

Kit de Observabilidade de IA para Agentes do Microsoft Foundry: Como Levar Seus Agentes para Produção com Confiança
TL;DR: Este artigo analisa o AI Observability Starter Kit da Microsoft, que provisiona em um único comando um ambiente completo de observabilidade para agentes Foundry: telemetria OpenTelemetry, 8 avaliadores integrados, avaliador customizado, varredura red-team automatizada e alertas. A conclusão principal é que a observabilidade não é opcional para sistemas agenticos – é pré-requisito para operar com confiança.
1. De dashboards verdes a observabilidade de nível de produção
Seu agente de IA está em produção. O load balancer mostra zero erros. O dashboard do Application Insights está verde. Mas várias coisas podem estar erradas:
- Um deployment de modelo não existe. O agente aponta para um modelo inexistente. Cada requisição gera um erro no nível do chat, mas a resposta HTTP ainda retorna 200 porque o framework do agente capturou a exceção internamente.
- Uma tool retornou dados incorretos. Um usuário pede ordens do cliente C999. O agente chama a tool certa, mas ela lança um LookupError. O agente responde com um pedido de desculpas educado, o HTTP retorna 200, e o erro fica invisível a menos que você rastreie o span
execute_tool. - O modelo respondeu a um prompt de segurança. Um usuário pede conteúdo violento fictício. O modelo obedece. Nenhum filter capturou, nenhum evaluator pontuou, nenhum alerta disparou.
Essas falhas não aparecem em logs tradicionais ou em dashboards genéricos. Elas exigem um tipo diferente de observabilidade, que combina cinco capacidades:
- Traces instrumentados usando convenções semânticas OpenTelemetry (OTel) para GenAI, de forma que cada chamada de modelo e execução de tool se torne um span consultável.
- Avaliadores automatizados de qualidade que pontuam raciocínio, resolução de intenção e uso de tools em tráfego real, não em fixtures de teste.
- Testes red-team adversarial que exploram limites de segurança com prompts de ataque gerados automaticamente antes que usuários reais o façam.
- Alertas baseados em scheduled-query que disparam com base em taxa de erro e regressão de latência, não apenas em uptime.
- Dashboards que exibem tokens, modelos, tools e erros em um único lugar para operadores e plantão.
Nenhuma dessas peças é nova. A parte difícil é conectá-las corretamente. O starter kit, disponível no repositório GitHub, entrega essa conexão (agente instrumentado, evaluators vinculados aos campos de trace certos, taxonomia de red-team, dashboard Grafana importável e verificações pós-deploy) em um único comando, para que você comece de uma baseline conhecida em vez de montar tudo manualmente.
1.1 Como o fluxo funciona
Um prompt de usuário entra no hosted agent, que chama o modelo (ex.: gpt-4o-mini) e opcionalmente executa uma ou mais tools (consultas de pedidos, fornecedores, clima, dados). Cada chamada de modelo e execução de tool emite spans OpenTelemetry que são ingeridos automaticamente no Azure Application Insights, sem necessidade de SDK adicional além de definir ENABLE_INSTRUMENTATION=true no manifest do agente.
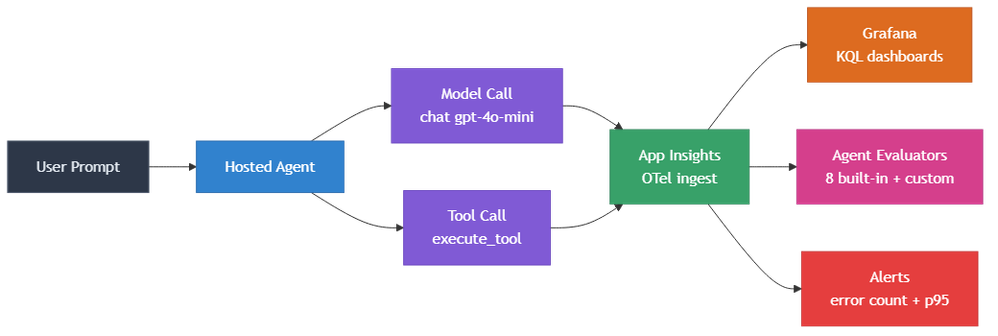
A partir do Application Insights, a telemetria alimenta três consumidores downstream:
- Dashboards Grafana consultam o workspace Log Analytics via KQL (Kusto Query Language) para renderizar painéis operacionais (uso de tokens, latência, taxas de erro, distribuição por modelo).
