

Novidades do Microsoft Foundry | Maio de 2026
TL;DR: Maio de 2026 trouxe avanços significativos no Microsoft Foundry: Grok 4.3 e DeepSeek V4 expandem o catálogo de modelos; trace-based evaluation permite avaliar agentes com dados reais de produção; Managed VNET atinge GA com isolamento de rede gerenciado pela Microsoft; e agentes on-device da Microsoft Research (MagenticBrain, Fara1.5, MagenticLite) abrem caminho para automação local. A conclusão principal: a plataforma está amadurecendo para cargas de produção, com ênfase em governança, avaliação contínua e flexibilidade de modelos — pontos críticos para empresas brasileiras que buscam escalar IA com controle.
O mês de maio de 2026 foi intenso para o Microsoft Foundry. As atualizações abrangem desde novos modelos de linguagem até melhorias significativas em infraestrutura de rede, avaliação de agentes e ferramentas de desenvolvimento. Para times de engenharia no Brasil, o recado é claro: a plataforma está deixando de ser um playground de experimentação para se tornar um ambiente robusto para cargas de produção, com ênfase em governança, custos e segurança.
Modelos
Grok 4.3
O Grok 4.3 da xAI está disponível no catálogo de modelos do Microsoft Foundry. Este é um avanço em relação ao Grok 4.2 GA lançado em março, focado em workloads agentivas avançadas e cenários de domínio específico que exigem um modelo externo de alta capacidade com os controles de produção, ferramentas de segurança e conformidade empresarial do Foundry.
Se você já usa modelos Grok no Foundry, o 4.3 é um caminho de upgrade direto através do mesmo fluxo de deployment. Uma nota prática antes de mover tráfego: revise o model card e execute suas próprias avaliações para seu caso de uso alvo. O catálogo chama a atenção para considerações adicionais de IA responsável para o Grok 4.3, incluindo riscos de segurança e jailbreak maiores do que alguns outros modelos Azure Direct. Trate isso como um item de checklist de deployment, não como nota de rodapé.
O Grok 4.3 usa o caminho da API Chat Completions, então chame o deployment diretamente. Defina FOUNDRY_ENDPOINT para o endpoint do seu deployment terminando em /openai/v1/chat/completions, depois remova esse sufixo para a base URL do cliente OpenAI:
import os
from openai import OpenAI
endpoint = os.environ["FOUNDRY_ENDPOINT"]
client = OpenAI(
api_key=os.environ["FOUNDRY_API_KEY"],
base_url=endpoint.removesuffix("/chat/completions"),
)
response = client.chat.completions.create(
model="grok-4.3",
messages=[
{"role": "system", "content": "You are Grok, a highly intelligent, helpful AI assistant."},
{
"role": "user",
"content": "In one sentence, explain why developers should evaluate agent tool calls before production.",
},
],
temperature=0.2,
max_tokens=80,
)
print(response.choices[0].message.content)
Saída de exemplo:
Developers should evaluate agent tool calls before production to catch incorrect parameters, unsafe actions, or unintended side effects that autonomous agents can generate in real environments.
Ação: Faça deploy do Grok 4.3 a partir do catálogo de modelos e compare com seus workloads atuais do Grok 4.2.
DeepSeek V4
As variantes do DeepSeek V4 agora estão disponíveis no Microsoft Foundry. DeepSeek vem ganhando força no espaço de modelos abertos, e o V4 reforça a amplitude de escolha no catálogo do Foundry — particularmente para equipes que desejam desempenho competitivo em raciocínio e codificação a partir de modelos de peso aberto com deploy e monitoramento completos do Foundry.
Ação: Navegue pelos modelos DeepSeek V4 no catálogo e teste contra sua mistura de modelos existente.
Fireworks AI no Foundry — Atualização de Maio
A integração com Fireworks AI continua a se expandir. Dois novos modelos chegaram em maio:
| Modelo | O que faz | Melhor para |
|---|---|---|
| DeepSeek V4 Pro | Raciocínio de modelo aberto de alta precisão via Fireworks | Raciocínio complexo, codificação, workflows de agentes |
| Kimi 2.6 | Raciocínio de longo horizonte e workflows agentivos via Fireworks | Cadeias de raciocínio estendidas, codificação, agentes multi-etapa |
Ambos rodam na infraestrutura de inferência de alta throughput da Fireworks com segurança empresarial e conformidade do Azure. A narrativa mais ampla aqui é escolha de modelo sem compromisso: amplitude de modelo aberto, escalabilidade de produção e controle do cliente sobre o deployment, tudo dentro do envelope operacional do Foundry.
Ação: Faça deploy do DeepSeek V4 Pro ou Kimi 2.6 via Fireworks a partir do catálogo de modelos para inferência de modelo aberto de alta throughput.
Navegue pelos modelos Fireworks no catálogo
GPT-5 Reinforcement Fine-Tuning (Gated GA)
O GPT-5 Reinforcement Fine-Tuning (RFT) passa de preview para gated GA. Isso significa acesso pronto para empresa com garantias de conformidade mais fortes e cobertura de SLA — o tipo de estabilidade que as equipes precisam antes de comprometer pipelines de fine-tuning de produção com um serviço.
O RFT permite treinar o GPT-5 em tarefas específicas de domínio usando reinforcement learning a partir de feedback humano, sem gerenciar infraestrutura de treinamento. O status gated GA significa que o acesso requer aprovação, mas uma vez dentro, você obtém suporte e compromissos de nível de produção.
Ação: Se você tem workloads RFT em preview, comece a planejar a migração para o tier GA. Se é novo no RFT, solicite acesso através do catálogo de modelos.
Explore Reinforcement Fine-Tuning
Modelos de Agentes da Microsoft Research — MagenticBrain, Fara1.5-9B, MagenticLite
Três Foundry Labs relacionados da Microsoft Research foram lançados este mês: MagenticLite, o app agentivo local; MagenticBrain, o planejador/codificador/orquestrador; e Fara1.5, a família de modelos de uso de computador para trabalho em navegador. A Microsoft Research desenvolveu isso como um sistema co-projetado: MagenticLite é o app e harness, MagenticBrain lida com raciocínio/delegação/uso de terminal, e Fara1.5 lida com tarefas baseadas em navegador. Cada componente é útil por si só, mas funcionam melhor juntos.
