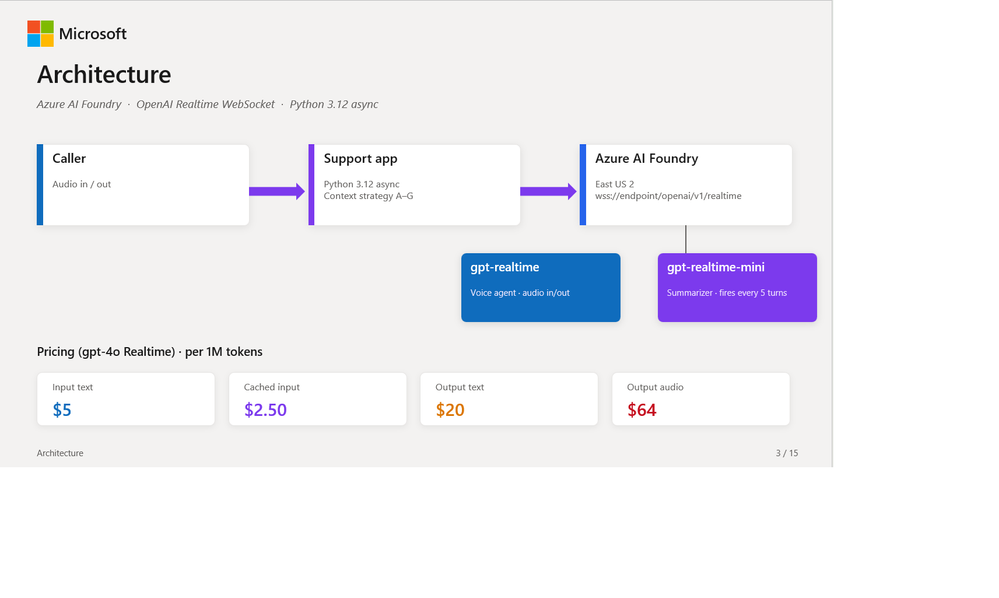
Testamos sete estratégias no Microsoft Foundry com o mesmo workload – uma conversa de 10 turnos de onboarding de paciente em um cenário de suporte healthcare. Mesmo modelo, mesma região, mesmo system prompt. Apenas a estratégia mudou.
Por que a estratégia de contexto é a alavanca?
Cada turno de uma chamada de voz em tempo real envia tokens de áudio para o modelo e recebe tokens de áudio de volta. O que você envia no turno N depende do que decidiu lembrar dos turnos 1 a N-1. Essa decisão define o volume de tokens, e o volume define a conta.
Os preços do Azure gpt-realtime na realtime API: $32/M para input de áudio, $0,40/M para input de áudio em cache (desconto de ~99%), $64/M para output de áudio. O desconto de cache é enorme – o que torna a estabilidade do prefixo crítica. As sete estratégias a seguir são essencialmente respostas diferentes para o que colocar no prefixo do prompt no turno N.
As sete estratégias
A) Full History. Um único WebSocket persistente; o servidor retém todos os itens da conversa. Turno 10 vê os turnos 1 a 9 na íntegra. Total: 18.123 tokens. Taxa de cache: 50,5% – um prefixo estável e crescente cacheia muito bem. Memória perfeita, código mais simples. Porém, a pior latência de cauda – turno 6 levou 6,3 segundos. E um WebSocket perdido destrói o contexto inteiro.
B) Stateless. Novo WebSocket por turno. Modelo vê apenas o system prompt e a pergunta atual. Total: 6.557 tokens – o piso. Taxa de cache baixa. Zero memória conversacional – útil apenas quando cada turno é independente.
C) Sliding window. Nova conexão por turno, mas injeta os últimos 2 pares Q+A. Turno 5 vê turnos 3+4. Total: 8.655 tokens. Coerência de curto prazo funciona, mas detalhes do turno 1 desaparecem no turno 5. Taxa de cache cai para 20,4% – a janela móvel quebra o prefixo continuamente.
D) Compression a cada 5 turnos. gpt-realtime-mini produz um resumo de ~70 palavras a cada 5 turnos e o injeta no system prompt; os turnos individuais anteriores são descartados. Total: 8.660 tokens. Taxa de cache: 7,1% – cada atualização de resumo invalida o prefixo. Memória semântica de longo prazo sobrevive (número da conta, queixa original). O teste de 10 turnos dispara apenas um evento de compressão; a arquitetura foi desenhada para chamadas de 30 turnos.