- Agent evaluators puxam traces recentes e os pontuam contra 8 verificações de qualidade integradas, além de evaluators customizados registrados. Os resultados aparecem no painel de Avaliações do Microsoft Foundry.
- Alertas de scheduled-query disparam quando a contagem de erros ou a latência p95 ultrapassam limites em janelas de 15 minutos.
O ponto de design chave: o agente não sabe da existência de dashboards, evaluators ou alertas. Ele apenas emite spans. Tudo downstream é conectado através do Application Insights como backbone único de telemetria.
1.2 Definição do agente
Um Foundry-hosted agent é um agente de IA containerizado que o Microsoft Foundry gerencia, deploya e escala: você fornece o código Python (main.py) e um pequeno manifesto YAML (agent.yaml), o Foundry cuida do runtime, do pipeline OTel e da identidade por agente. Os quatro agentes deste kit compartilham código, tools e instruções de sistema idênticas; a única diferença é o deployment de modelo que cada um usa:
| Agente | Modelo | Propósito |
|---|---|---|
| agent-framework-agent-basic-responses | gpt-4o-mini (via ${MODEL_DEPLOYMENT_NAME}) |
Agente principal com 6 funções @tool. Usado para telemetria, avaliação e população de dashboards. |
| agent-framework-agent-gpt5-mini | gpt-5-mini (hardcoded) | Agente irmão para comparação de latência e tokens entre modelos. |
| agent-framework-agent-gpt41-mini | gpt-4.1-mini (hardcoded) | Agente irmão para comparação entre modelos. |
| agent-framework-agent-broken-model | nonexistent-model-deployment-xyz (hardcoded) | Deliberadamente quebrado. Cada requisição dispara um erro de chat, populando o painel Gen AI Errors. |
O código do agente cria um FoundryChatClient conectado ao modelo, define um Agent com um system prompt de assistente de compras e registra seis tool functions: get_orders, find_suppliers_for_request, get_company_supplier_info, get_current_utc_date, get_weather e roll_dice. Algumas tools são projetadas para lançar erros em entradas específicas (ex.: cliente C999 lança LookupError), gerando a telemetria de erro que os dashboards e evaluators consomem.
Duas variáveis de ambiente controlam a telemetria:
ENABLE_INSTRUMENTATION=trueativa spans filhos OpenTelemetry (um span por chamada LLM e por execução de tool). Sem ela, apenas o span paiinvoke_agenté emitido e o painel Agents fica vazio.ENABLE_SENSITIVE_DATA=truecaptura o texto completo do prompt e da resposta nos spans, necessário para que os evaluators pontuem a qualidade da resposta.
2. Deploy e execução
Tudo neste kit é automatizado. Um único script PowerShell provisiona a infraestrutura, deploya os agentes, semeia tráfego, executa avaliações, configura alertas e valida o resultado. O custo por execução completa é de alguns centavos (cerca de US$ 0,03/dia enquanto estiver rodando). O teardown remove tudo.
2.1 O que o starter kit contém
| Componente | O que faz | Para que serve |
|---|---|---|
| 4 Foundry-hosted agents | gpt-4o-mini, gpt-5-mini, gpt-4.1-mini e um agente quebrado | Comparar latência, tokens e taxas de erro entre modelos na mesma carga de trabalho |
| Application Insights + Log Analytics | Recebe traces OpenTelemetry (convenções semânticas GenAI) | Rastrear falhas de tools até invocações específicas, mesmo quando o HTTP retorna 200 |
| Grafana for Azure Monitor | Dashboards customizados para tokens, latência, operações e distribuição de modelos | Monitorar consumo de tokens ao longo do tempo e identificar prompts ou agentes que consomem tokens desproporcionais |
| Agent evaluators | 8 evaluators integrados (sistema + processo) executados em lote sobre traces do Application Insights | Validar qualidade do agente sob demanda: resolução de intenção, adesão à tarefa, precisão de tools e mais |
| Custom code-based evaluator | Verifica cada resposta por uma frase de disclaimer de compliance obrigatória | Aplicar políticas específicas de domínio (frases de compliance, verificações de formato, regras regulatórias) |
| Red-team scan | Sondas adversarial usando estratégias Flip e Base64 com 3 evaluators de segurança | Detectar saídas inseguras automaticamente, sondando limites de segurança antes que usuários reais o façam |
| 2 scheduled-query alerts | Contagem de erros (sev 2) e latência p95 (sev 3) em janelas de 15 minutos | Alertar sobre os sinais que realmente importam: picos de erro e regressão de latência |
| Automação end-to-end | Script orquestrador único (run-e2e.ps1) e script de teardown único | Provisionar, exercitar e destruir toda a stack com dois comandos |
2.2 Executando o kit
Pré-requisitos: assinatura Azure com Contributor (ou Owner) mais User Access Administrator, PowerShell 7+ (pwsh), Azure CLI (az) e Azure Developer CLI (azd) instalados e no PATH, az login concluído, e um venv Python 3.13 na raiz do repositório. O script verifica o ambiente virtual, o diretório agent/ e ambos os CLIs antes de fazer qualquer chamada Azure, falhando cedo com instruções claras de correção.