Comece com o repositório GitHub do MagenticLite quando quiser executá-lo localmente; a página Foundry Labs é uma boa visão geral do artefato de pesquisa. O app espera endpoints /v1 compatíveis com OpenAI para os dois papéis de modelo recomendados. MagenticLite no GitHub, MagenticBrain no Microsoft Foundry, e Fara1.5 no Microsoft Foundry estão disponíveis para você começar. Configure o Foundry Managed Compute: faça deploy do Fara1.5-9B para uso em navegador e do MagenticBrain-14B para orquestração, depois cole o endpoint /v1, ID do modelo e chave primária de cada deployment no MagenticLite.
Aqui está uma demonstração do MagenticLite com formulário de despesas do projeto:

Você também pode navegar pelo conjunto completo de demonstrações.
Ação: Experimente o MagenticLite localmente se estiver explorando agentes de navegador mais sistema de arquivos, depois conecte os endpoints MagenticBrain e Fara1.5 através do guia Foundry Managed Compute.
Execute MagenticLite a partir do GitHub
Avaliações e Benchmarks
Maio foi um mês forte para a infraestrutura de avaliação. O destaque: agora você pode avaliar traces reais de produção de agentes rodando em qualquer lugar — não apenas agentes hospedados no Foundry, e não apenas de conjuntos de teste sintéticos.
Avaliação Baseada em Traces (Trace-Based Evaluation)
Duas capacidades foram lançadas consecutivamente:
- Avaliação baseada em traces para agentes externos (4 de maio): permite avaliar traces de produção de agentes rodando no Foundry, GCP, AWS ou qualquer outra plataforma. Em vez de curar manualmente conjuntos de dados de avaliação, você aponta avaliadores para traces reais e obtém pontuações de qualidade no comportamento do agente ao vivo.
- Avaliação baseada em traces para agentes hospedados (6 de maio): traz a mesma abordagem para agentes hospedados no Foundry. Avalie a qualidade do agente usando interações ao vivo em vez de depender exclusivamente de conjuntos de teste sintéticos.
Esta é uma mudança significativa. A avaliação está se movendo de "teste antes de enviar" para "meça o que está realmente acontecendo em produção" — e funciona entre nuvens e frameworks.
Ação: Conecte seus traces de agente às avaliações do Foundry. Se você está rodando agentes em plataformas externas, use a avaliação baseada em traces para obter sinais de qualidade sem migrar workloads.
Configure Avaliação Baseada em Traces
Atualizações de Ferramentas de Avaliação
Três melhorias de avaliação foram lançadas em meados do mês:
- Alinhamento de avaliação com AI Toolkit e VS Code: Fluxo de trabalho de avaliação consistente entre portal e superfícies IDE. Execute os mesmos avaliadores do VS Code que você usa no portal — menos atrito ao alternar entre ambientes.
- Avaliação de skills: Skills se tornam um conceito de primeira classe nas avaliações do Foundry. Este é um trabalho de plataforma fundamental para avaliação estruturada de skills — espere mais aqui nos próximos meses.
- UX de avaliação de workflow: UX melhorada para avaliações de workflow com novos avaliadores de workflow. Se você achou a experiência de avaliação de workflow difícil, esta é a atualização para revisitar.
Ação: Atualize sua extensão Foundry Toolkit e tente executar avaliações a partir do VS Code junto com o portal.
SocialReasoning-Bench e STATE-Bench
Dois benchmarks de código aberto foram lançados para equipes que constroem agentes que precisam trabalhar com outros agentes ou lembrar coisas entre sessões:
- SocialReasoning-Bench: Testa se os agentes negociam e coordenam competentemente. Mede tanto a qualidade do resultado (o agente conseguiu um bom acordo?) quanto a qualidade do processo (negociou razoavelmente?) em cenários realistas e adversariais. Útil se você está construindo sistemas multi-agente onde agentes interagem com partes externas.
- STATE-Bench: Mede se a memória do agente realmente melhora o desempenho em tarefas empresariais realistas. Se você está investindo em arquiteturas de memória para seus agentes, isso fornece uma maneira reproduzível de avaliar se essa memória está ajudando ou apenas adicionando complexidade.
Ação: Use SocialReasoning-Bench e STATE-Bench para testar as capacidades de coordenação e memória de seus agentes contra baselines reproduzíveis.
Explore SocialReasoning-Bench no Labs
Plataforma
Managed VNET (GA)
O Managed VNET agora está geralmente disponível para projetos do Microsoft Foundry. Esta é uma daquelas atualizações de plataforma que parecem encanamento até que sua revisão de segurança esteja encarando você do outro lado da mesa.
Em vez de pedir a cada equipe de aplicativo para projetar a rede virtual, dimensionar sub-redes, aprovar endpoints e configurar firewalls do zero, o Foundry agora pode provisionar um limite de rede gerenciado pela Microsoft para tráfego de saída do agente. Você ainda escolhe a postura de isolamento:
| Modo | Use quando |
|---|---|
| Permitir saída para internet | Você precisa de isolamento gerenciado, mas acesso de saída amplo é aceitável. |
| Permitir apenas saída aprovada | Você precisa de egresso curado através de service tags, private endpoints ou regras FQDN. |
O payoff para o desenvolvedor é simples: agentes hospedados e prompt podem alcançar recursos aprovados como Azure Storage, Azure Cosmos DB, Azure Key Vault e Azure AI Search através de private endpoints gerenciados, enquanto os primitivos de rede ficam principalmente fora do seu código de aplicativo. As avaliações também se encaixam na mesma história, com regras de saída necessárias para catálogos de avaliação e relatórios de resultados do Application Insights.
Dois pontos de atenção merecem destaque antes de você ativar a chave. Primeiro, o modo de isolamento é uma decisão arquitetural no momento da criação — você não pode desabilitar o Managed VNET posteriormente ou converter um deployment de VNET personalizado no local. Segundo, regras de saída FQDN criam um Azure Firewall gerenciado, o que significa que cobranças de firewall podem aparecer mesmo que o recurso Managed VNET em si seja gratuito. Encanamento de plataforma: ainda é encanamento, apenas com uma etiqueta de preço se você pedir válvulas sofisticadas.
