

Público-alvo: Arquitetos cloud, engenheiros de plataforma, líderes de engenharia tomando decisões de design
Tempo de leitura: 8 minutos
Série: Cloud Native Platforms: Build, Run, Evolve. Esta é a Parte 1 de 3.
TL;DR: Este artigo analisa as cinco disciplinas de engenharia que determinam se uma plataforma cloud-native escala ou se afoga em dívida técnica: flexibilidade, resiliência, observabilidade, práticas de entrega e disciplina de custos. A conclusão principal é que o diferencial não está no provedor cloud, mas em escolhas de design consistentes feitas cedo — como idempotência, propagação de request IDs e feature flags por tenant.
A maioria dos times de engenharia consegue construir sistemas. Poucos conseguem escalá-los sem reescrevê-los.
À medida que as plataformas crescem, a complexidade não aumenta linearmente. Ela se multiplica entre usuários, serviços, tenants, regiões e integrações. Os sistemas que sofrem e os que escalam raramente são separados pela nuvem em que rodam. São separados por um punhado de escolhas de design feitas cedo e aplicadas consistentemente.
Este post é sobre essas escolhas.
O diferencial não é a nuvem
Plataformas escaláveis não são construídas com as ferramentas certas. São construídas com as escolhas de design certas.
Os serviços cloud fecharam a lacuna de infraestrutura. O diferencial não é mais qual serviço gerenciado um time escolhe. É se a plataforma foi projetada para absorver mudanças, tolerar falhas e suportar visibilidade desde o primeiro dia. Cinco disciplinas de engenharia determinam se uma plataforma escala graciosamente ou acumula dívida técnica enquanto cresce.
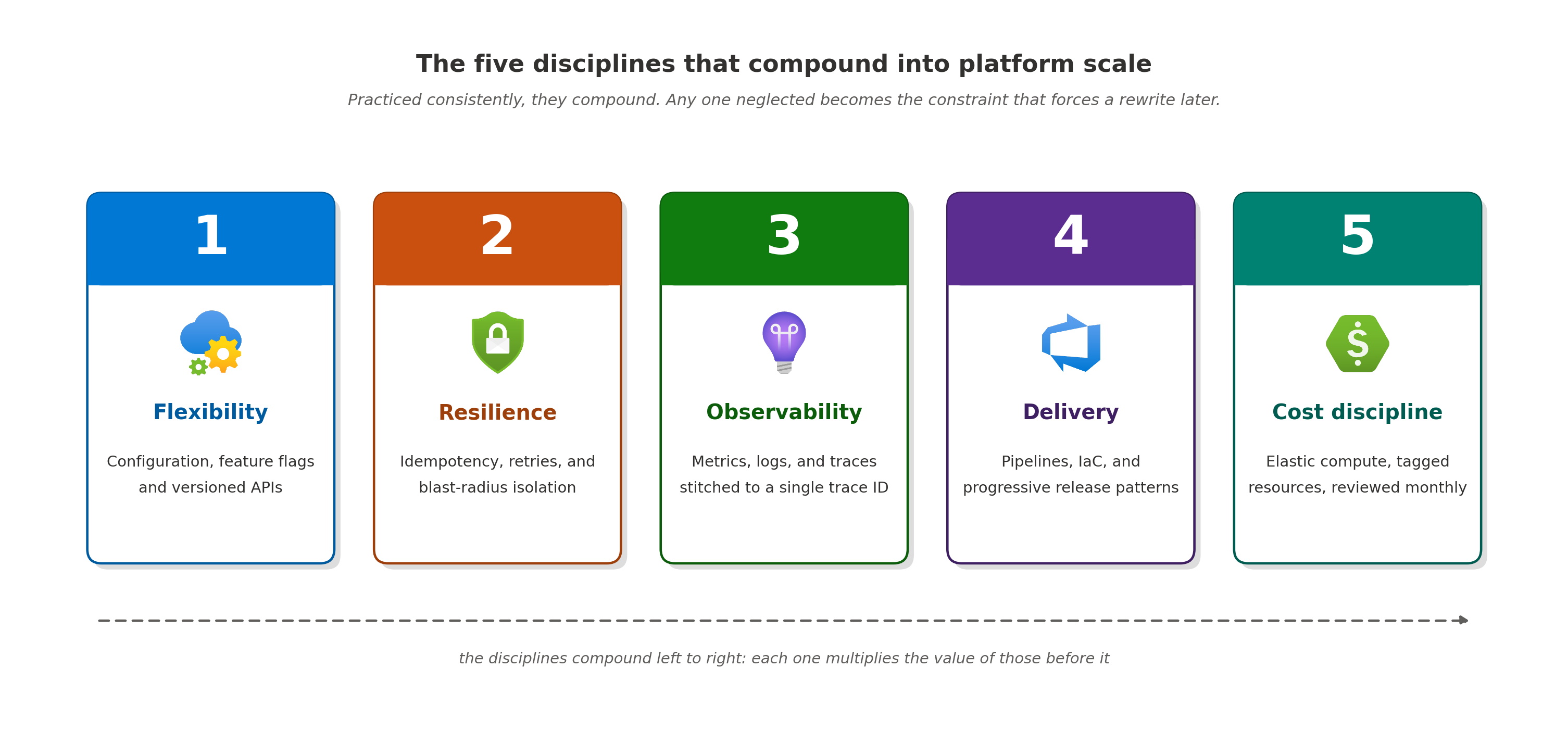
1. Como a flexibilidade se torna a base da escala?
Sistemas hard-coded funcionam até que não funcionem mais. A primeira solicitação para adicionar um tenant, uma região, um SKU (variante de produto vendável) ou uma variante regulatória é o momento em que um design rígido começa a ceder. Cada solicitação subsequente adiciona peso.
Plataformas escaláveis movem comportamento para fora do código:
- Configuration substitui lógica condicional
- Feature flags permitem rollouts seguros com escopo por tenant
- APIs evoluem via versionamento, não breaking changes
- Schemas evoluem aditivamente. Breaking changes passam por contratos versionados com janela de depreciação longa o suficiente para que consumidores migrem sem downtime.
Na prática
