

TL;DR: O rastreamento ponta a ponta de requisições de entrada é essencial para depurar latência e falhas em plataformas SaaS multi-tenant. Este artigo propõe um framework que trata tracing como uma capacidade de produto, não uma escolha de implementação, com identificadores únicos (Trace ID e Span IDs), propagação consistente, segurança por design e exportação via configuração no Kubernetes. A principal conclusão: o maior desafio não é técnico, mas organizacional — garantir cobertura completa de todos os serviços exige enforcement em CI/CD e processos de adoção.
Plataformas SaaS modernas construídas em arquiteturas cloud‑native frequentemente consistem de dezenas de microserviços implantados de forma independente. Uma única requisição de cliente que entra na plataforma pela camada de ingress pode atravessar serviços de autenticação, engines de orquestração, serviços de dados e integrações downstream antes de ser concluída. Quando ocorrem falhas ou regressões de performance, os operadores da plataforma precisam responder a uma pergunta fundamental: o que aconteceu com esta requisição específica, e onde?
Em muitos ambientes, responder a essa pergunta continua difícil. Embora os serviços emitam logs e métricas, esses sinais são desconectados. A telemetria é produzida independentemente por cada serviço sem um contexto de requisição compartilhado, dificultando a correlação de falhas, retries ou picos de latência em uma narrativa ponta a ponta.
Este artigo apresenta um framework orientado a produto para projetar o rastreamento de requisições de entrada em plataformas SaaS multi‑tenant. O foco está nos princípios de design e no comportamento observável do sistema, não no código de implementação. O framework se baseia em padrões da indústria como OpenTelemetry e W3C Trace Context e é aplicável a ambientes baseados em Kubernetes.
O problema de observabilidade
Sem tracing ponta a ponta, as requisições de entrada não podem ser acompanhadas de forma confiável enquanto atravessam serviços downstream. Falhas aparecem como eventos isolados. Regressões de latência são visíveis apenas em métricas agregadas. Workflows multi‑serviço e problemas intermitentes são especialmente difíceis de diagnosticar.
As equipes operacionais compensam correlacionando logs manualmente usando timestamps, heurísticas e identificadores parciais. Essa abordagem não escala com o crescimento dos serviços e resulta em diagnóstico mais lento, maior carga cognitiva durante incidentes e confiança reduzida na análise de causa raiz.
O desafio central não é telemetria insuficiente, mas a falta de um contexto consistente em nível de requisição que conecte todas as operações.
Um framework orientado a produto para rastreamento de requisições de entrada
Este framework trata o tracing distribuído como uma capacidade de plataforma de primeira classe, e não como uma escolha de implementação em nível de serviço. Em seu núcleo estão dois identificadores complementares: um Trace ID que agrupa todo o trabalho de uma única requisição de cliente, e Span IDs que identificam unidades individuais de trabalho (como uma chamada de serviço ou consulta a banco de dados) dentro desse trace.
Cada requisição de entrada deve ter um identificador de trace associado. Se uma requisição recebida não contém um trace ID, a camada de ingress gera um. Se um trace ID válido já estiver presente, ele é preservado.
1. Geração e preservação de Trace ID e Span ID
Cada serviço que processa a requisição cria seu próprio span e atribui um span ID único para aquela unidade de trabalho. Quando o serviço faz uma chamada downstream, ele passa tanto o trace ID (inalterado) quanto seu span ID (que se torna o parent span ID para o próximo serviço). Isso cria uma relação pai‑filho que permite à plataforma de observabilidade reconstruir a sequência exata e a hierarquia de todas as operações.
Essa regra de gerar‑ou‑preservar garante interoperabilidade com sistemas upstream enquanto mantém a continuidade do trace dentro da plataforma. Tanto o trace ID quanto o span ID atual são anexados ao contexto da requisição e incluídos nos cabeçalhos de resposta para que possam ser usados como chaves de consulta determinísticas durante investigações.