Ação: Use Managed VNET para novos projetos de agentes regulamentados e decida cedo se você precisa de allow_internet_outbound ou allow_only_approved_outbound.
Quota GA para Global e Data Zone
O gerenciamento de quota para deployments Global Standard e Data Zone Standard agora está geralmente disponível. Isso importa se seus deployments de modelo de produção já abrangem regiões, ou se você está tentando passar de "por que recebi um 429?" arqueologia para planejamento deliberado de capacidade.
A quota é escopo por subscription, região, modelo e tipo de deployment. O Foundry agora fornece um modelo operacional mais limpo para essa capacidade:
| Pergunta | Onde olhar |
|---|---|
| Quanto de quota consumi? | Página de quota do portal Foundry ou Usages API. |
| Onde posso fazer deploy deste modelo agora? | Model Capacities API. |
| Por que estou vendo 429s abaixo do meu gráfico de uso de tokens? | Headers de resposta como x-ratelimit-limit-tokens, x-ratelimit-remaining-* e retry-after-ms. |
A mudança sutil mas importante: quota não é a mesma coisa que tokens faturados. O rate limiting estima o máximo de tokens processados da requisição no momento da requisição, incluindo max_tokens, e a aplicação de RPM olha para janelas curtas dentro do minuto. Se seu aplicativo explode tráfego ou define max_tokens como "só por precaução", você pode se limitar mesmo quando o Azure Monitor mostra uso calmo.
Ação: Adicione verificações de quota à sua automação de deployment e registre headers de rate-limit em clientes de produção antes de solicitar mais quota.
Atribuição de Custos por Projeto (Project-Level Cost Attribution)
A atribuição de custos por projeto dá às equipes uma resposta mais útil para a pergunta clássica da conta de IA: "qual projeto fez isso?"
Isso parece pequeno, mas muda como você executa ambientes Foundry compartilhados. Se um workspace suporta um protótipo de chatbot, um harness de avaliação, um experimento de fine-tuning e um agente de produção, gráficos de custo no nível de subscription são muito imprecisos. A atribuição por projeto dá às equipes de plataforma uma unidade melhor para orçamentos, chargeback, revisão de anomalias e conversas do tipo "por favor, pare de testar carga no modelo caro às 17h".
Use junto com o Azure Cost Management, não em vez dele. A atribuição de projeto do Foundry ajuda a explicar o uso de modelo e projeto; o Azure Cost Management ainda dá a conta completa através de recursos de suporte como Azure AI Search, Storage, Key Vault, Application Insights, Private Link, máquinas virtuais e ofertas de modelo do Marketplace.
Ação: Revise os gastos por projeto após cada avaliação ou experimento de roteamento de modelo, depois defina orçamentos do Azure no escopo de subscription ou resource group para a infraestrutura ao redor.
Suporte Data-Zone para Modelos OSS (Public Preview)
O suporte a deployment data-zone para modelos de código aberto agora está em public preview. Isso é útil quando a escolha do modelo não é mais a parte difícil — a parte difícil é onde a inferência roda.
Deployments globais são ótimos quando você quer que o Azure roteie tráfego para disponibilidade. Deployments data-zone são o meio-termo para equipes que querem roteamento gerenciado pelo Azure dentro de uma geografia definida pela Microsoft, com mais controle sobre residência de dados do que um deployment global e menos carga operacional do que costurar deployments regionais você mesmo.
Para desenvolvedores construindo com modelos abertos, isso fornece um caminho mais limpo para testar qualidade do modelo, latência e restrições de residência juntos. Não trate o preview como um passe livre para produção, no entanto. Valide a disponibilidade do modelo, quota, filtros de conteúdo e sua estratégia de fallback antes de colocar um workload voltado para o usuário por trás dele.
Ação: Use deployments data-zone para experimentos com modelos OSS que precisam de roteamento com consciência geográfica, depois compare latência e qualidade contra Global Standard e opções regionais.
Assinatura Pay-As-You-Go no Aplicativo
Agora você pode criar uma assinatura pay-as-you-go diretamente dentro do Foundry em vez de desviar pelo portal Azure. Esta não é a atualização mais chamativa do post, mas remove um dos speed bumps de primeira execução mais irritantes: "vim aqui para testar um modelo, por que estou três abas dentro da configuração de faturamento?"
A experiência de usuário não logado também foi renovada, o que ajuda novos desenvolvedores a entender o que o Foundry faz antes de autenticar. Isso importa para capacitação interna. Se você está enviando colegas de equipe, clientes ou participantes de workshop para o Foundry pela primeira vez, menos redirecionamentos de onboarding significam mais tempo gasto fazendo deploy de modelos e menos mensagens do tipo "em qual portal estou?" no chat.
Ação: Atualize seus links de workshop e onboarding para apontar diretamente para o portal Foundry, especialmente para desenvolvedores que ainda não têm uma assinatura Azure pronta.
Experimente o Microsoft Foundry
Conectividade Privada para Azure AI Search
A conectividade privada entre o Azure AI Search e o Foundry é a atualização a ser observada se sua arquitetura de agente inclui retrieval-augmented generation (RAG) sobre dados empresariais.
Em uma configuração Foundry com isolamento de rede, o Azure AI Search pode ser alcançado através de um private endpoint em vez de rede pública. Isso significa que a perna de recuperação do seu fluxo de agente — consulta, top-k results, grounding chunks, metadados — pode permanecer dentro do limite de rede aprovado. Isso é especialmente importante quando seu índice de pesquisa contém documentos internos sensíveis, registros de clientes ou dados regulamentados que não devem trafegar por endpoints públicos.
O detalhe de implementação que os desenvolvedores precisam lembrar: Search privado com uma ferramenta de agente Foundry privada é suportado no novo caminho do portal Foundry, e sua arquitetura deve usar recursos bring-your-own para Storage, Azure AI Search e Azure Cosmos DB quando você precisar de isolamento de rede ponta a ponta. Verifique também o suporte da ferramenta. Ferramentas MCP, Azure AI Search, OpenAPI, Azure Functions e Agent-to-Agent (A2A) podem rodar através do caminho VNET; algumas ferramentas ainda usam endpoints públicos ou ainda não são suportadas em ambientes isolados.