O padrão que funciona: configuration em um managed store, feature flags com escopo de tenant e APIs versionadas por contrato de consumidor. O custo é a disciplina de tratar configuration como código (versionado, revisado, auditado). O retorno é que releases deixam de ser eventos e se tornam rotina. Uma mudança que antes precisava de um deployment coordenado pode ser executada em minutos, restrita a um único tenant para verificação e expandida somente após o sinal estar limpo. A maioria das plataformas atinge esse estado por retrofit, não por design. Fazer isso antes custa menos do que esperar.
Se uma mudança exige um redeploy, ela deve exigir uma razão muito boa.
2. Como a resiliência é uma escolha, não um acidente?
Sistemas distribuídos vão falhar de formas imprevisíveis. A questão real não é como prevenir a falha. É como o sistema responde quando a falha acontece.
Resiliência é projetada, não herdada da plataforma. Os padrões que realmente importam são bem conhecidos e aplicados consistentemente:
- Operações idempotentes (seguras de chamar múltiplas vezes com o mesmo resultado) que tornam retries seguros
- Padrões de mensageria confiáveis, como o transaction outbox (escrever a mensagem na mesma transação de banco da mudança de negócio e depois publicar de forma assíncrona) para evitar eventos perdidos ou duplicados
- Serviços desacoplados que contêm o blast radius (o escopo do dano quando um componente falha)
- Timeouts, retries e circuit breakers (um wrapper em torno de uma dependência que para de chamá-la por um período de resfriamento após falhas repetidas) ajustados por dependência
- Bulkheads (pools de isolamento, geralmente uma lane separada de compute ou fila por classe de workload) que impedem que noisy neighbours esgotem recursos de caminhos críticos
Na prática
O padrão que funciona: toda escrita que pode ser retentada carrega uma idempotency key, todo consumidor de fila é seguro para replay, todo evento publicado passa por um outbox na mesma unidade transacional da mudança de negócio. Quando o pico de carga dispara retries, duplicatas colapsam limpa em vez de produzir pedidos duplicados, clientes cobrados em dobro ou split-brain state. O contrato muda externamente: chamadores podem retry sem pensar, filas podem ser at-least-once em vez de exactly-once, e a recuperação passa de uma tarefa manual de limpeza para uma propriedade do sistema. A maioria dos times que adota esse padrão para de ver certas classes de incidente completamente.