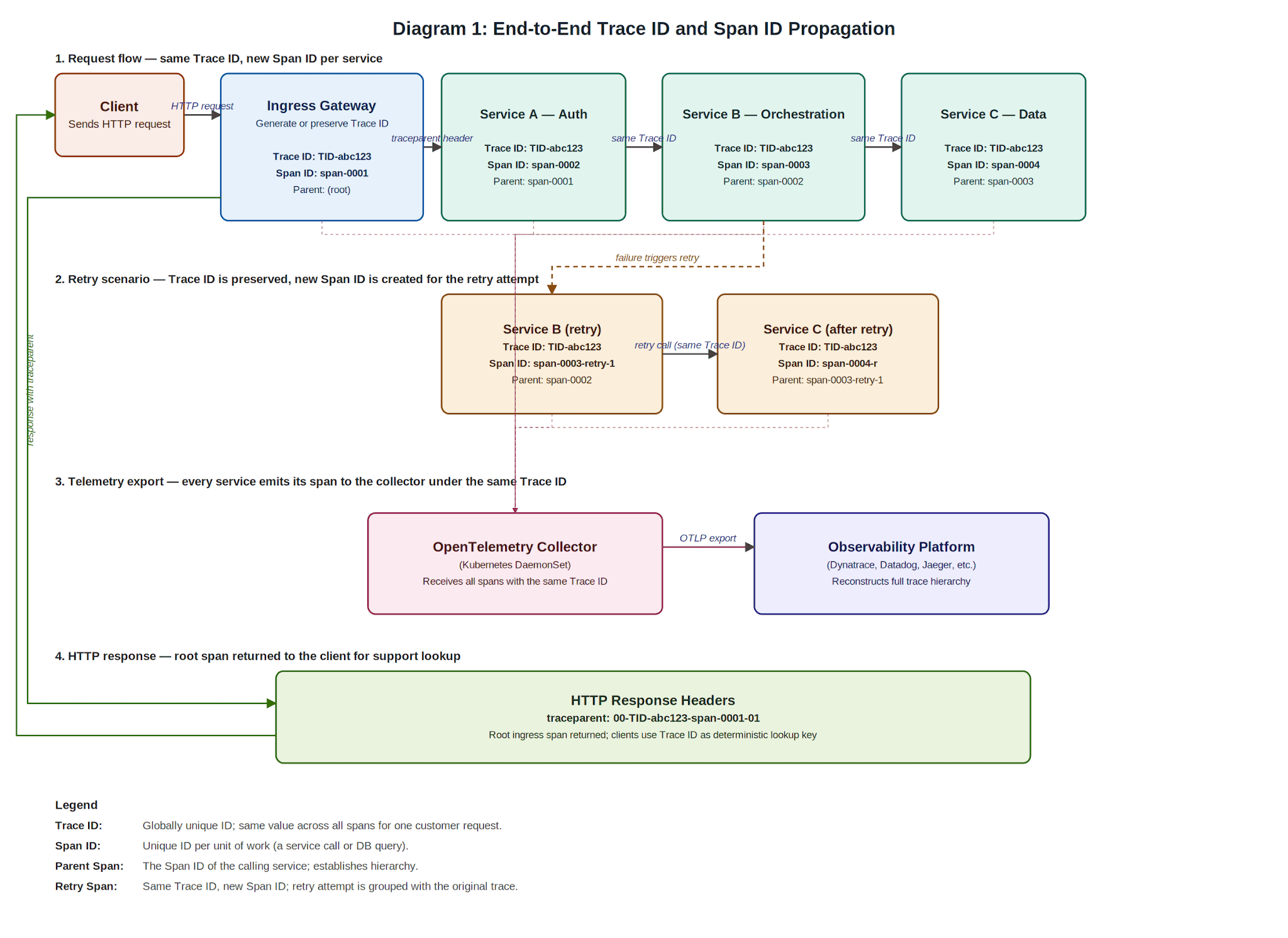
Figura 1: Propagação ponta a ponta de Trace ID e Span ID. No diagrama acima, um único Trace ID flui inalterado por todos os serviços (auth, orquestração, camada de dados), representando a requisição completa do cliente. Cada serviço cria seu próprio Span ID; quando o Serviço A chama o Serviço B, ele passa tanto o Trace ID quanto seu próprio Span ID (que o Serviço B registra como seu pai). Essa hierarquia permite que os operadores vejam não apenas que uma requisição falhou, mas exatamente em qual serviço e em qual ponto da sequência.