Ação: Se seu agente RAG usa Azure AI Search, mova a conexão Search para seu design de isolamento de rede em vez de tratá-la como um detalhe de camada de aplicativo.
Fala e Compreensão de Conteúdo
Atualizações de Fala
Quatro capacidades de fala foram lançadas em maio:
| Recurso | O que faz |
|---|---|
| Transcrição ao vivo local | Capacidade de transcrição ao vivo local para cenários de fala no Foundry |
| Fala personalizada para Fast Transcription | Suporte a modelo de fala personalizado estendido para transcrição rápida |
| Personalização da API Fast Transcribe | Suporte de personalização para Fast Transcribe API (private preview) |
| Suporte estéreo para STT em tempo real | Fidelidade de áudio multicanal para speech-to-text em tempo real |
Os itens de fala personalizada e Fast Transcribe são particularmente relevantes se você está executando transcrição específica de domínio — vocabulários médico, jurídico ou técnico que se beneficiam de modelos personalizados. O suporte estéreo importa para cenários de call center e reuniões onde você precisa distinguir locutores entre canais.
Ação: Se você está usando modelos de fala personalizados, teste-os com Fast Transcription para um retorno mais rápido em áudio específico de domínio.
Experimente Fast Transcription
Melhorias de Content Understanding (GA)
Content Understanding teve um forte maio. Os analisadores de leitura e layout atingiram GA — estes são os primitivos de extração de documentos que alimentam pipelines RAG, processamento de formulários e workflows de inteligência de documentos.
Junto com o GA:
- Conector Logic App: Conecte workflows de extração de Content Understanding em pipelines de automação mais amplos via Logic Apps. Se você está construindo processamento de documentos que alimenta workflows de negócios, este é o ponto de integração.
- Content Understanding no Foundry: Parte da modernização mais ampla da UX dentro do Foundry — as capacidades de Content Understanding são exibidas na nova experiência do portal.
- Playground NER para TA4H: Playground de próxima geração para reconhecimento de entidade nomeada (NER) em workflows de Text Analytics for Health.
Ação: Se você está usando Content Understanding em preview, seus analisadores de leitura e layout agora são GA. Teste o conector Logic App para pipelines de automação de documentos ponta a ponta.
Foundry Local
Foundry Local 1.1
O Foundry Local 1.1 foi lançado em maio com quatro recursos principais para IA no dispositivo:
- Transcrição de áudio ao vivo — streaming de speech-to-text em tempo real usando o modelo Nemotron ASR (nemotron-speech-streaming-en-0.6b), com uma superfície de API compatível com OpenAI Realtime. Disponível nos SDKs Python, JavaScript, C# e Rust.
- Text embeddings — geração de embeddings no dispositivo via um novo cliente de embedding. Acompanha o qwen3-0.6b-embedding.
- Qwen 3.5 Vision — modelo de linguagem multimodal de visão rodando totalmente no dispositivo.
- WebGPU execution provider — entregue como um plugin separado para download para manter a instalação padrão leve (~20 MB base).
O SDK JavaScript também eliminou sua dependência FFI koffi em favor de um addon N-API pré-compilado — instalações mais rápidas e um node_modules mais enxuto. O SDK C# agora tem duplo alvo netstandard2.0 e net8.0, permitindo suporte a .NET Framework 4.6.1+ e Unity.
O Qwen 3.5 Vision transforma o Foundry Local de "modelo de chat local" em "modelo local que pode inspecionar as mesmas capturas de tela, diagramas, quadros brancos e fotos de produto que seu aplicativo já manipula." Sem etapa de upload, sem viagem de ida e volta para a nuvem, sem momento constrangedor de "por favor, ignore os dados sensíveis do cliente nesta captura de tela".
Use uma imagem local pequena como esta:
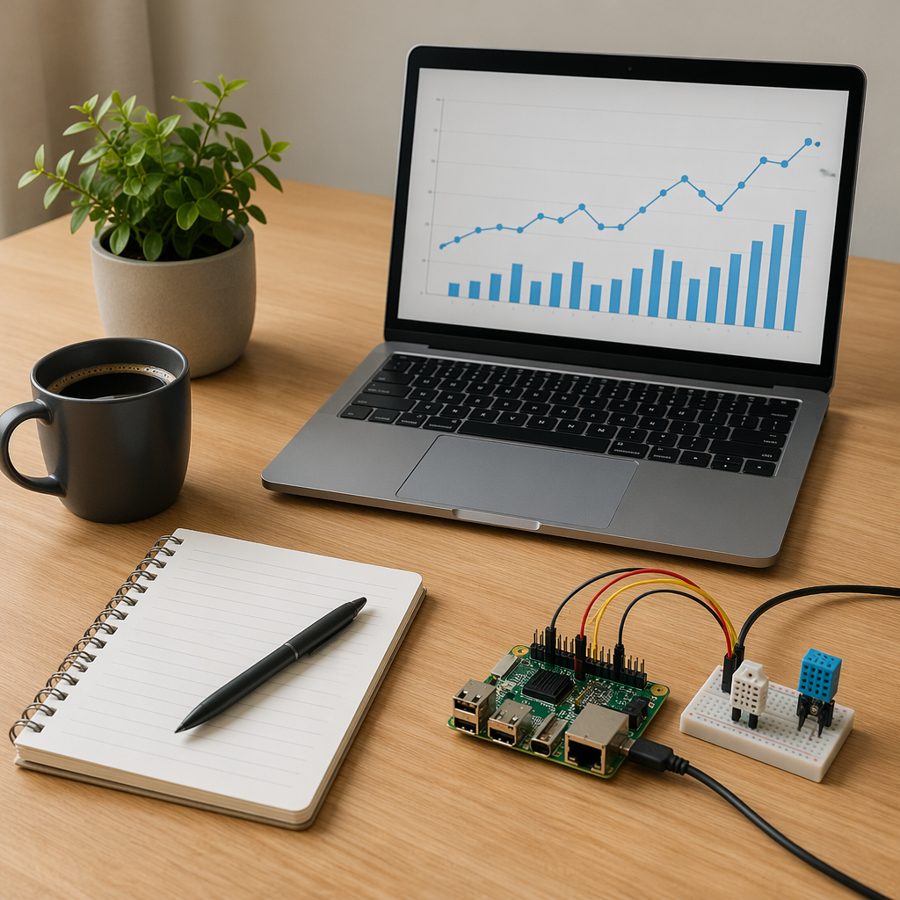
Depois passe a imagem para a API Responses local:
import base64
import io
from openai import OpenAI
from PIL import Image
from foundry_local_sdk import Configuration, FoundryLocalManager
config = Configuration(app_name="foundry_local_vision_demo")
FoundryLocalManager.initialize(config)