Nota de implementação
Uma API idempotente não é apenas uma preferência de design. Ela muda como o resto do sistema pode ser construído. Depois que escritas são seguras para repetir, retries se tornam baratos, filas se tornam confiáveis e a recuperação se torna automática.
A implementação ingênua (ler a chave, se ausente processar e salvar) tem uma race condition. Duas requisições concorrentes com a mesma chave ambas perdem o lookup, ambas chamam o processador e ambas tentam salvar. Esse é o modo de falha que a idempotência existe para prevenir. O padrão que sobrevive em produção é um atomic reserve-then-execute: inserir uma linha chaveada pela idempotency key com unique constraint antes de fazer qualquer trabalho. O primeiro escritor vence. Chamadores concorrentes ou aguardam o original completar e leem seu resultado, ou recebem uma resposta 409 Conflict.
// Contract for the idempotency store. The two key methods are TryReserveAsync
// (atomic insert with unique-key constraint) and CompleteAsync (record the
// result of the first writer). GetCompletedResultAsync polls until the first
// writer commits or returns 409 Conflict if the in-flight window exceeds the
// configured deadline.
public interface IIdempotencyStore
{
Task<Reservation> TryReserveAsync(
string idempotencyKey, string requestHash, CancellationToken ct);
Task CompleteAsync(
string idempotencyKey, OrderResult result, CancellationToken ct);
Task<OrderResult> GetCompletedResultAsync(
string idempotencyKey, CancellationToken ct,
TimeSpan? maxWait = null);
}
public readonly record struct Reservation(
bool IsFirstWriter, string RequestHash);
// Idempotency via atomic reserve-then-execute.
// First writer wins; replays return the original result; concurrent
// duplicates lose the race and read the winner's outcome (or get 409).
public async Task<OrderResult> CreateOrderAsync(
Order order, string idempotencyKey, CancellationToken ct)
{
var requestHash = StableHash(order); // canonical content hash
// Atomic insert: succeeds for the first caller, fails for the rest.
var reserved = await _store.TryReserveAsync(
idempotencyKey, requestHash, ct);
if (!reserved.IsFirstWriter)
{
if (reserved.RequestHash != requestHash)
throw new IdempotencyKeyReusedException();
// A previous run committed (return its result) or is in-flight
// (poll with a bounded deadline; 409 if exceeded).
return await _store.GetCompletedResultAsync(
idempotencyKey, ct, maxWait: TimeSpan.FromSeconds(5));
}
// We are the first writer. Execute, persist, mark complete.
var result = await _processor.ProcessAsync(order, ct);
await _store.CompleteAsync(idempotencyKey, result, ct);
return result;
}
Três detalhes de produção importam:
- TTL ou compactação no registro de idempotência. Sem isso, o store cresce para sempre. A maioria dos times retém registros pela janela de retry da requisição mais uma margem de segurança (comumente 24 a 72 horas).