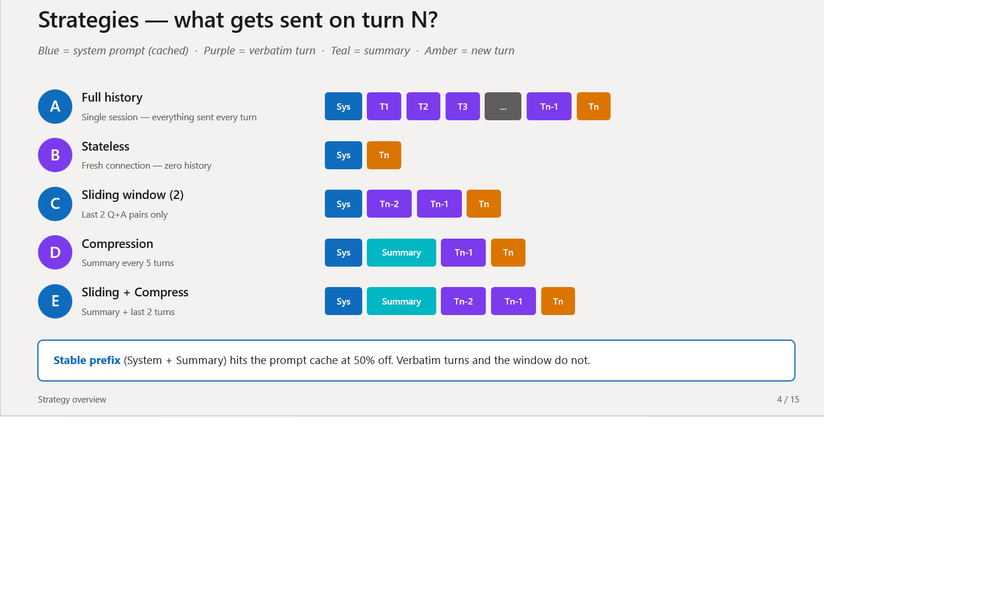
E) Sliding + Compression. O híbrido. Resumo comprimido dos turnos antigos no system prompt, mais as últimas 2 interações na íntegra. Total: 7.975 tokens – o mais enxuto entre as estratégias que preservam memória. Ambas as escalas de tempo cobertas: "você mencionou antes..." (resumo) e "espera, o que você acabou de dizer?" (janela). Taxa de cache 10,4%. Minha escolha para contact centers que toleram reconexões.
F) Server-side truncation. A estratégia "deixa a API cuidar". WebSocket persistente como no modo A, mas com uma configuração de truncation: quando o contexto pós-instruções excede 8.000 tokens, o servidor descarta os itens mais antigos, retendo 80% da janela. Nenhum código de histórico no cliente. Ficou em último: 18.247 tokens. O limite de 8K nunca disparou num workload de 10 turnos. Quando dispara em chamadas mais longas, o cache quebra e a economia é parcial. Útil como rede de segurança, não como padrão primário.
G) In-session delete. A estratégia para voz em produção. WebSocket persistente durante toda a chamada – essa é a propriedade crítica. Após cada turno, o cliente verifica response.done → usage.total_tokens. Quando excede um gatilho (usamos 600), o cliente (1) resume os turnos mais antigos em uma lista, (2) chama conversation.item.delete em cada item superseded no servidor e (3) insere o resumo como mensagem de sistema – tudo sem derrubar o WebSocket. As últimas duas interações são sempre mantidas na íntegra. Total: 14.721 tokens. Taxa de cache: 23,9%.
Volume é a alavanca, mas adequação à produção não é volume
Classificados por total de tokens: B (6.557) → E (7.975) → C (8.655) → D (8.660) → G (14.721) → A (18.123) → F (18.247).
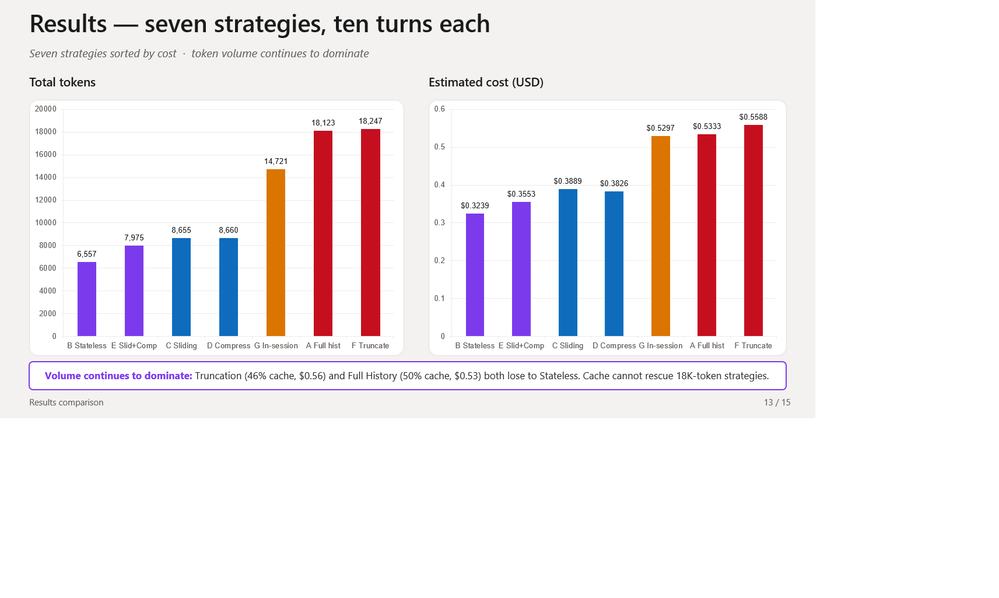
Repare em A e F – as duas maiores taxas de cache (50,5%, 46,3%) – e elas são as mais caras. Taxa de cache é métrica de vaidade. Um desconto de 50% sobre 18K tokens ainda custa mais que um desconto menor sobre 7K tokens. O número que paga a conta é total de tokens.