manager = FoundryLocalManager.instance
model = manager.catalog.get_model("qwen3-vl-2b-instruct")
if not model.is_cached:
model.download()
client = None
service_started = False
model.load()
try:
manager.start_web_service()
service_started = True
client = OpenAI(base_url=manager.urls[0].rstrip("/") + "/v1", api_key="notneeded")
image = Image.open("images/foundry-local-qwen-vision-sample.jpg")
image.thumbnail((512, 512))
buffer = io.BytesIO()
image.save(buffer, format="JPEG")
image_b64 = base64.b64encode(buffer.getvalue()).decode()
vision_input = [
{
"type": "message",
"role": "user",
"content": [
{
"type": "input_text",
"text": "Describe the scene and identify anything useful for a developer demo.",
},
{
"type": "input_image",
"image_data": image_b64,
"media_type": "image/jpeg",
},
],
}
]
stream = client.responses.create(
model=model.id,
input="placeholder",
extra_body={"input": vision_input},
stream=True,
)
for event in stream:
if getattr(event, "type", None) == "response.output_text.delta":
print(getattr(event, "delta", ""), end="", flush=True)
finally:
if client is not None:
client.close()
if service_started:
manager.stop_web_service()
model.unload()
Saída de exemplo:
This image depicts a typical developer's workspace, likely for a data scientist or software developer working on a project involving data analysis and development.
The scene is a wooden desk with a modern, functional setup, suggesting a focused and creative work environment.
- Laptop: A silver laptop is the central focus. Its screen displays a digital graph, which is a bar chart with blue bars and an accompanying line graph, indicating some form of data analysis or progress tracking.
- Development Tools: A small, green circuit board with USB ports and other connections is connected via cables to a breadboard-style adapter.
- Notebook and Pen: A spiral-bound notebook and a pen are placed on the desk, indicating that the developer is taking notes and documenting their work.
Use o Foundry Local para carregar o modelo, iniciar o web service local, depois chame-o através da mesma API Responses no estilo OpenAI que você usaria em outros lugares. Se seu aplicativo já tem captura de tela, preview de documento ou fluxos de upload de imagem, esta é uma maneira de muito baixa fricção para adicionar raciocínio visual local.
Ação: Atualize para foundry-local-sdk 1.1+ e experimente o Qwen 3.5 Vision com uma das capturas de tela ou diagramas reais do seu aplicativo.
Foundry Local 1.2
O Foundry Local 1.2 seguiu em maio com melhorias operacionais:
- Downloads canceláveis — downloads de modelos e execution providers podem ser cancelados usando o idioma nativo de cada plataforma (CancellationToken em C#, AbortController em JS, threading.Event em Python).
- ASR multilíngue — reconhecimento de fala estendido além do inglês.
- Linux ARM64 — novo alvo de plataforma para deployments aarch64.
- Upgrade WinML 2.0 — não requer mais o bootstrapper WinAppSDK Runtime, estende o suporte para Windows 10.0.18362.0+, e adiciona WebGPU EP e atualização automática de plugin.
- ONNX Runtime 1.26.0 + GenAI 0.14.0 — upgrades de runtime com downloads baseados em região e sem mais timeouts de 5 minutos em modelos grandes.
Para aplicativos Python, o caminho de upgrade permanece simples:
pip install --upgrade foundry-local-sdk
Ação: Atualize para foundry-local-sdk 1.2 para fala multilíngue, suporte ARM64 e downloads canceláveis.
Veja as Notas de Lançamento 1.2
Foundry Agent Service
A atualização mais interessante de maio para desenvolvedores de agentes é a nova superfície de pré-lançamento no azure-ai-projects: skills e toolboxes. Este é o caminho vanilla do Foundry Agent Service — sem exigir o Microsoft Agent Framework.
O formato útil é: registre orientação reutilizável como uma skill de projeto, agrupe-a em uma toolbox, exponha essa toolbox como um endpoint Model Context Protocol (MCP) e anexe o endpoint MCP a um prompt agent. Eu testei isso com um cenário onde o agente do Zava Studio revisa capturas de tela de produtos brutas e as transforma em orientação de design.
