

A Google anunciou recentemente o BigQuery Graph em preview, sinalizando uma mudança clara na forma como a plataforma aborda a análise de relacionamentos em grandes volumes de dados. Para engenheiros de dados e arquitetos, o desafio de extrair insights de conexões de múltiplos níveis — o famoso "amigo de um amigo" ou o efeito dominó em uma cadeia de suprimentos — sempre esbarrou na ineficiência do SQL tradicional, que exige JOINS aninhados complexos e que degrada a performance à medida que o volume cresce.
A transição do modelo relacional para uma estrutura de grafo resolve a dificuldade intrínseca de encontrar padrões de conectividade. Porém, até agora, a adoção de tecnologias de grafos exigia a criação de silos, duplicação de dados e uma curva de aprendizado íngreme para equipes acostumadas com o ecossistema SQL. A proposta do BigQuery Graph tenta mitigar esses pontos ao incorporar a capacidade de grafos diretamente no motor de processamento do BigQuery.
Desafios de grafos na arquitetura corporativa
Empresas brasileiras, especialmente as que operam nos setores de varejo, financeiro e logística, frequentemente enfrentam três barreiras críticas ao tentar implementar análises baseadas em grafos:
- Silos técnicos: Armazenar dados em bancos de grafos dedicados forçam a replicação, gerando inconsistências e custos operacionais adicionais.
- Déficit de especialização: Exigir que times de dados aprendam linguagens de consulta proprietárias desvaloriza o capital intelectual já consolidado em SQL.
- Escalabilidade limitada: Muitas soluções de mercado falham ao tentar transitar bilhões de nós, tornando inviável o uso em escala enterprise.
O BigQuery Graph se posiciona como uma resposta a esses problemas, trazendo uma experiência unificada que permite a orquestração entre instâncias relacionais e de grafos sobre a mesma fonte de verdade, sem necessidade de data movement.
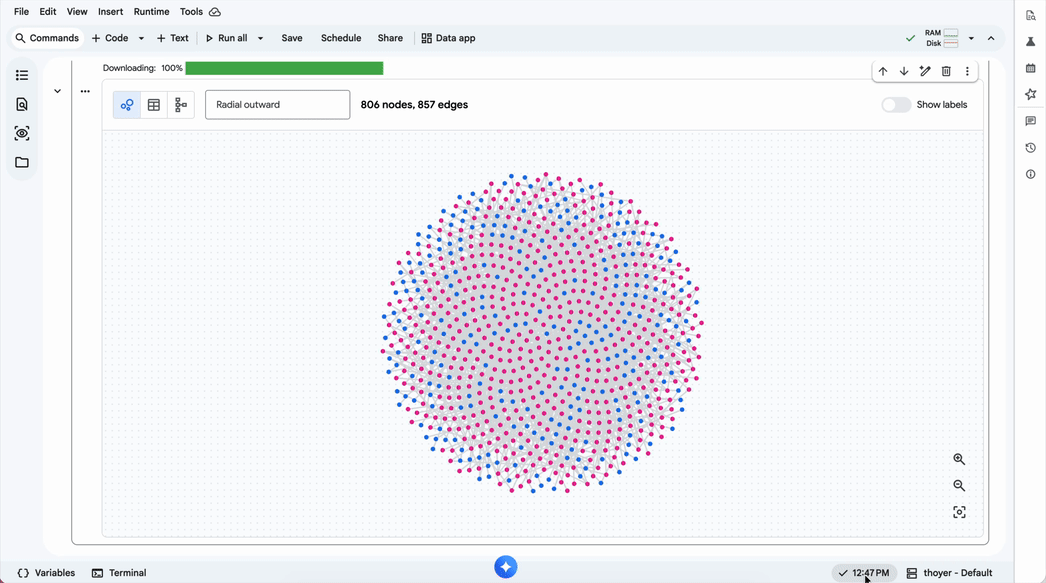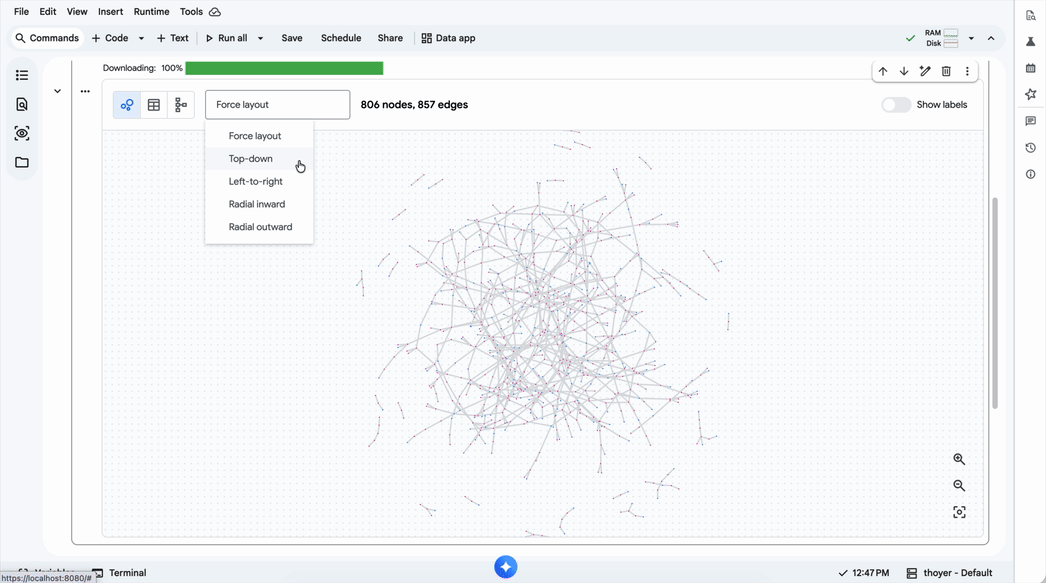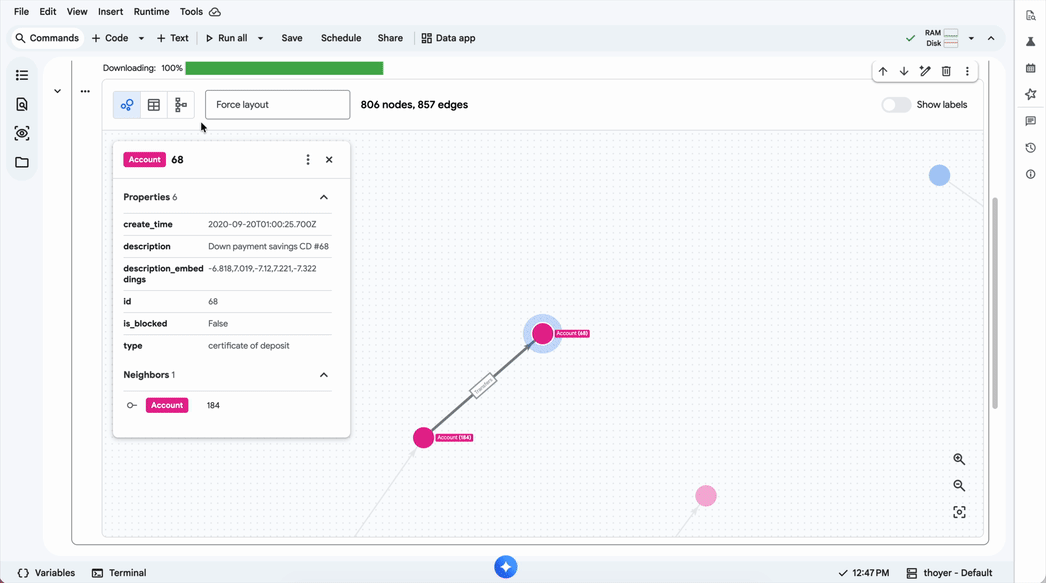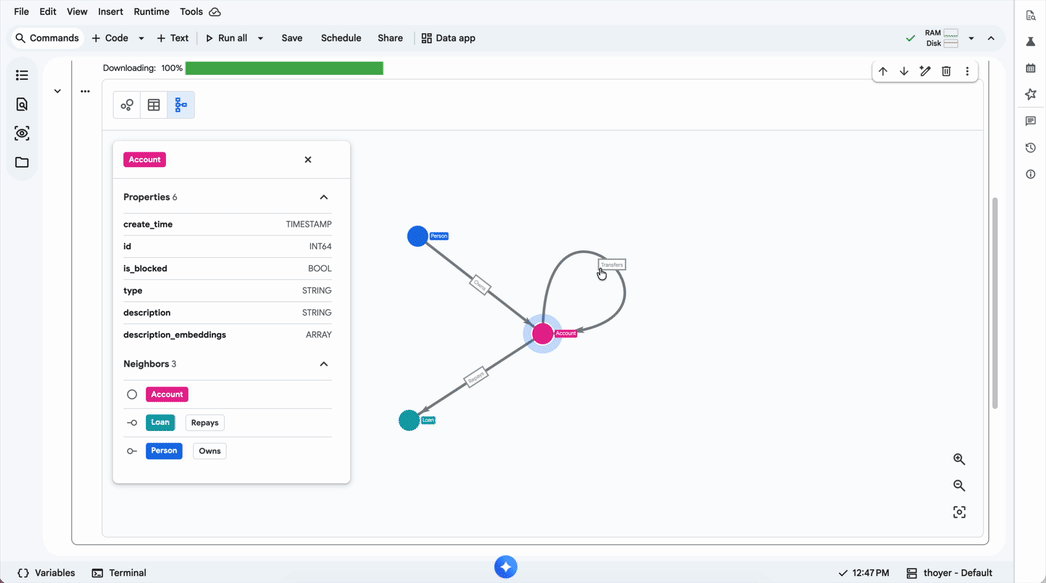
Entre as capacidades técnicas mais relevantes, destacam-se a conformidade com o padrão ISO GQL, a interoperabilidade total com SQL e a integração com vector search, permitindo que análises de grafos considerem dados não estruturados de maneira semântica.