- Stable content hash, não o código hash padrão do objeto. O hash da requisição detecta reuso de chave com um corpo diferente, para que um cliente que reutilize uma idempotency key com payload diferente receba
IdempotencyKeyReusedExceptionem vez de silenciosamente obter o resultado errado. Canonicalize a ordem dos campos, locale e tratamento de null antes de hashing. - Limite explicitamente a janela in-flight. O caso genuinamente difícil é quando o processador teve sucesso mas a escrita no store falhou. Implementações de nível de produção ou rodam o side-effect e a escrita no store na mesma transação (quando o processador e o store compartilham um banco) ou usam o padrão transaction outbox para fazer a ponte. O poll-with-deadline em
GetCompletedResultAsynctrata o caso de duplicata chegando durante o voo; o limite transacional trata todo o resto.
3. Por que a observabilidade não é opcional?
Sem observabilidade, times operam no escuro. À medida que os sistemas crescem, o preço de adivinhar sobe mais rápido que o preço de enxergar.
No momento da construção, observabilidade é uma propriedade de design. As decisões tomadas antes de o sistema chegar em produção determinam se ele pode ser operado de alguma forma. Os dashboards, alertas e práticas de incidentes cobertos na Parte 2 desta série dependem das escolhas de instrumentação feitas aqui.
O trabalho em build que compensa em produção:
- Request identifiers propagados por cada hop de serviço, cada fila, cada boundary assíncrono, para que uma única ação de usuário possa ser rastreada de ponta a ponta
- Structured logging com um schema consistente (event name, correlation id, tenant, severity) em vez de strings livres
- Métricas emitidas nas fronteiras que importam (toda chamada externa, toda leitura ou escrita de fila, toda operação de banco), não apenas no ponto de entrada
- Bibliotecas de tracing integradas na camada de framework ou middleware para que a cobertura seja automática, não opt-in
- Schemas projetados para que sinais de negócio (pedidos, sessões, transações) e sinais de sistema (CPU, latência, erros) compartilhem os mesmos identificadores e possam ser correlacionados depois
Na prática
O padrão que funciona: um único request id fluindo por cada hop de serviço, cada fila, cada boundary assíncrono, propagado automaticamente na camada de framework em vez de por chamada. Adicione um schema de structured logging uniforme entre serviços (event name, correlation id, tenant, severity), para que uma única consulta junte eventos de negócio com eventos de sistema. O investimento são horas de configuração inicial de framework. O retorno é que o diagnóstico de produção deixa de ser arqueologia. Perguntas cross-service viram dashboards únicos; postmortems encolhem de dias para horas; e os dashboards da Parte 2 funcionam de verdade porque os dados subjacentes estão moldados para suportá-los.
4. Como as práticas de entrega definem o teto?
Escalar times requer escalar a entrega. Pequenas ineficiências em pipelines, ambientes e coordenação de releases se combinam em arrasto mensurável.
Maturidade de entrega que compensa em escala:
- Pipelines as code, revisados e versionados como código de aplicação
- Deployments paralelos entre serviços e regiões onde as dependências permitem
- Infrastructure as code com módulos compartilhados, não ambientes gerenciados manualmente
- Quality gates automatizados: testes, scans de segurança, verificações de dependências
- Trunk-based development (desenvolvedores commitam em um único branch compartilhado muitas vezes ao dia) com feature branches curtas e entrega progressiva. Caveat importante: trunk-based só funciona quando automação de testes e feature flags já estão em vigor. Adotá-lo antes dessas fundações existirem tende a amplificar incidentes de produção em vez de reduzi-los.
Na prática
O padrão que funciona: pipelines rodam em paralelo onde as dependências permitem, provisionamento de infraestrutura é templatizado em vez de por ambiente, e quality gates rodam automaticamente em vez de como passos discricionários. Deployment sequencial de uma plataforma multi-serviço em três ambientes leva horas; deployment paralelizado da mesma mudança leva minutos. O retorno não é apenas velocidade de release. É a redução de custo composta de todo estado de espera para cada engenheiro em cada release. Times que tratam pipelines como um feature de produto, não um pensamento posterior, entregam com mais confiança e se recuperam de mudanças ruins mais rápido porque o caminho de rollback foi exercitado, não inventado durante um incidente.