Aqui está a entrada bruta que o agente recebeu:
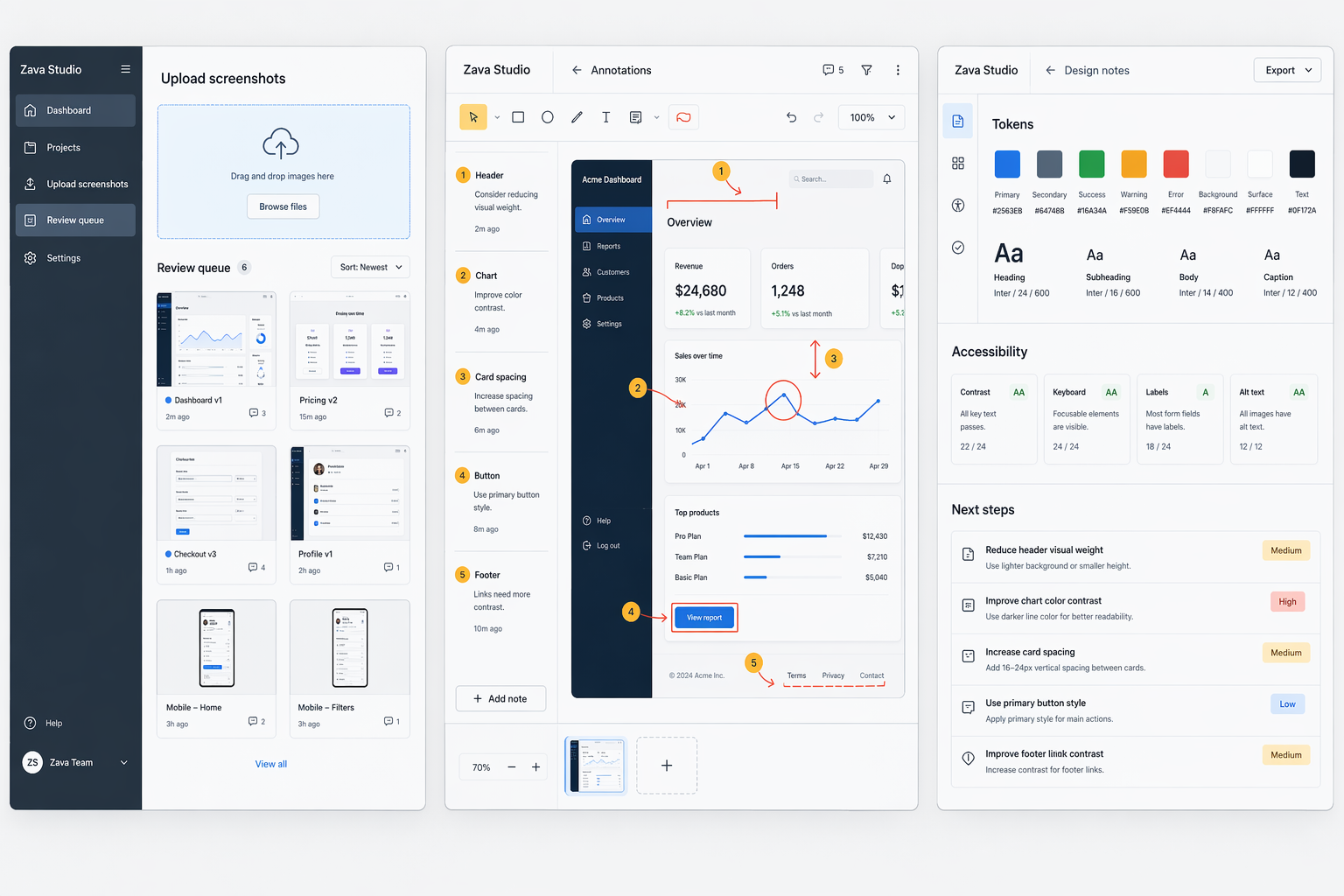
O agente usou gpt-5.4 com reasoning.effort="high", mais uma skill de frontend-design registrada através das APIs de skill do projeto.
import base64
import os
from pathlib import Path
from azure.ai.projects import AIProjectClient, models
from azure.identity import DefaultAzureCredential
endpoint = os.environ["FOUNDRY_PROJECT_ENDPOINT"]
model = "gpt-5.4"
credential = DefaultAzureCredential()
with AIProjectClient(
endpoint=endpoint,
credential=credential,
allow_preview=True,
) as project_client, project_client.get_openai_client() as openai_client:
# 1. Register reusable design guidance as a project skill.
skill = project_client.beta.skills.create(
"zava-frontend-design",
inline_content=models.SkillInlineContent(
description=(
"Zava Studio frontend-design skill: distinctive UI review "
"guidance for product screenshot workflows."
),
instructions=Path("skills/frontend-design/SKILL.md").read_text(),
metadata={"scenario": "Zava Studio"},
),
default=True,
)
# 2. Put the skill in a toolbox with tool search enabled.
toolbox = project_client.beta.toolboxes.create_version(
"zava-design-toolbox",
description=(
"Zava Studio design-review toolbox: frontend-design skill plus "
"a named web search tool for current UI guidance."
),
tools=[
models.WebSearchTool(
type="web_search",
name="zava_frontend_research",
description=(
"Find frontend design guidance, product UI references, "
"accessibility guidance, and verification ideas for Zava Studio."
),
search_context_size="low",
),
models.ToolboxSearchPreviewTool(
type="toolbox_search_preview",
name="zava_tool_search",
),
],
skills=[
models.ToolboxSkillReference(
type="skill_reference",
name=skill.name,
version=skill.version,
)
],
)
# 3. Attach the toolbox to a prompt agent through its MCP endpoint.
token = credential.get_token("https://ai.azure.com/.default").token
toolbox_mcp_url = (
f"{endpoint.rstrip('/')}/toolboxes/zava-design-toolbox/"
f"versions/{toolbox.version}/mcp?api-version=v1"
)
toolbox_mcp_tool = models.MCPTool(
server_label="zava_design_toolbox",
server_url=toolbox_mcp_url,
authorization=token,
headers={"Foundry-Features": "Toolboxes=V1Preview"},
require_approval="never",
)
agent = project_client.agents.create_version(
"zava-design-agent",
definition=models.PromptAgentDefinition(
kind="prompt",
model=model,
instructions=(
"You are Zava Studio's frontend design agent. Use the attached "
"rough screenshots as visual context. First use tool_search, "
"then call_tool when useful. Return exactly three bullets: "
"aesthetic direction, concrete UI change, anti-pattern to avoid."
),
reasoning=models.Reasoning(effort="high"),
tools=[toolbox_mcp_tool],
),
)
# 4. Invoke the agent with rough product screenshots as image input.
image_b64 = base64.b64encode(
Path("images/zava-rough-product-screenshots.png").read_bytes()
).decode("ascii")
response = openai_client.responses.create(
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": (
"Review these Zava Studio rough product screenshots. "
"The product turns messy product screenshots into "
"clear design-review notes."
),
},
{
"type": "input_image",
"image_url": f"data:image/png;base64,{image_b64}",
},
],
}
],
extra_body={
"agent_reference": {
"name": agent.name,
"type": "agent_reference",
}
},
)
print(response.output_text)
Saída de exemplo da execução ao vivo:
- Aesthetic direction: Treat Zava as a calm review workbench for turning raw screenshots into decisions: neutral surfaces (canvas #F6F7F9, panel #FFFFFF, border #D9DEE7, text #0F172A / #475569), one blue action accent (#2563EB), semantic colors only for severity, 12px radius, 8/16/24 spacing, and very light elevation so the screenshot and annotations — not the app chrome — stay primary.