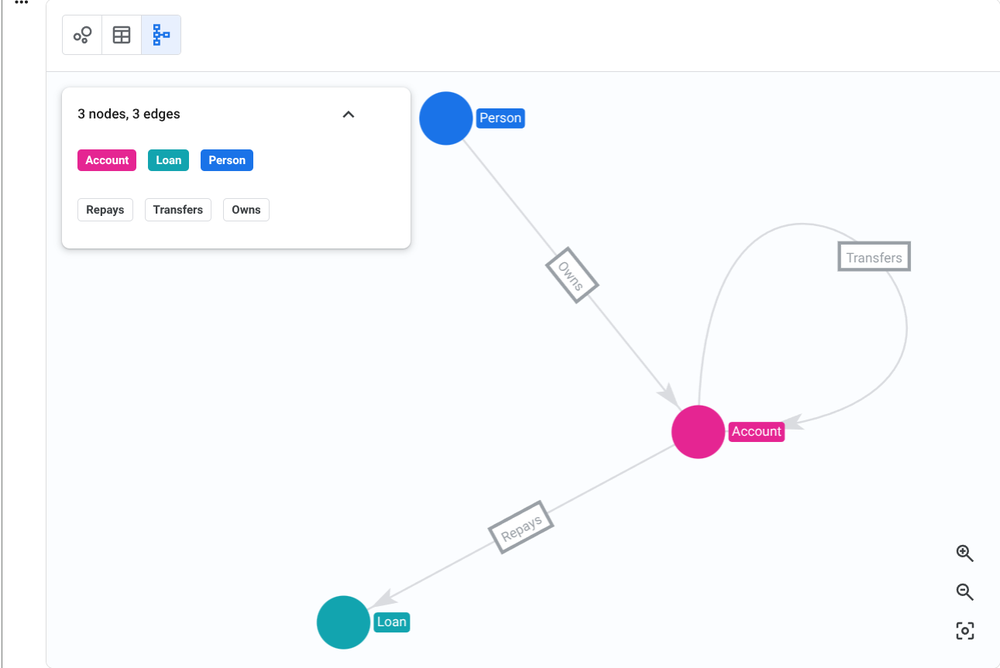
Diagrama: O modelo de grafos no ecossistema BigQuery
Implementação prática
Para o time de engenharia, a implementação segue um fluxo bastante familiar. A criação de um grafo no BigQuery utiliza DDL para definir nós e arestas:
CREATE PROPERTY GRAPH graph_db.FinGraph
NODE TABLES (
graph_db.Account KEY(id),
graph_db.Person KEY(id),
graph_db.Loan KEY(id)
)
EDGE TABLES (
graph_db.Transfers
KEY (id, to_id, timestamp)
SOURCE KEY (id) REFERENCES Account (id)
DESTINATION KEY (to_id) REFERENCES Account (id),
graph_db.Owns
KEY (id, account_id, timestamp)
SOURCE KEY (id) REFERENCES Person (id)
DESTINATION KEY (account_id) REFERENCES Account(id),
graph_db.Repays
KEY (id, loan_id, timestamp)
SOURCE KEY (id) REFERENCES Person (id)
DESTINATION KEY (loan_id) REFERENCES Loan(id)
A partir daí, a consulta de relacionamentos torna-se legível e eficiente, utilizando a cláusula MATCH do GQL:
GRAPH graph_db.FinGraph
MATCH
(person:Person {name: "Jacob"})
-[own:Owns]->(account:Account)
-[repay:Repays]->(loan:Loan)
RETURN
account.id AS account_id,
loan.id AS loan_id
Além disso, é possível realizar buscas combinadas de vector search para refinar a identificação de anomalias, como fraudes, em poucas linhas de código. Para times que possuem alta maturidade em Python/Jupyter, a visualização dos resultados pode ser feita diretamente no BigQuery Studio, facilitando a exploração visual de conexões complexas.
Visão da Nuvem Online
Do ponto de vista estratégico, a chegada do BigQuery Graph é um movimento de consolidação da plataforma como um verdadeiro Data Cloud. Para empresas brasileiras, a grande vantagem não é apenas a nova funcionalidade, mas a redução do TCO (Total Cost of Ownership) pela eliminação de ferramentas de nicho. Recomendamos que times de engenharia iniciem testes com cargas de trabalho de detecção de fraudes ou análise de rede, aproveitando o serverless do BigQuery para medir ganhos de performance sem o custo de uma migração complexa.
Artigo originalmente publicado por Vinay BalasubramaniamDirector, Product Management, BigQuery em Cloud Blog.