Pipelines lentos não são um problema de ferramentas. São um problema de design.
5. Por que a disciplina de custos é trabalho de engenharia?
Plataformas cloud podem se tornar caras rapidamente quando o custo é tratado como problema de outro. Custo é uma propriedade do design, não uma revisão trimestral.
Os times que acertam isso tratam custo da mesma forma que tratam performance:
- Tiers elásticos de compute e storage escolhidos por padrão de workload
- Ambientes não produtivos com janelas automáticas de scale-down (a economia mais fácil de deixar na mesa)
- Disciplina de tagging para que o custo possa ser atribuído a um serviço, feature ou tenant
- Decisões de egress e data tier, não compute, dominam as contas cloud a partir de certa escala. Ajuste os tiers de storage (hot vs cool vs archive), elimine chatter cross-region e fique de olho no egress no data plane mais de perto do que no compute no caminho da requisição.
- Budgets e alertas de uso conectados nos mesmos canais que alertas de confiabilidade
- Revisões de custo incorporadas nas discussões de design, não adiadas para FinOps (Financial Operations: a prática de gerenciar gastos cloud como uma preocupação de engenharia)
Na prática
O padrão que funciona: ambientes não produtivos escalam automaticamente para baixo fora do horário comercial, tiers de storage correspondem a padrões de acesso (hot, cool, archive), e tagging é imposto para que cada dólar possa ser atribuído a um serviço ou feature. Revisões de custo acontecem no momento do design, não depois que a conta chega. As maiores economias vêm de decisões no data plane, não de compute: egress cross-region, tiers de storage superdimensionados e ambientes de teste esquecidos dominam as contas cloud a partir de certa escala. Trate custo como um requisito não funcional de primeira classe, ao lado de latência e disponibilidade, e a disciplina se compõe em cada discussão de design que se segue.
Um cenário que amarra tudo
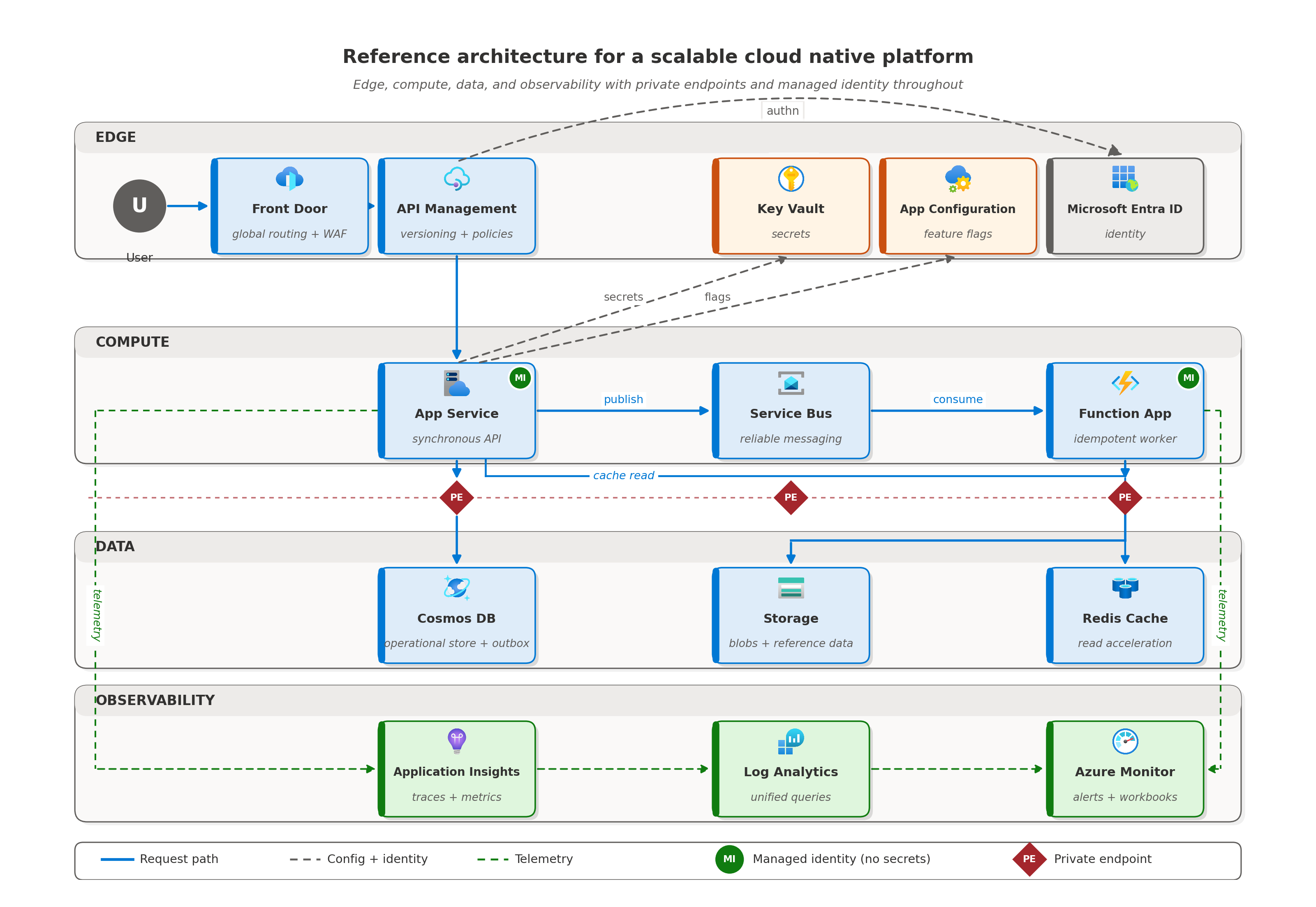