2. Propagação consistente de contexto
Todas as chamadas síncronas serviço‑a‑serviço reutilizam o mesmo trace ID. Cada serviço cria um novo span ID para seu próprio trabalho. Operações de retry preservam o trace ID original, mas podem criar span IDs adicionais para cada tentativa, permitindo que a plataforma de observabilidade distinga entre a chamada original e as tentativas subsequentes, mantendo‑as agrupadas sob o mesmo trace.
Onde existe processamento assíncrono, o contexto do trace (tanto trace ID quanto parent span ID) é propagado via metadados da mensagem para evitar lacunas de observabilidade à medida que os workflows evoluem.
3. Metadados de trace com foco em segurança
Os dados de trace são limitados a metadados operacionais: trace ID, span ID, parent span ID, nome do serviço, nome da operação, timestamps, duração e status de execução.
Payloads de requisição, credenciais, segredos, tokens e informações pessoais (PII) são explicitamente excluídos por design. Tratar a exclusão de dados como uma restrição de design simplifica as revisões de segurança e reduz o risco de conformidade no longo prazo.
4. Exportação de telemetria baseada apenas em configuração
A exportação de traces é gerenciada inteiramente via configuração do Kubernetes. Os operadores podem configurar exporters, credenciais e parâmetros de roteamento sem alterações no código da aplicação.
Isso desacopla as operações de tracing dos ciclos de release e permite que as equipes evoluam a observabilidade usando workflows de SRE existentes.
5. Modos de falha não disruptivos
O tracing nunca deve bloquear o processamento de requisições. Se os backends de telemetria estiverem indisponíveis ou mal configurados, as requisições são concluídas com sucesso. Os dados de trace podem ser bufferizados ou descartados, mas a experiência do cliente não é afetada.
Traces parciais são aceitáveis. Requisições com falha, não.
Critérios de aceitação como contratos executáveis
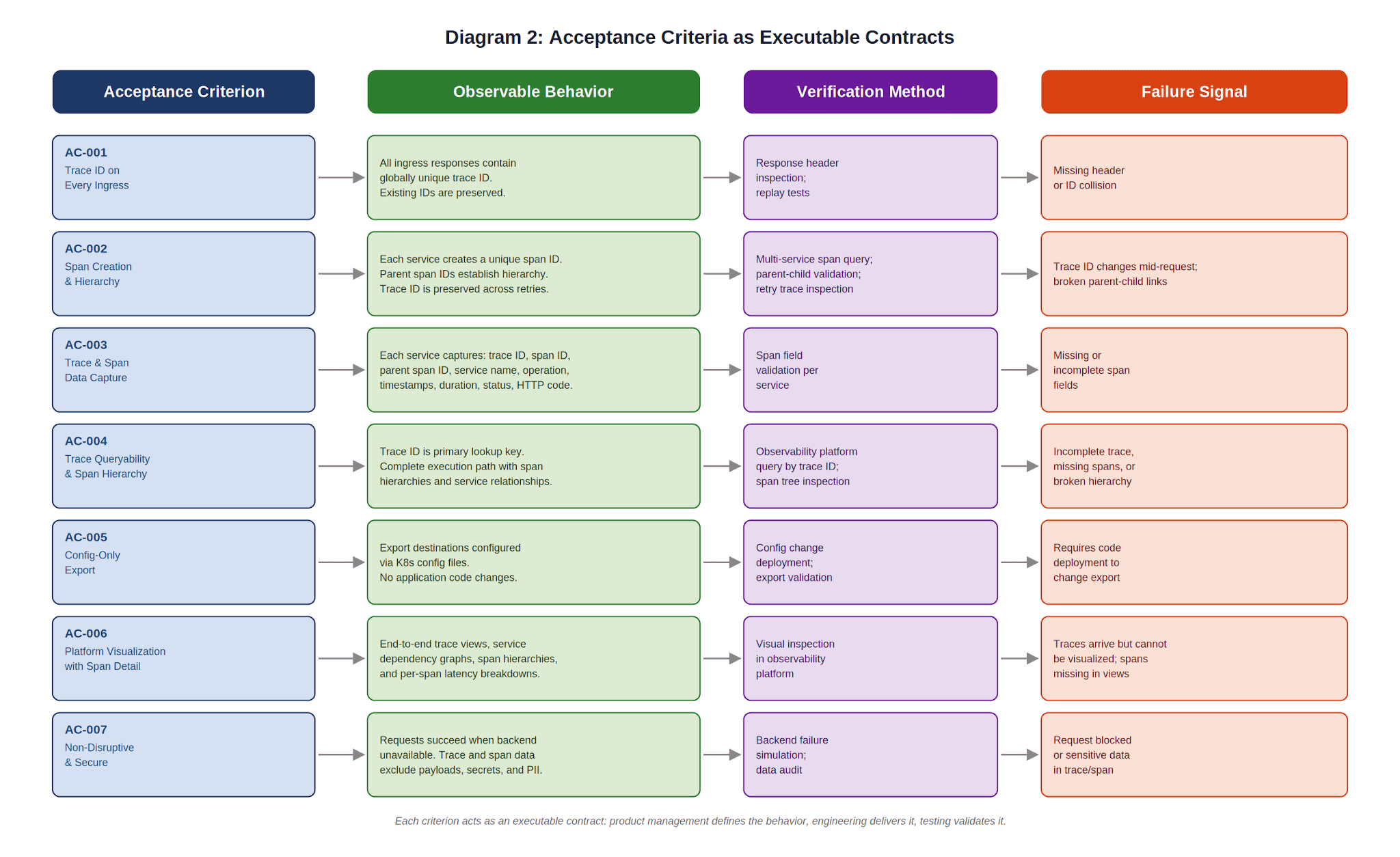
Critérios de aceitação claros definem resultados observáveis do sistema, não detalhes de implementação. Neste framework, os critérios de aceitação atuam como contratos executáveis entre product management e engenharia. Cada critério mapeia para um requisito específico e é testável de forma independente.
