

Mais de 80% dos dados corporativos residem em formatos não estruturados — PDFs, e-mails, relatórios regulatórios e atas. Embora contenham informações vitais para o negócio, o acesso e a correlação desses dados em escala permanecem um gargalo operacional. A combinação do BigQuery Graph com o Kineviz GraphXR oferece uma mudança de paradigma: um fluxo de trabalho unificado que permite aos tomadores de decisão não apenas visualizar, mas interagir com relações complexas ocultas em documentos de larga escala.
Embora o Retrieval-Augmented Generation (RAG) e a vector search tenham se tornado o padrão da indústria, eles possuem limites quando o objetivo é análise de tendências, multi-hop reasoning e suporte a decisões justificáveis. É aqui que os grafos se provam fundamentais: eles adicionam camada de contexto e mapeamento de relacionamentos que o RAG puro, isoladamente, pode perder. A abordagem baseada em evidências prioriza a rastreabilidade, garantindo que cada insight possa ser auditado até a sua origem.
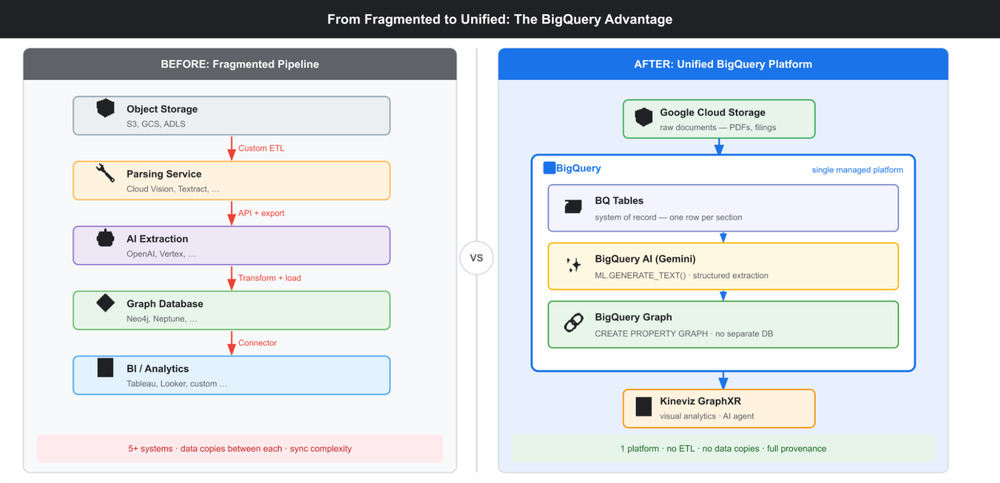
Do Fragmentado ao Unificado com BigQuery
Pipelines de analytics tradicionais costumam ser extremamente arborescentes e complexos. O cenário típico envolve object storage, serviços de parsing customizados, camadas de extração via IA, bancos de dados orientados a grafos separados e, por fim, ferramentas de BI. Essa fragmentação cria diversos pontos de falha, duplicação massiva de dados e um pesadelo de gestão de SLA e consistência.
O BigQuery simplifica essa arquitetura ao realizar a extração, a inferência via Gemini e a criação do grafo dentro da mesma plataforma. Isso elimina a necessidade de mover dados entre sistemas (egress costs) e reduz drasticamente a orquestração de serviços complexos.
Pipeline no BigQuery: De Não Estruturado para Estruturado
Na prática, exploramos arquivos SEC 10-K (declarações anuais nos EUA) de empresas da Fortune 500. O processo segue quatro etapas fundamentais, utilizando a natureza nativa do BigQuery:
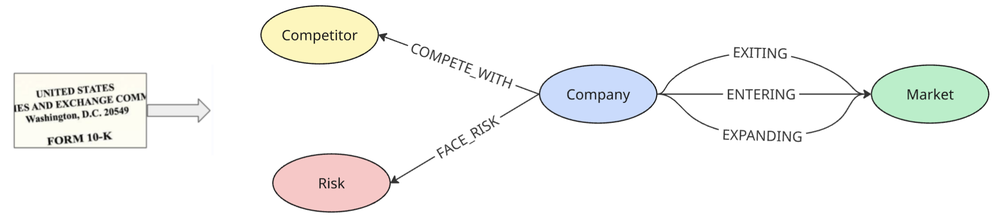
- Ingestão e Parsing: Transformação do Standard Generalized Markdown Language (SGML) para Markdown, preservando a estrutura hierárquica e carregando-o para o BigQuery.