Imagine uma plataforma multi-tenant em um ponto de inflexão de crescimento. Onboarding de um novo tenant leva semanas porque comportamentos específicos de tenant estão hard-coded em vários serviços. Cada release carrega risco porque não há como fazer rollout de uma mudança para um tenant sem afetar os demais. Incidentes se arrastam porque logs e métricas vivem em ferramentas diferentes e ninguém consegue correlacioná-los em produção.
Não comece com uma reescrita. Comece com o menor conjunto de mudanças que desbloqueie o próximo ano de crescimento: extraia configuration do código, introduza feature flags cientes de tenant, conecte uma visão unificada de observabilidade nos serviços existentes e paralelize os pipelines. Nada disso são revoluções arquiteturais. São escolhas de design aplicadas com disciplina, na ordem em que as disciplinas se compõem.
Dezoito meses depois, onboarding de um tenant leva horas em vez de semanas. Releases passam de eventos mensais para incrementos semanais. Incidentes são detectados mais cedo e resolvidos mais rápido. A plataforma não ficou maior. Ficou mais capaz. As cinco disciplinas fizeram o trabalho; o time fez a escolha de aplicá-las.
O que os times erram
O padrão comum é arquitetar para o sistema que você tem, não para o sistema em que você está crescendo. Parece progresso porque a sprint atual entrega. Pilares são adiados porque parecem overhead.
O custo aparece depois. Cada atalho se torna uma restrição. As restrições se compõem, e três releases depois o time está debatendo uma reescrita.
A solução não é abstração prematura. São pequenos investimentos deliberados em flexibilidade, resiliência, observabilidade, entrega e custo desde o dia um. A disciplina é fazer esses investimentos antes que se tornem urgentes.
Por onde começar quando não se pode fazer tudo de uma vez?
Cinco disciplinas são uma parede, e times reais não conseguem financiar todas de uma vez. A ordem certa depende se a plataforma está sendo construída do zero ou já está rodando.