| AC ID | Comportamento Observável | Área de Requisito |
|---|---|---|
| AC-001 | Toda requisição de entrada inclui um trace ID globalmente único nos cabeçalhos de resposta. Trace IDs já presentes em requisições recebidas são preservados e propagados inalterados. | Geração e Preservação de Trace ID |
| AC-002 | Todos os serviços da plataforma que processam uma requisição de entrada criam seu próprio span com um span ID único. Relações pai‑filho são estabelecidas por meio de parent span IDs. Operações de retry preservam o trace ID original. | Criação de Span e Hierarquia |
| AC-003 | Cada serviço da plataforma captura dados de execução em nível de trace, incluindo trace ID, span ID, parent span ID, nome do serviço, nome da operação, timestamps, duração, status e código de resposta HTTP. | Captura de Dados de Trace |
| AC-004 | SREs podem consultar traces usando um trace ID como chave de pesquisa primária em plataformas de observabilidade e visualizar o caminho completo de execução com relações serviço‑a‑serviço por meio de hierarquias de span. | Consultabilidade de Traces |
| AC-005 | SREs podem configurar destinos de exportação de traces via arquivos de configuração do Kubernetes sem alterações no código da aplicação. Múltiplos backends e roteamento por tenant são suportados. | Exportação via Configuração |
| AC-006 | Traces exportados para plataformas de observabilidade são visualizáveis com visões de trace ponta a ponta, gráficos de dependência de serviços, hierarquias de span e detalhamento de latência por serviço e por span. | Visualização na Plataforma |
| AC-007 | O tracing não bloqueia nem causa falha em requisições quando o backend de telemetria está indisponível. Os dados de trace excluem informações sensíveis de payload, credenciais e PII por design. | Não Disruptivo e Seguro |
Esses critérios previnem adoção parcial, reduzem ambiguidade durante a implementação e fornecem uma base estável para validação de regressão à medida que a plataforma evolui.