Mas Stateless vence em volume porque não faz a coisa difícil: não tem memória. É o padrão certo quando cada turno é independente – uma busca de medicamento por voz num farmacêutico, um check-in de adesão, um IVR de farmácia, qualquer lugar onde o workflow detém o estado e o LLM é apenas a interface de voz.
Três conclusões deste benchmark:
- Otimize para total de tokens, não para taxa de cache.
- Taxa de cache é métrica de vaidade: uma taxa alta num contexto grande é pior que uma taxa baixa num contexto pequeno.
- Escolha a estratégia mais barata que atenda suas restrições, não a mais barata no geral. Voz ao vivo precisa de G. Lookups querem B. Contact centers querem E. O ranking diz o que é mais barato; seu caso de uso diz o que é aceitável.
Princípios para implantação enterprise de voz e IA conversacional com gpt-realtime
- Comece pelo formato da chamada, não pelo ranking. Um lookup de 3 turnos, um suporte de 10 turnos e uma escalação de 30 turnos têm respostas certas diferentes – escolha a estratégia que se ajusta à sua sessão típica.
- Otimize para total de tokens. A taxa de cache parece atraente, mas só desconta a parte em cache do input; o volume total de tokens dirige sua conta e sua latência.
- Trate o system prompt como espaço sagrado de prefixo. Qualquer coisa que mude turno a turno quebra o cache para tudo depois. Coloque conteúdo estável (instruções, persona, resumo de longo prazo) primeiro e conteúdo volátil (turno atual, janela deslizante) por último.
- Decida sua postura de latência cedo. Se você tem um SLA estrito abaixo de 2 segundos, estratégias baseadas em reconexão estão descartadas – você precisa de um padrão que mantenha um único WebSocket vivo. Se reconexões são aceitáveis, você tem mais opções e geralmente pode economizar tokens.
- Use server-side truncation como rede de segurança, não como estratégia primária. Ela garante que o contexto não cresça indefinidamente, mas com thresholds padrão raramente dispara nas chamadas onde você se beneficiaria.
- Meça antes de otimizar. Instrumente contagem de tokens por turno, taxa de cache e latência de ponta a ponta em produção por pelo menos uma semana antes de escolher uma estratégia – benchmarks sintéticos (incluindo este) apenas aproximam o que conversas reais de clientes parecem.
Github
https://github.com/ganachan/gpt-realtime-context-strategies/tree/main
Perguntas Frequentes
-
Qual estratégia é mais barata em tokens totais?
A estratégia Stateless (B) consome apenas 6.557 tokens, sendo a mais econômica. Porém ela não preserva memória entre turnos, sendo adequada apenas para consultas independentes, como buscas em farmácia ou check-ins de adesão a medicamentos. -
Por que a taxa de cache é uma métrica enganosa?
Uma alta taxa de cache (ex: 50,5% no Full History) aplica um desconto de ~99% sobre a parte em cache, mas ainda assim o custo total é maior que uma taxa de cache baixa sobre um contexto pequeno. O que realmente importa é o total de tokens processados. -
Qual estratégia você recomenda para contact centers?
A estratégia Sliding + Compression (E) – com 7.975 tokens totais – é a melhor para contact centers que toleram reconexões. Ela combina um resumo comprimido dos turnos antigos com as últimas 2 interações na íntegra, cobrindo memória de longo e curto prazo. -
O que é a estratégia In-Session Delete (G) e quando usá-la?
Mantém um WebSocket único durante toda a chamada. Após cada turno, se o total de tokens ultrapassar um limite (ex: 600), o cliente resume os turnos mais antigos, exclui os itens superseded no servidor e insere o resumo como mensagem de sistema. É a escolha para voz ao vivo com SLA de latência abaixo de 2 segundos.
Artigo originalmente publicado por Gana_Chandrasekaran (Microsoft) em Azure Updates - Latest from Azure Charts.
