

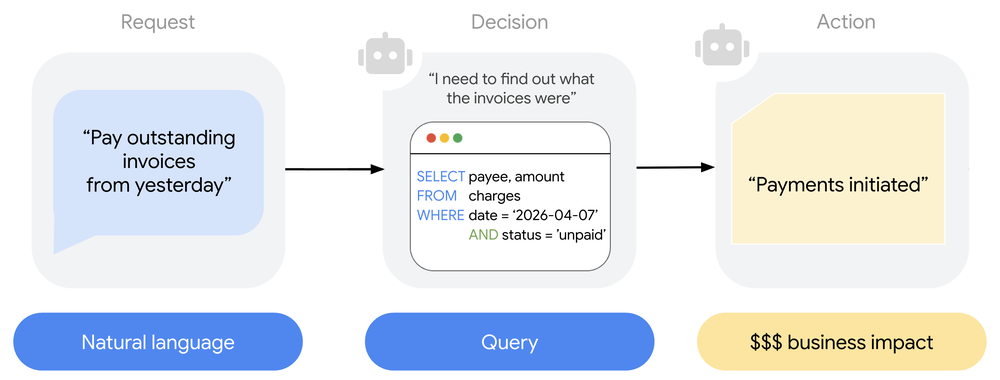
O QueryData entra em preview hoje, trazendo uma abordagem focada em transformar linguagem natural em queries de bancos de dados com um nível de precisão próximo aos 100%. A ferramenta permite estruturar experiências agentic focadas em AlloyDB, Cloud SQL (MySQL e PostgreSQL) e Spanner (GoogleSQL). A tecnologia é um desdobramento da liderança do Google no benchmark BiRD, aliando a capacidade de LLMs com um rigoroso trabalho de engenharia de contexto.
Empresas como a Hughes Network Systems já validaram a solução em produção. Para gestores e engenheiros, o valor está na transição do agente de um simples advisor para um executor de processos de negócio, onde a confiabilidade da informação — como dados de estoque ou transações — é o diferencial entre o sucesso operacional e o risco financeiro.
O desafio: Por que integrar LLMs a bancos de dados ainda é complexo?
A implementação de agentes que consomem dados enterprise trava em três pilares fundamentais: precisão, segurança e usabilidade.
- Precisão: Em muitos fluxos transacionais, uma taxa de erro de 10% é inaceitável. O sistema precisa garantir que o SQL gerado seja 100% aderente à realidade do schema.
- Segurança: Delegar o controle de acesso ao julgamento probabilístico de um LLM é um risco de conformidade grave. O acesso deve ser determinístico e auditável.
- Usabilidade: A fricção no desenvolvimento ocorre ao tentar fornecer o contexto necessário para que o modelo entenda nomenclaturas próprias do negócio.
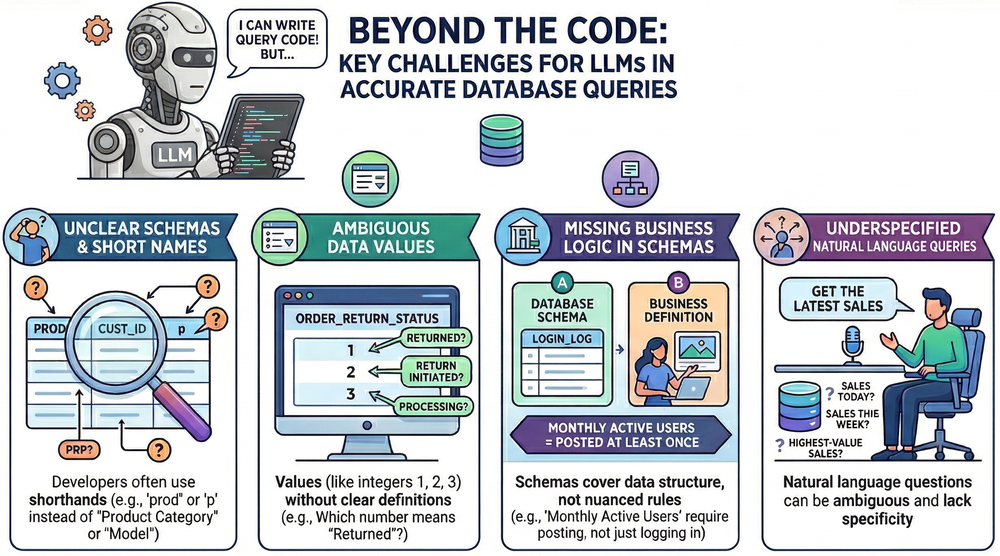
Onde a interpretação do schema falha
Mesmo modelos avançados sofrem com ambiguidades. Nomes de colunas genéricos (como "prod"), valores codificados em inteiros sem mapeamento claro e, principalmente, a ausência de lógica de negócio — como definir o que configura um 'usuário ativo' além do log no banco — criam lacunas que levam o LLM a errar a query.