- Concrete UI change: Recompose the first viewport into one desktop-first tri-pane flow — left 280px intake/review queue, center flexible annotation canvas, right 360px generated notes — with the right pane opening on Actionable notes and moving Tokens / Accessibility into tabs or accordions below; that makes the product promise visible in one glance: "messy screenshot in → clear review notes out." Verify on a 1440px desktop that all three panes fit without horizontal scroll, tab order moves left → center → right, spacing stays on an 8px grid, and text/controls meet at least 4.5:1 contrast.
- Anti-pattern to avoid: Don't turn this into three disconnected admin screens or a mini-Figma clone with dense toolbars, loud gradients, and multicolor cards everywhere; that overbuilds the UI, increases cognitive load, and hides the core before/after value of the product.
Ação: Experimente azure-ai-projects==2.2.0 com uma pequena skill de projeto e toolbox. Comece com os samples CRUD para beta.skills, depois use o padrão MCP de toolbox-search quando quiser que agentes descubram ferramentas dinamicamente.
Navegue pelos samples azure-ai-projects
Changelog SDK & Linguagens (Maio 2026)
A história do SDK em maio é sobre expandir a superfície de preview — agentes externos, gerenciamento de pesos de modelo, rotinas, jobs de otimização e memory stores todos chegaram como operações beta. O padrão é o mesmo de abril: core GA estável, namespace .beta de movimento rápido.
Python
azure-ai-projects 2.2.0
A maior adição é o sub-cliente .beta.models para o registro de pesos de modelo de IA — criar, listar, atualizar, deletar e recuperar credenciais para versões de modelo. Isso abre workflows programáticos de gerenciamento de modelos que antes exigiam o portal.
Outros destaques:
- Integração de agente externo (preview) — novo
ExternalAgentDefinitionpara integração de agentes de terceiros. - Novas ferramentas de agente —
FabricIQPreviewTooleToolboxSearchPreviewTool. - Optimization jobs — criar, monitorar e promover candidatos de otimização para agentes hospedados.
- Routines — CRUD de automação acionada via
beta.routines. - Data generation jobs — geração de dados sintéticos via
beta.datasets. - Memory store item CRUD — gerenciamento de memória individual em
beta.memory_stores. - Gerenciamento versionado de skills — criar, listar, baixar, deletar versões de skill.
As breaking changes estão confinadas ao namespace .beta: isolation_key removido de operações de sessão, várias renomeações de classe (AgentEndpoint → AgentEndpointConfig, SkillObject → SkillDetails, Target → EvaluationTarget), e mudanças de assinatura em métodos de skills e taxonomia de avaliação.
pip install --upgrade azure-ai-projects==2.2.0
Ação: Atualize para azure-ai-projects==2.2.0. Breaking changes afetam apenas a superfície .beta — operações estáveis permanecem inalteradas.
JavaScript / TypeScript
@azure/ai-projects 2.1.1 + 2.2.0
O patch 2.1.1 corrige operações de listagem de agentes que só retornavam a primeira página de resultados devido à falta de paginação baseada em cursor — atualize se você tem mais de uma página de agentes.
O 2.2.0 espelha o lançamento Python: definições de agente externo, registro de pesos de modelo, rotinas, jobs de otimização, CRUD de memory store, FabricIQPreviewTool, WorkIQPreviewTool e ToolboxSearchPreviewTool. Mesmas breaking changes com escopo beta que o Python.
npm install @azure/[email protected]
Ação: Pegue o 2.1.1 imediatamente para a correção de paginação. Mude para o 2.2.0 quando estiver pronto para a nova superfície beta.
.NET
Azure.AI.Projects 2.1.0-beta.2 + 2.1.0-beta.3
O 2.1.0-beta.2 adiciona o cliente DataGenerationJobs para geração de dados sintéticos — útil para criar conjuntos de dados de avaliação programaticamente. Novos samples cobrem insights de cluster de avaliação, avaliadores assistidos por IA e classificação de imagens.
O 2.1.0-beta.3 adiciona o cliente AIProjectModels para gerenciamento de pesos de modelo e CRUD de items de memory store.
Ação: Atualize para Azure.AI.Projects 2.1.0-beta.3 para a superfície de preview mais recente. Operações GA permanecem na linha estável 2.0.x.
Java
azure-ai-projects 2.1.0-beta.1
Java adiciona SkillsClient e SkillsAsyncClient para gerenciamento de skills ponta a ponta (criar, baixar, listar, atualizar, deletar). Um novo método buildAgentScopedOpenAIClient(agentName) em AIProjectClientBuilder retorna um cliente OpenAI com escopo definido para um endpoint de agente específico — útil quando você precisa de roteamento por agente.
Também adiciona threshold a EvaluatorMetric e novas propriedades em CodeBasedEvaluatorDefinition para workflows de avaliador baseados em código.
Ação: Atualize para com.azure:azure-ai-projects:2.1.0-beta.1 para gerenciamento de skills e clientes com escopo de agente.