Quantificando o valor de negócio
Iniciativas de infraestrutura frequentemente falham por não conseguir articular valor de negócio além da engenharia. A proposta de valor para este tipo de iniciativa deve ser construída em torno de dimensões operacionais mensuráveis:
| Dimensão de Valor | Impacto Quantificado |
|---|---|
| Identificação de Causa Raiz | Mudança de heurísticas para tracing determinístico por meio de hierarquias de trace e span; eliminação da correlação manual de logs |
| Escalabilidade Operacional | Observabilidade escala linearmente com o número de serviços, em vez de degradar com a complexidade; granularidade em nível de span permite diagnósticos em nível de microsserviço |
Entendendo o contexto de trace e span
O padrão W3C Trace Context define como as informações de trace propagam entre serviços. Ele especifica dois cabeçalhos HTTP: traceparent carrega os identificadores essenciais, e tracestate carrega metadados específicos do vendor. O formato do cabeçalho traceparent é versão‑trace‑id‑span‑id‑flags (por exemplo, 00‑abc123‑def456‑01).
Trace ID: Identificador globalmente único que agrupa todos os spans pertencentes a uma única requisição de cliente. Permanece inalterado conforme a requisição flui por todos os serviços. Permite que equipes de suporte consultem todo o caminho da requisição.
Span ID: Identificador único para uma única unidade de trabalho (ex.: chamada de API, consulta a banco de dados). Cada serviço cria seu próprio span ID. Ao fazer chamadas downstream, o span ID atual se torna o parent span ID para o próximo serviço, estabelecendo uma relação pai‑filho.
Parent Span ID: O span ID do serviço chamador. Usado para reconstruir a sequência e hierarquia das operações. Permite que a plataforma de observabilidade exiba qual serviço chamou qual e em que ordem.
Juntos, o trace ID e a hierarquia de span permitem que os operadores perguntem não apenas 'esta requisição falhou?', mas 'exatamente onde na sequência ela falhou, e qual foi a sequência de chamadas que levou a esse ponto?'
Impacto operacional
O rastreamento de requisições de entrada desloca a solução de problemas da inferência para a observação direta. Engenheiros podem acompanhar requisições individuais através dos serviços em vez de reconstruir comportamento a partir de sinais desconectados. Com trace e span IDs, todo o caminho de execução fica visível: quais serviços foram chamados, em que ordem e quanto tempo cada um gastou.
Os benefícios qualitativos são imediatos e significativos: localização mais rápida de falhas por meio de consulta por trace ID e análise de hierarquia de span; comunicação inter‑equipes mais clara usando referências de trace compartilhadas em vez de descrições de sintomas; carga cognitiva reduzida durante incidentes, já que SREs observam a sequência exata em vez de formular hipóteses; e gerenciamento proativo de performance por meio da decomposição de latência por serviço e por span.
Para equipes pequenas de SRE que suportam plataformas complexas, essas melhorias são transformadoras. Um único SRE com um trace pode alcançar o que antes exigia uma war room multifuncional.
A parte mais difícil não é técnica
O desafio mais subestimado em qualquer iniciativa de tracing é organizacional, não técnico. Um sistema de tracing distribuído é tão completo quanto sua cobertura. Se três de oito serviços em um caminho de requisição propagam o contexto do trace e cinco não, o resultado é um trace com grandes lacunas que é operacionalmente não confiável. Pior, relações pai‑filho quebradas tornam a hierarquia inútil.