- Foco em Sinais: Filtro das seções relevantes (Business, Risk Factors, MD&A), mantendo metadados essenciais para rastreabilidade.
- Extração via Gemini: Uso de
AI.GENERATE_TEXT()com o modelo Gemini para estruturar o texto em JSON, fundamentando cada extração com a evidência original. - Declaração do Grafo: Tradução dos dados estruturados em tabelas de nodes e edges via DDL, permitindo consultas sem a necessidade de joins exaustivos.
CREATE PROPERTY GRAPH sec_filings.SecGraph
NODE TABLES (
nodes_company, nodes_competitor, nodes_risk, nodes_market, nodes_opportunity
)
EDGE TABLES (
edges_competes SOURCE nodes_company DESTINATION nodes_competitor LABEL COMPETES_WITH,
edges_faces_risk SOURCE nodes_company DESTINATION nodes_risk LABEL FACES_RISK,
edges_entering SOURCE nodes_company DESTINATION nodes_market LABEL ENTERING
);
Insights com Kineviz GraphXR
O Kineviz GraphXR conecta-se diretamente ao BigQuery Graph, permitindo que analistas naveguem por subgrafos através de fluxos de trabalho low-code. Com a integração da IA, é possível realizar perguntas em linguagem natural — como a trajetória competitiva de uma empresa — com visualizações que atualizam dinamicamente.
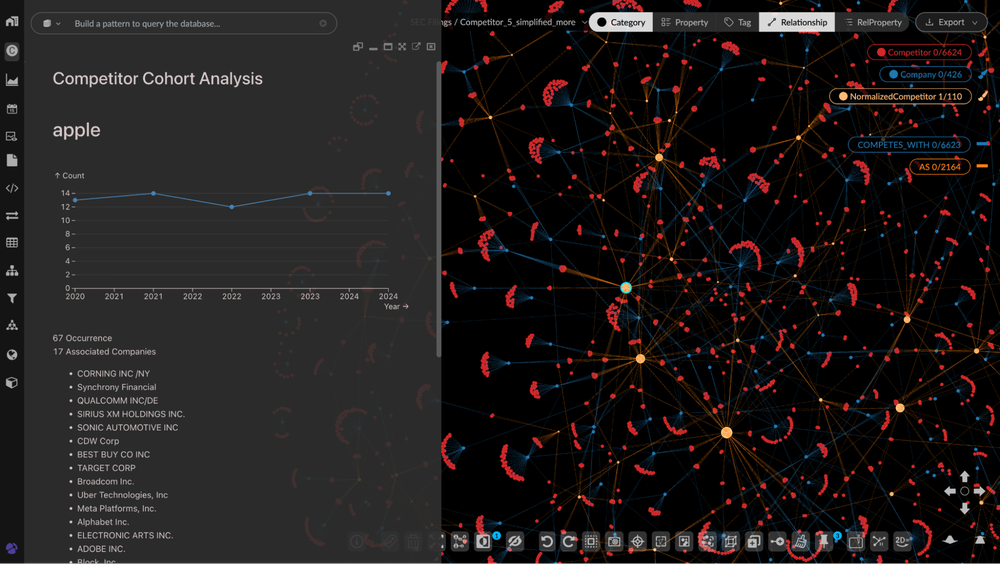
Dashboard: Empresas citando a Apple ao longo do tempo
O valor estratégico aqui reside na auditabilidade. Ao selecionar uma entidade, o analista tem a rastreabilidade imediata até o parágrafo original onde aquele dado foi extraído, algo crítico para setores fortemente regulados no Brasil, como financeiro e healthcare.