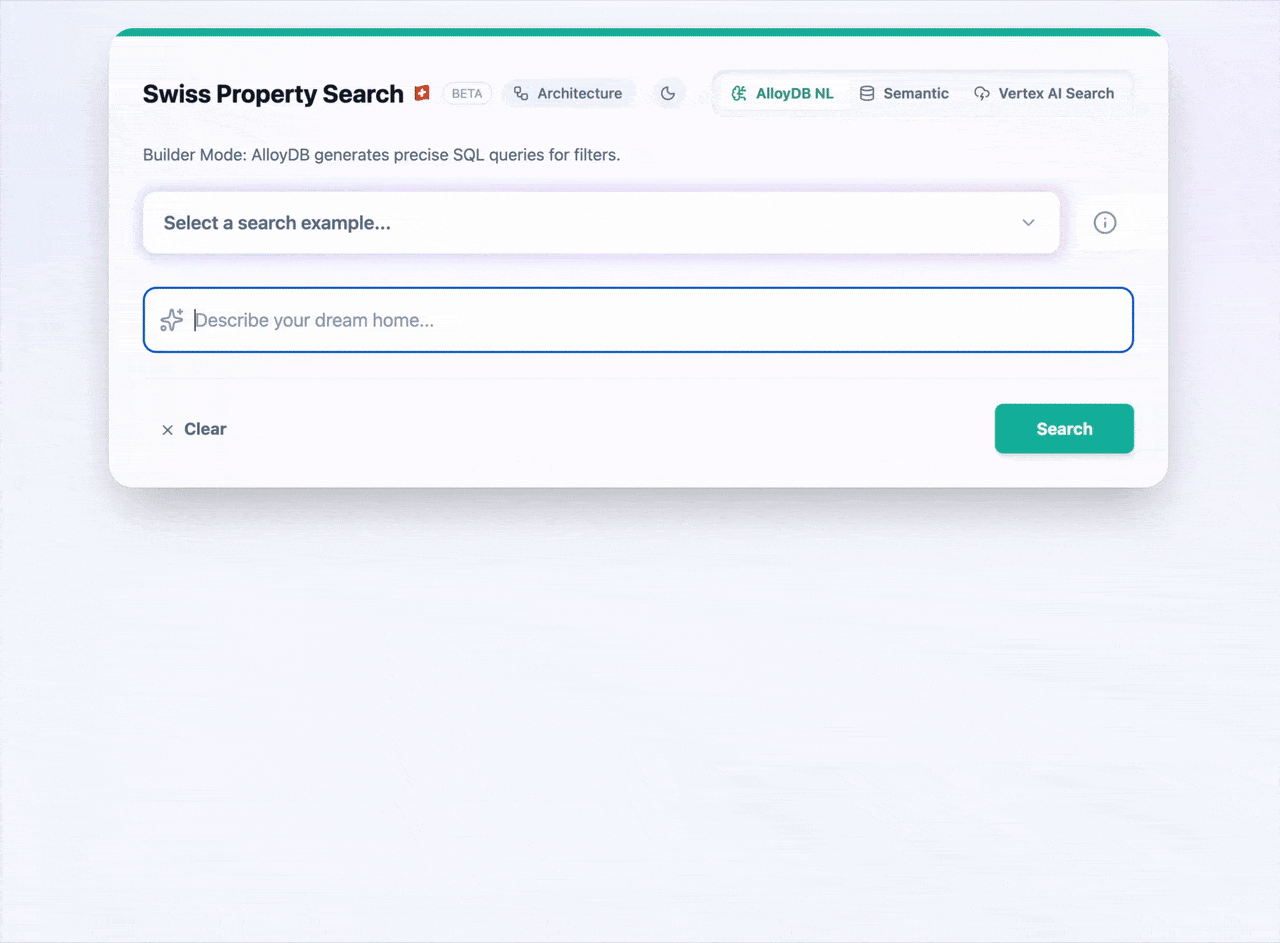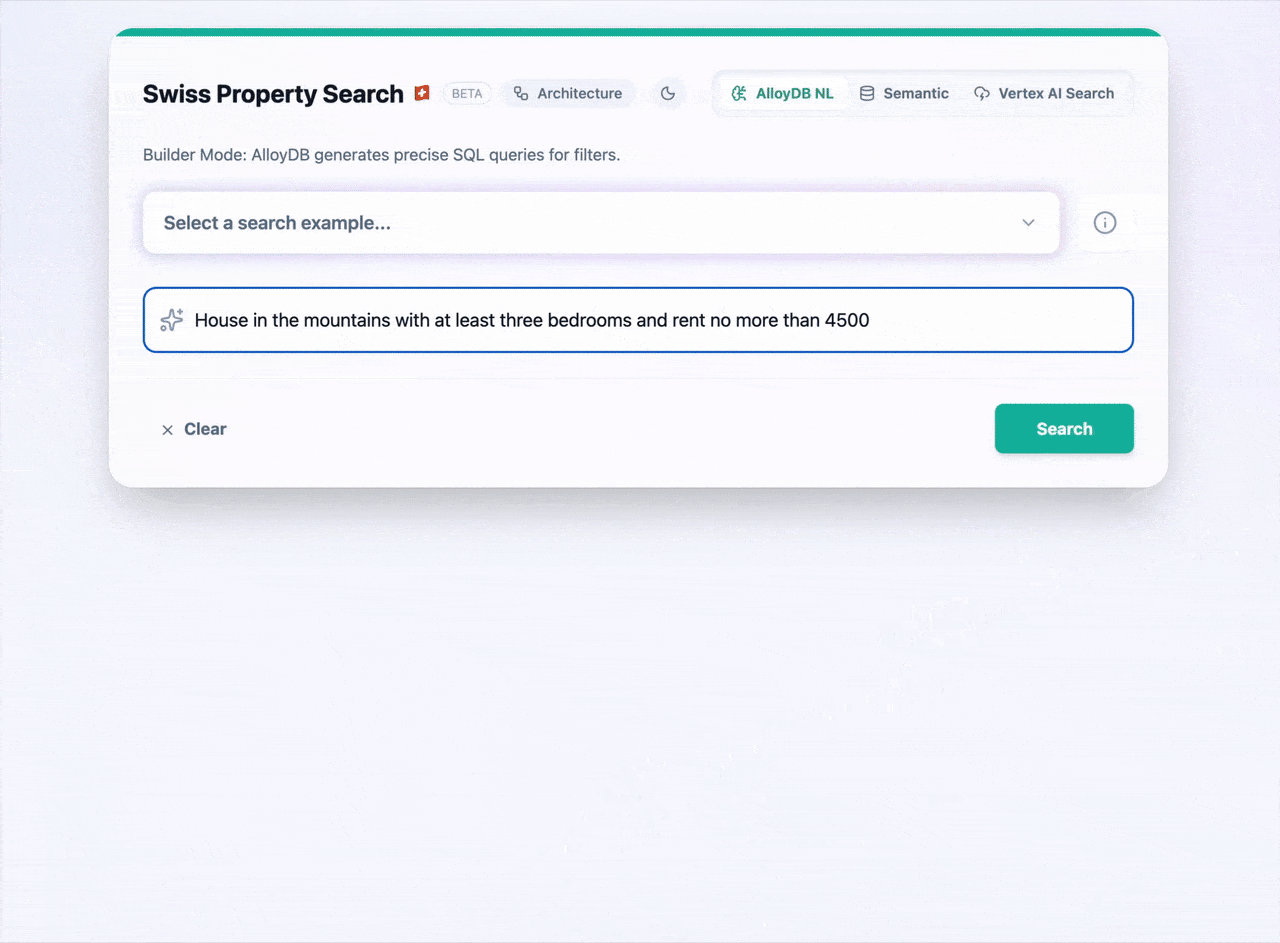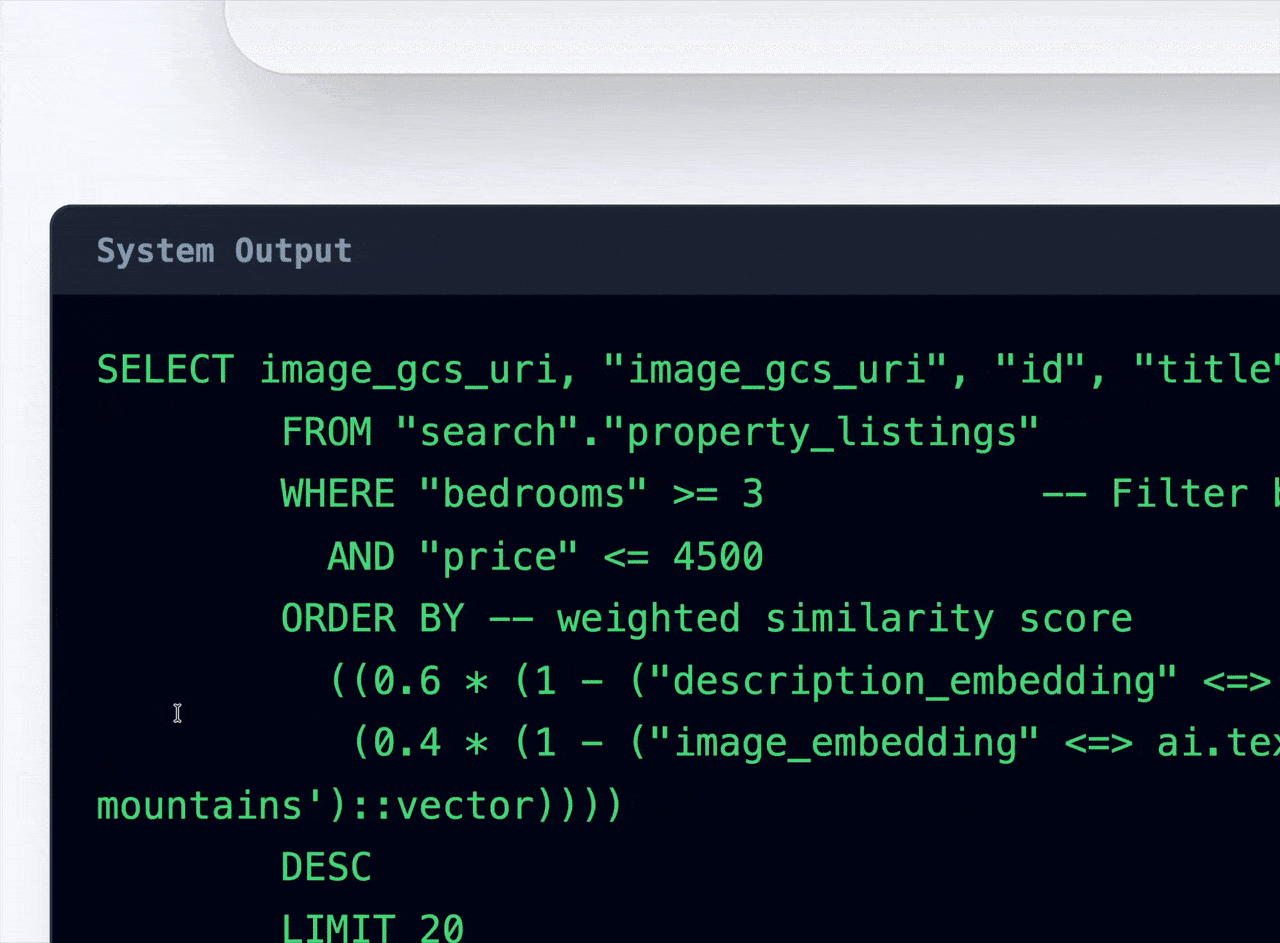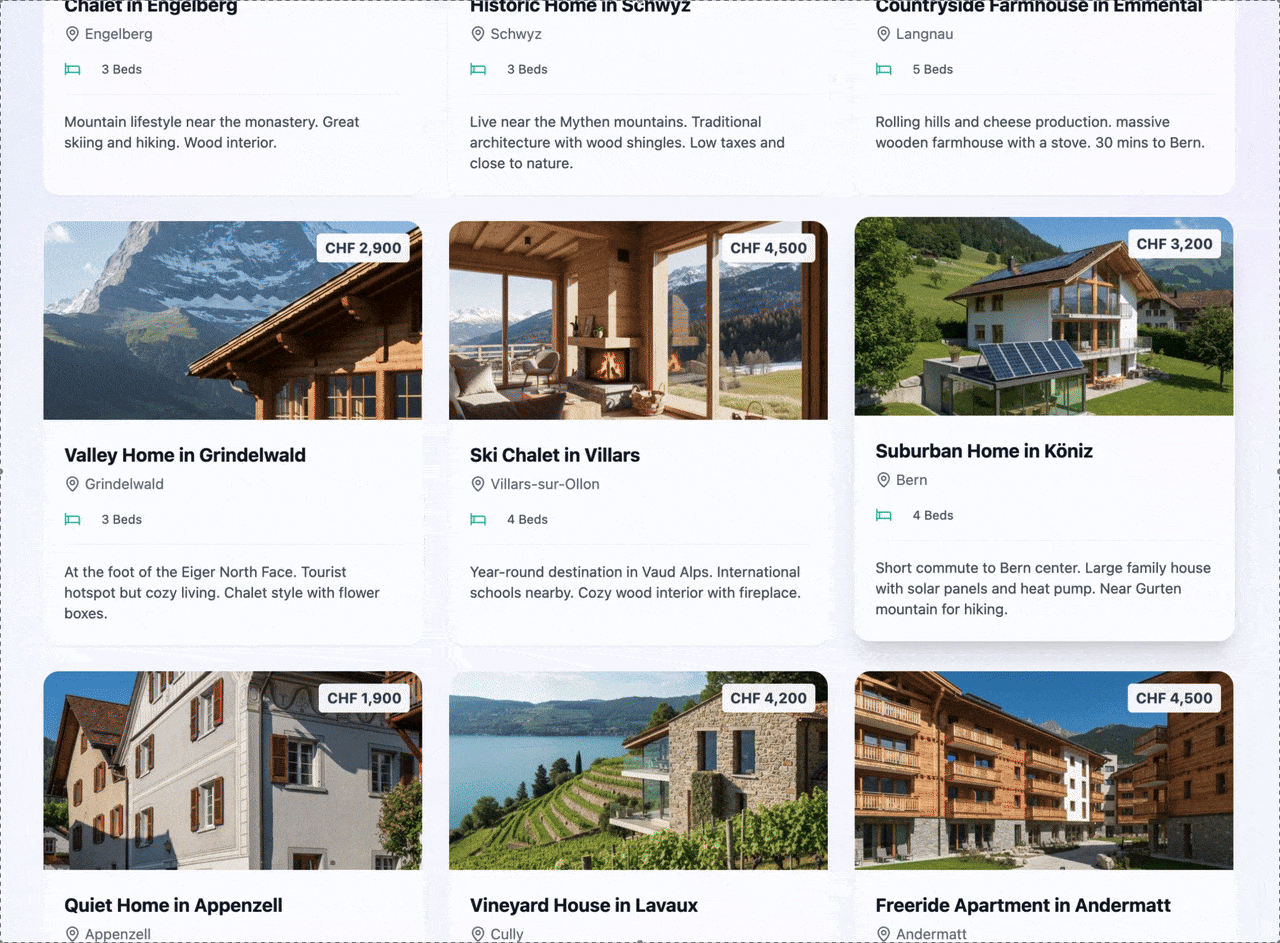
Como o QueryData resolve o gap de precisão
O QueryData não depende puramente da capacidade generativa do modelo. Ele utiliza uma camada de contexto que inclui:
- Schema ontology: Definições semânticas que eliminam a ambiguidade de colunas e tabelas.
- Query blueprints: Instruções e templates que guiam o modelo sobre como responder a classes específicas de perguntas, garantindo que o SQL gerado siga as melhores práticas da sua arquitetura.
