

No ecossistema de IA/ML, o data pipeline é o gargalo que determina a eficiência do treinamento e da inferência. Para times que rodam workloads no Google Kubernetes Engine (GKE), o Cloud Storage FUSE tem sido a peça fundamental para integrar o armazenamento de objetos do Google Cloud. Contudo, a experiência tem mostrado que extrair a performance máxima dessa solução exigia um esforço de configuração manual complexo e, frequentemente, propenso a erros.
Recentemente, o Google introduziu os GKE Cloud Storage FUSE Profiles. Esta novidade descomplica o ajuste fino de performance, automatizando o acesso a dados de forma inteligente e com quase nenhum overhead operacional. Na prática, a mudança é drástica: saímos de configurações complexas e manuais para um modelo declarativo que entrega o melhor rendimento out-of-the-box.
Antes (Tunagem manual típica):
apiVersion: v1
kind: PersistentVolume
metadata:
name: serving-bucket-pv
spec:
accessModes:
- ReadWriteMany
capacity:
storage: 64Gi
persistentVolumeReclaimPolicy: Retain
storageClassName: ""
mountOptions:
- implicit-dirs
- metadata-cache:ttl-secs:-1
- file-cache:enable-parallel-downloads:true
csi:
driver: gcsfuse.csi.storage.gke.io
volumeHandle: BUCKET_NAME
Depois (Configuração automatizada via Profiles):
apiVersion: v1
kind: PersistentVolume
metadata:
name: serving-bucket-pv
spec:
accessModes:
- ReadWriteMany
storageClassName: gcsfusecsi-serving
csi:
driver: gcsfuse.csi.storage.gke.io
volumeHandle: BUCKET_NAME
O desafio por trás da performance no Cloud Storage FUSE
Historicamente, otimizar o FUSE para IA era um problema multidimensional. Engenheiros precisavam lidar com variáveis complexas: características do bucket (tamanho do dataset), a infraestrutura (uso de GPUs ou TPUs), limites de RAM dos nós e, claro, o padrão de I/O do workload. Ajustar esses "knobs" manualmente é uma tarefa contínua e onerosa. Muitas empresas acabam sofrendo com subutilização de recursos ou quedas de Pods (OOM kills) por falhas na alocação de cache. Este novo recurso corrige exatamente esse ponto de atrito ao introduzir uma camada inteligente de orquestração.
Como funcionam os GKE Cloud Storage FUSE Profiles
Os perfis operam como uma camada de inteligência integrada ao CSI driver do GKE. Ao acionar um profile, o GKE realiza uma análise em tempo real do ambiente:
- Escaneia o bucket para entender a volumetria e contagem de objetos.
- Avalia o nó hospedeiro (capacidade de RAM, uso de Local SSD e presença de aceleradores).
- Calcula os parâmetros ideais de cache e o melhor meio de armazenamento automaticamente.
O lançamento contempla três perfis especializados:
gcsfusecsi-training: Focado em high-throughput para manter GPUs/TPUs sempre alimentadas.gcsfusecsi-serving: Focado em inferência, utilizando o Rapid Cache para acelerar o load de modelos.gcsfusecsi-checkpointing: Otimizado para escritas constantes e volumosas de checkpoints.
Impacto real
Em cenários de escala, o ganho de tempo é expressivo. Em testes com grandes modelos (como o Qwen3), foi possível reduzir o tempo de carregamento de 39 horas para apenas 14 minutos. Isso não é apenas uma melhoria técnica; é eficiência operacional direta que impacta o custo total da operação (FinOps) e acelera o ciclo de desenvolvimento (Time-to-Market).
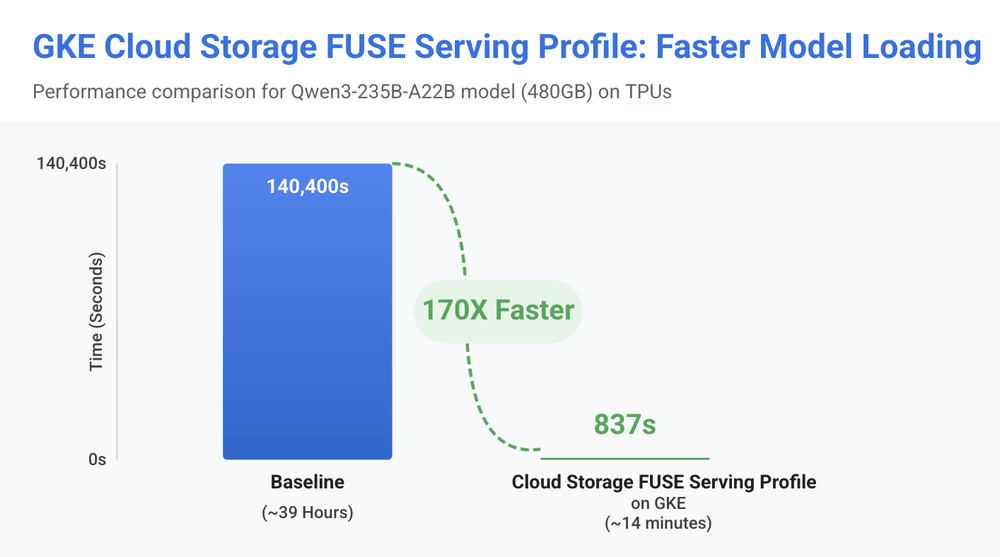
Para implementar, basta estar na versão 1.35.1-gke.1616000 ou superior do GKE. A simplificação no uso de StorageClasses permite que o time de engenharia abstraia a complexidade do armazenamento e foque no que realmente traz valor: a lógica do modelo de IA.
Artigo originalmente publicado por Uriel Guzmán-MendozaSoftware Engineer em Cloud Blog.