Para um sistema já em produção e já com dor, a hierarquia de necessidades de confiabilidade da comunidade SRE dá a ordem inicial mais defensável: monitoramento e observabilidade primeiro (você não conserta o que não vê), depois resposta a incidentes (feche o sangramento limpa), depois padrões de resiliência (idempotência, retries, desacoplamento) para que o sangramento tenha menos razões para começar, depois flexibilidade e entrega para que mudanças seguras viajem em velocidade. A disciplina de custos corre paralelamente, nunca como headline.
Para um sistema sendo construído do zero, a ordem deste post (flexibilidade, resiliência, observabilidade, entrega, custo) reflete a ênfase do Azure Well-Architected Framework em projetar para mudança, falha e visibilidade antes de escalar times ou workloads. Ambas as ordens são defensáveis. O que não é defensável é deixar qualquer uma das cinco para depois.
O ponto de partida mais concreto deste post: propagação de request ID. Um único correlation identifier viajando por cada hop de serviço, cada fila, cada boundary assíncrono custa horas no início e se paga cada vez que alguém tem que debugar produção pelo resto da vida da plataforma. É a menor unidade da disciplina de observabilidade e a fundação da qual os dashboards, traces e resposta a incidentes da Parte 2 todos dependem.
A mudança
A transformação mais importante em escalar uma plataforma não é técnica. É de mentalidade.
A mudança é de project thinking para platform thinking:
- Construa capacidades reutilizáveis, não soluções únicas
- Projete sistemas para evolução de longo prazo, não para o próximo release
- Capacite outros times, não apenas entregue para um time
Ferramentas mudam. Serviços cloud evoluem. As modas arquiteturais deste ano não serão as do próximo. O que persiste é a disciplina por trás das escolhas. Sistemas escaláveis não são construídos por ferramentas. São construídos por times que tratam design como trabalho contínuo. A mesma disciplina aparece novamente na Parte 2 (operando esses sistemas) e na Parte 3 (usando IA para aumentar esse trabalho). As ferramentas mudam. As disciplinas não.
Quer discutir? Qual escolha de design individual mais rendeu dividendos nas plataformas que você opera? Deixe um comentário com padrões que você viu no seu ambiente. Cada resposta é lida.
Próximo nesta série: Running Cloud Native Platforms: Why Day 2 Decides Everything. Construir é metade da jornada. O próximo post analisa o que é necessário para operar essas plataformas depois que estão em produção.
Perguntas Frequentes
-
Qual é a ordem recomendada para implementar as cinco disciplinas em um sistema já em produção?
Para sistemas em produção com dor, a prioridade é: monitoramento e observabilidade primeiro (você não conserta o que não vê), depois resposta a incidentes, padrões de resiliência (idempotência, retries, desacoplamento), e então flexibilidade e entrega. A disciplina de custos corre paralelamente. -
O que significa idempotência e como implementá-la corretamente?
Idempotência garante que chamadas repetidas com a mesma chave produzam o mesmo resultado. A implementação correta usa atomic reserve-then-execute: insira uma linha com chave única antes de executar a lógica. O primeiro escritor vence; concorrentes aguardam ou recebem 409 Conflict. -
Por que a propagação de request ID é considerada o ponto de partida mais concreto?
Um único correlation ID que viaja por todos os hops, filas e boundaries custa algumas horas de setup e paga dividendos a cada debug em produção. É a menor unidade da observabilidade e base para dashboards, traces e resposta a incidentes. -
Como a disciplina de custos se diferencia de uma revisão trimestral?
Custo deve ser tratado como requisito não funcional de primeira classe, ao lado de latência e disponibilidade. As maiores economias vêm de decisões no data plane (egress cross-region, tiers de storage ociosos, ambientes de teste esquecidos), e não de compute.
Artigo originalmente publicado por KishoreKumarPattabiraman em Azure Updates - Latest from Azure Charts.