A solução combina enforcement técnico com processo organizacional: verificações automatizadas em CI/CD que rejeitam deployments sem instrumentação de trace e criação adequada de span; um checklist de onboarding documentado para cada equipe de serviço; e acompanhamento sustentado da adoção até que 100% de propagação seja alcançada. Sem essa atenção contínua, a adoção estagna nas equipes que aderem voluntariamente, deixando lacunas críticas exatamente nos serviços onde o tracing é mais necessário.
Replicando este framework
Este framework é projetado para ser replicável em qualquer plataforma SaaS multi‑serviço executada em infraestrutura de orquestração de contêineres. Os princípios de design — gerar ou preservar trace IDs, criar span IDs únicos por serviço com relações pai‑filho, capturar apenas metadados operacionais incluindo span IDs, exportar por meio de backends configuráveis e degradar graciosamente — são independentes de arquitetura e aplicáveis independentemente do framework de microsserviços, linguagens de programação ou backend de observabilidade em uso.
Organizações considerando a adoção devem prestar atenção especial a duas áreas: design de modos de falha (garantindo que tracing não cause outages) e estratégia de adoção organizacional (garantindo cobertura completa de serviços por meio de enforcement técnico e processo). Esses são os pontos de falha mais comuns em implantações de tracing distribuído e as áreas onde as orientações publicadas são mais escassas.
Extensões naturais incluem a expansão para workflows assíncronos baseados em mensagens, implementação de estratégias inteligentes de sampling, correlação de dados de trace e span com sinais de infraestrutura e, eventualmente, aproveitamento de padrões históricos de span para operações preditivas.
Conclusão
O tracing distribuído é fundamental para operar plataformas cloud‑native em escala, mas ferramentas sozinhas não são suficientes. Ao tratar tracing como uma capacidade de produto com garantias claras, critérios de aceitação como contratos executáveis e disciplina de modos de falha, as plataformas podem fornecer visibilidade confiável em nível de requisição sem comprometer segurança ou disponibilidade.
A lacuna em nossa indústria não está nas ferramentas de tracing — OpenTelemetry, Jaeger, Zipkin e plataformas comerciais já resolveram as camadas de instrumentação e visualização. A lacuna está nas decisões de produto e operacionais necessárias para implantar tracing com sucesso: como escopá-lo, como protegê-lo, como torná-lo amigável ao operador, como garantir adoção completa, como estabelecer hierarquias de span que revelem a verdadeira sequência de operações e como medir seu impacto. Essa é a lacuna que este framework aborda.
Perguntas Frequentes
-
Como garantir que o tracing não afete a performance das requisições?
O framework define que o tracing nunca deve bloquear o processamento da requisição. Se o backend de telemetria estiver indisponível ou mal configurado, as requisições devem ser concluídas normalmente. Traces parciais são aceitáveis; requisições com falha, não. -
Qual é o maior desafio ao adotar tracing distribuído em plataformas SaaS?
O maior desafio não é técnico, mas organizacional. A eficácia do tracing depende da cobertura completa de todos os serviços. Se apenas alguns serviços propagam trace context, o resultado são traces com grandes lacunas. A solução envolve enforcement em CI/CD, checklist de onboarding e acompanhamento contínuo até 100% de adoção. -
Quais dados devem ser excluídos dos traces por segurança?
O framework recomenda capturar apenas metadados operacionais: trace ID, span ID, parent span ID, nome do serviço, nome da operação, timestamps, duração e status. Payloads de requisição, credenciais, tokens e informações pessoais (PII) devem ser explicitamente excluídos por design. -
Como configurar a exportação de traces sem alterar código?
A exportação de traces é gerenciada inteiramente por configuração do Kubernetes. Os operadores podem configurar exporters, credenciais e parâmetros de roteamento sem alterações no código da aplicação, desacoplando tracing dos ciclos de release e permitindo evolução via workflows de SRE existentes.
Artigo originalmente publicado por Mridula Chilakamarri, CNCF Technical Advisory Group em Cloud Native Computing Foundation.