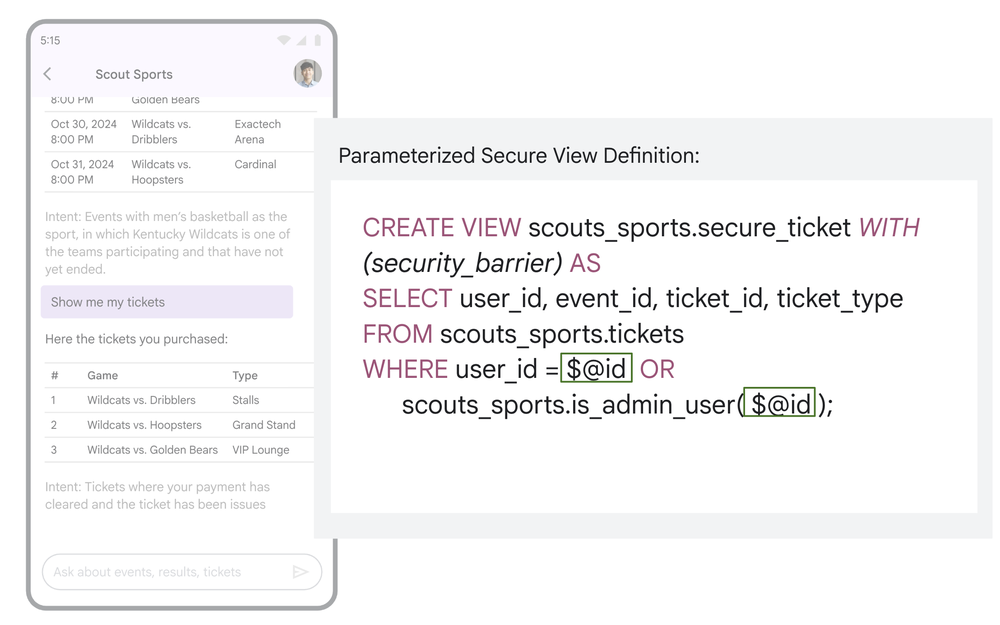
Segurança determinística
O uso de Parameterized Secure Views (PSVs) no AlloyDB (com expansão para Cloud SQL e Spanner) é uma resposta direta à necessidade de governança. Ao isolar a segurança via parâmetros de nível de infraestrutura, garante-se que, independentemente da criatividade do prompt, o agente nunca extrapole o permissionamento definido pelo IAM.
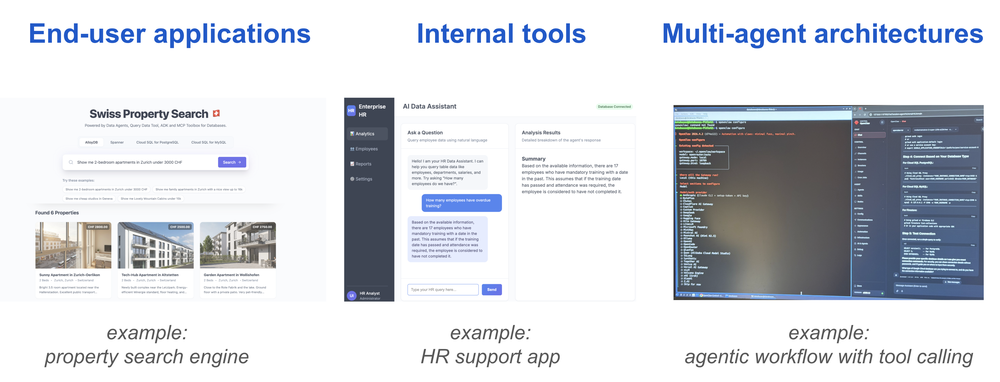
Desenvolvimento e integração
O QueryData simplifica o ciclo de vida do agente através de ferramentas como o Context Engineering Assistant e a integração nativa com o MCP Toolbox for Databases. O uso do Evalbench é, para nossos clientes, a peça chave: ele permite que as equipes de engenharia meçam a performance do agente de forma quantitativa, possibilitando um refinamento contínuo do contexto até atingir KPIs de precisão estabilizados.
Próximos Passos
A transição para sistemas agentic deve ser pautada pela resiliência da infraestrutura de bancos de dados. Se sua operação busca integrar essas ferramentas, o foco deve ser na qualidade dos modelos de dados e na governança que o QueryData agora habilita.
Artigo originalmente publicado por Andrew BrookEngineering Director em Cloud Blog.