Recursos e Comunidade
Registre-se para o Microsoft Build — O Microsoft Build acontece de 2 a 3 de junho de 2026, em São Francisco e online. Registre-se agora, faça login e salve as sessões do Microsoft Foundry em sua agenda para assisti-las online.
| Sessão | Data/Horário | Palestrantes | Descrição |
|---|---|---|---|
| Confident model selection and integration with Microsoft Foundry (BRK230) | June 2, 12:30-1:15 PM PT | Yina Arenas, Naomi Moneypenny | Escolha, integre e valide modelos de IA no Microsoft Foundry, incluindo benchmarking e workflows de desenvolvedor integrados. |
| Govern open-source AI agents, any framework, any scale (BRK250) | June 2, 2:30-3:15 PM PT | Sarah Bird, Mehrnoosh Sameki | Aprenda padrões de governança para Microsoft Agent Framework e stacks de agentes de código aberto, incluindo avaliações e controles de risco. |
| From prototype to production: build and run agents at scale (BRK241) | June 2, 3:45-4:30 PM PT | Tina Schuchman, Jeff Hollan | Caminhe pelo ciclo de vida para agentes de nível de produção com Foundry Agent Service e Microsoft Agent Framework. |
| From observability to ROI for AI agents on any framework (BRK252) | June 2, 3:45-4:30 PM PT | Sebastian Kohlmeier, Filisha Shah | Cubra tracing cross-framework, avaliações, observabilidade de produção e medição de ROI para agentes de IA. |
| Orchestrate special agents with Nemotron models on Microsoft AI Foundry (BRKSP94) | June 2, 3:45-4:30 PM PT | Stephen McCullough | Roteie tarefas entre modelos de fronteira, NVIDIA Nemotron e modelos locais para arquiteturas de IA agentivas em camadas. |
| Deploy. Observe. Learn. Reinforcement learning for production agents (BRK231) | June 2, 5:00-5:45 PM PT | Alicia Frame, Omkar More | Use fine-tuning e reinforcement learning no Microsoft Foundry para melhorar agentes de produção com sinais de uso reais. |
| Build context-aware agents at scale with Microsoft IQ (BRK240) | June 2, 5:00-5:45 PM PT | Marco Casalaina | Aprenda como Foundry IQ, Fabric IQ e Work IQ fornecem uma camada de inteligência empresarial para agentes de IA. |
| Context engineering for agents: connect agents with enterprise knowledge (BRK246) | June 3, 9:00-9:45 AM PT | Pablo Castro Castro | Explore Foundry IQ, Azure AI Search, fontes de conhecimento, retrieval-augmented generation (RAG) agentivo e segurança empresarial. |
| Local models, developer control, and the future of AI runtimes (BRK235) | June 3, 10:15-11:00 AM PT | Parth Sareen | Aprenda como a execução de modelo local e híbrida pode remodelar workflows de desenvolvedor, privacidade e experimentação. |
| Claw and agent harness in Microsoft Foundry (BRK243) | June 3, 11:30 AM-12:15 PM PT | Glenn Condron, Amanda Foster, Shawn Henry | Aprofunde-se em sistemas multi-agente, padrões de agente Claw, arquitetura de agentes hospedados, triggers, gerenciamento de estado e acesso a arquivos. |
| Build secure and enterprise-ready agents with Agent 365 (BRK251) | June 3, 11:30 AM-12:15 PM PT | Neta Haiby | Construa agentes prontos para empresa com visibilidade em tempo de execução, acesso consciente de identidade, proteção de dados e governança baseada em políticas. |
| Build distributed agentic apps from edge to cloud (BRKSP92) | June 3, 11:30 AM-12:15 PM PT | Colin Helms, Eddy Rodriguez | Projete e execute aplicações agentivas multi-agente através de ambientes cliente, edge e Azure. |
| Train and deploy custom OSS reasoning models with Foundry (BRK232) | June 3, 2:45-3:30 PM PT | Vijay Aski, Manoj Bableshwar, Chris Lauren | Treine e ajuste modelos de raciocínio de código aberto no Microsoft Foundry com workflows code-first e ambientes de reinforcement learning curados. |
| Turn your agents into action: connect tools, APIs, and data (BRK242) | June 3, 4:00-4:45 PM PT | Ronak Chokshi, Joe Filcik, Maria Naggaga | Veja como conectar agentes com conjuntos de ferramentas, APIs e dados sem sobrecarregar as janelas de contexto. |
Quer os catálogos completos de breakout online? Navegue por Agentes & apps, IA Responsável e Trabalhando com modelos.
Junte-se à comunidade — Conecte-se com mais de 50.000 desenvolvedores no Discord, faça perguntas no GitHub Discussions, ou assine via RSS para receber este resumo mensalmente.
Perguntas Frequentes
-
O que é trace-based evaluation e por que isso é relevante para meu time?
Trace-based evaluation permite que você avalie agentes de IA usando traces reais de produção, em vez de datasets sintéticos. Isso é relevante porque seus agentes se comportam de forma diferente em produção — e avaliá-los com dados reais (seja no Foundry, GCP ou AWS) dá mais precisão para detectar problemas antes que impactem usuários. -
Como o Managed VNET GA afeta a arquitetura de rede dos meus projetos?
Managed VNET em GA significa que o Foundry pode provisionar isolamento de rede gerenciado para agentes. Você escolhe entre permitir tráfego de internet irrestrito ou apenas saídas aprovadas via service tags e private endpoints. Atenção: a escolha do modo de isolamento é definitiva na criação do projeto — não é possível desativar ou converter depois. -
Quais modelos novos chegaram ao Foundry em maio e como escolher entre eles?
Chegaram Grok 4.3 (da xAI), DeepSeek V4, e GPT-5 Reinforcement Fine-Tuning (RFT) em gated GA. Grok 4.3 é indicado para workloads avançados com agentes, DeepSeek V4 para raciocínio e código open-weight, e GPT-5 RFT para fine-tuning com reinforcement learning. Avalie cada um com seus próprios datasets antes de mover tráfego — especialmente Grok, que tem maiores riscos de jailbreak. -
O que são os agentes on-device (MagenticBrain, Fara1.5, MagenticLite) e como usá-los?
São projetos da Microsoft Research que rodam localmente: MagenticLite é o app/harness, MagenticBrain faz planejamento/orquestração, e Fara1.5 foca em automação de navegador. Funcionam melhor juntos via endpoints /v1 compatíveis com OpenAI. Úteis para empresas que precisam de agentes com privacidade de dados — sem enviar screenshots ou arquivos para a nuvem. -
O que muda com a atribuição de custos por projeto (project-level cost attribution)?
Permite rastrear gastos com LLMs por projeto dentro do Foundry, facilitando orçamento, chargeback e identificação de anomalias. Use junto com o Azure Cost Management, que cobre recursos de infraestrutura como Azure AI Search, Storage e Key Vault. É um passo importante para FinOps em ambientes multi-projeto.
Artigo originalmente publicado por Nick Brady em Azure Updates - Latest from Azure Charts.