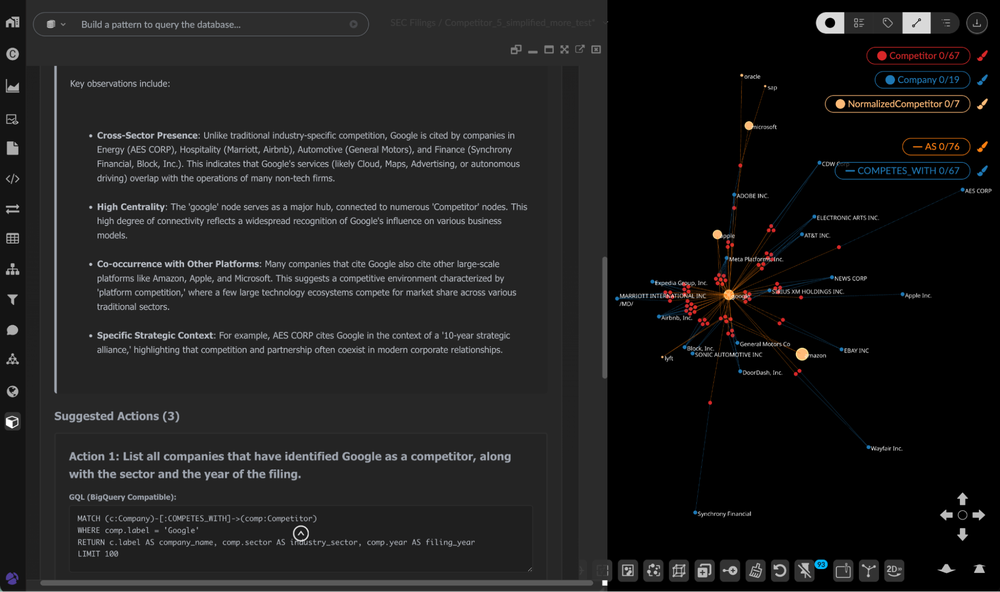
Análise competitiva com raciocínio entre estrutura de grafo e propriedades de nós
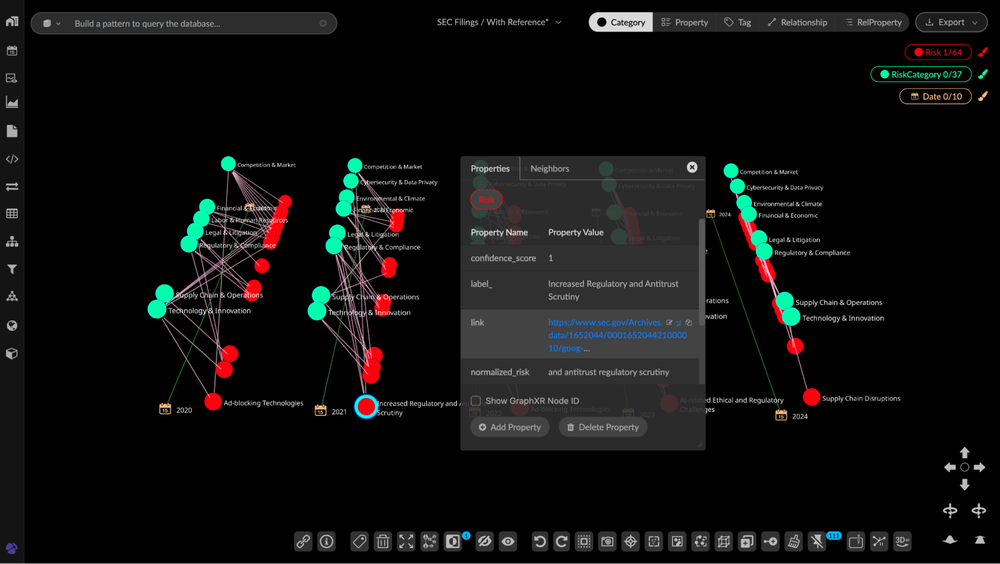
Análise de risco com link direto para o local da informação na fonte
Por que isso é relevante?
Para empresas brasileiras, a combinação BigQuery Graph e Kineviz ataca quatro pilares de eficiência operacional:
- Simplicidade: Redução de tech debt ao evitar múltiplos sistemas desconexos.
- Escalabilidade: Capacidade de processar milhões de documentos de forma gerenciada.
- Explainability: Garante que toda decisão apoiada por IA seja explicável e verificável.
- Flexibilidade: A schema permite que novos tipos de entidades sejam incluídos conforme a necessidade do negócio, sem retrabalho total.
Artigo originalmente publicado por Candice ChenProduct Manager em Cloud Blog.
