

À medida que cargas de trabalho de IA saem do ambiente experimental para a produção, engenheiros de plataforma e líderes de TI enfrentam um dilema clássico: otimizar para latência ultra-baixa em requisições real-time ou priorizar o throughput em processamentos assíncronos (async). No cenário atual, a resposta comum tem sido a criação de silos de GPUs e TPUs altamente custosos, onde o over-provisioning para picos de tráfego real-time gera desperdício de recurso durante períodos de baixa, enquanto tasks assíncronas lutam por espaço em clusters secundários.
Para empresas brasileiras focadas em eficiência operacional e controle de custos de cloud, essa fragmentação é um gargalo de FinOps e complexidade técnica. O GKE Inference Gateway propõe uma mudança de paradigma, tratando a capacidade de aceleração como um pool único e fluido, capaz de atender a diferentes padrões de inferência sem a necessidade de stacks paralelas e desencontradas.
Dois padrões de inferência: Real-time vs. Async
Para entender a eficácia desta abordagem, devemos separar os dois perfis de carga. No inferência real-time, lidamos com requisições síncronas de alta prioridade — como LLMs em chatbots — onde a latência é o KPI mestre. Já a inferência assíncrona (ex.: indexação de documentos ou categorização de produtos em retail) é tolerante a atrasos e costuma ser processada via filas.
1. Real-time: Sensibilidade à latência zero
O grande desafio aqui é que load balancers genéricos não possuem visibilidade sobre métricas específicas de modelos (como a utilização de KV cache). O GKE Inference Gateway soluciona isso implementando um scheduling consciente de latência, que monitora o estado real dos servidores de inferência para minimizar o time-to-first-token, evitando o congestionamento de requisições sob carga.
2. Async: Otimização de carga (Near-real time)
Normalmente, estas tasks são isoladas em clusters ociosos por puro medo de contenção (resource contention). Com o uso do Async Processor Agent integrado ao Pub/Sub, o GKE permite que essas tarefas utilizem o 'gap' de processamento não ocupado pelas requisições real-time. É um movimento inteligente de FinOps: utilizar a capacidade ociosa para processamento batch sem degradar o SLA das aplicações críticas.
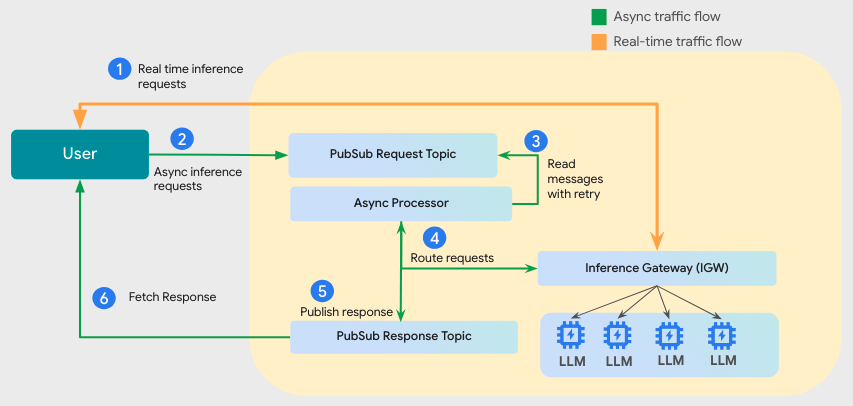
O fluxo de requisições, conforme ilustrado acima, opera da seguinte forma:
- Requisições real-time são priorizadas no scheduling do Inference Gateway.
- Inserções no Pub/Sub são coletadas pelo Async Processor.
- O processador encaminha as tarefas batch apenas quando houver ciclos de compute disponíveis.
- O sistema garante que a prioridade real-time sempre seja respeitada, tratando-as como "filler traffic".
Ao consolidar essas cargas, eliminamos a necessidade de gerenciar pollers customizados e ambientes díspares, o que simplifica drasticamente o pipeline de monitoramento e observability.
Resultados reais da consolidação
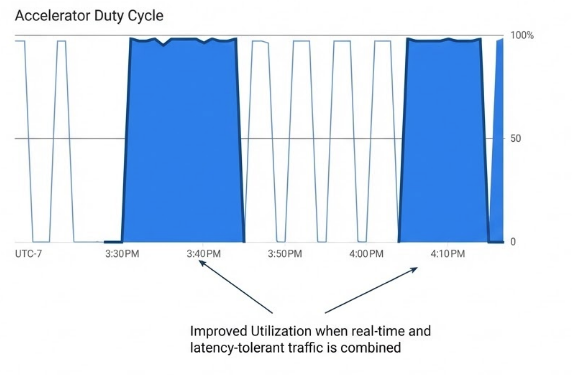
Implementar essa arquitetura em um ambiente produtivo traz ganhos tangíveis de utilização. Em testes de estresse, a tentativa de multiplexação sem o devido gerenciamento (Async Processor) levou a perdas de 99% das mensagens. Contudo, ao utilizar o orquestrador inteligente, é possível atingir 100% de processamento para as tasks de batch nos ciclos ociosos, sem qualquer impacto na latência das requisições síncronas.
Próximos passos
Para equipes de engenharia que buscam modernizar sua infra, o próximo grande avanço será o deadline-aware scheduling, permitindo definir limites (soft limits) para a conclusão das tarefas batch. Este é o caminho para quem deseja sustentabilidade financeira na era da IA, evitando o desperdício de instâncias de GPU e mantendo o foco na estabilidade da operação.
Artigo originalmente publicado por Abdullah GharaibehSenior Staff Software Engineer em Cloud Blog.