pwsh -NoProfile -File scripts\run-e2e.ps1 `
-Region <region> `
-EnvName <env-name> `
-SubscriptionId <subscription-id>
Exemplo:
pwsh -NoProfile -File scripts\run-e2e.ps1 `
-Region eastus2 `
-EnvName aiobs2-foundry `
-SubscriptionId <subscription-id>
O orquestrador executa 13 fases, cada uma registrada em artifacts/e2e-<timestamp>/phase-NN.log. O tempo total é de aproximadamente 35 a 50 minutos.
Após a execução, valide com:
pwsh -NoProfile -File scripts\validate-deployment.ps1
Isso verifica 8 categorias (26 verificações no total): infraestrutura, deployments de modelo, hosted agents, invocação de agentes, telemetria, avaliação, alertas e RBAC.
2.2.3 Teardown
Para destruir tudo:
pwsh -NoProfile -File scripts\teardown.ps1 -EnvName <env-name>
Isso deleta o resource group, faz purge do soft-delete do Azure AI Services e valida a remoção.
2.2.4 Atualização ad-hoc de tráfego e avaliação
Uma vez deployado, não é preciso reexecutar todo o pipeline de 13 fases para atualizar a telemetria. Use scripts/run-adhoc-traffic-and-eval.ps1 para gerar traces frescos, rodar o batch eval e atualizar a exportação de telemetria.
Tempo total: ~15 min por padrão (~25 min com red-team).
3. Avaliação: agent evaluators e verificações customizadas
Um HTTP 200 OK não significa que o agente respondeu corretamente. Software tradicional tem saídas previsíveis; agentes de IA não. O mesmo prompt pode produzir respostas diferentes entre execuções, e a qualidade pode mudar quando modelos são atualizados, prompts evoluem ou tools mudam. Sem avaliação, você depende de reclamações de usuários para descobrir problemas de qualidade, muitas vezes dias após o dano.
3.1 Dois caminhos de avaliação
O starter kit inclui duas abordagens complementares:
| Caminho | Quando executa | O que verifica | Melhor para |
|---|---|---|---|
| Agent evaluators | Sob demanda (lote sobre traces) | 8 evaluators integrados cobrindo resultados de sistema e qualidade de processo | Medir qualidade end-to-end do agente e uso de tools |
| Custom evaluators | Sob demanda (lote sobre traces) | Qualquer regra específica de domínio (frases de compliance, verificações de formato, política) | Requisitos empresariais além dos evaluators integrados |
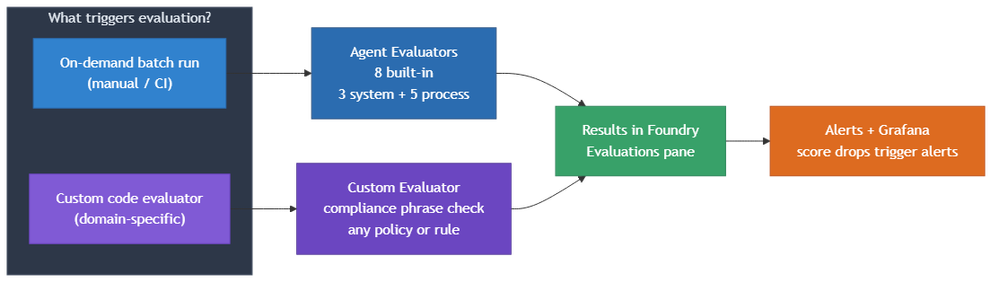
3.2 Agent evaluators
O Microsoft Foundry fornece 9 evaluators de agente integrados, divididos em duas categorias: system evaluators (examinam o resultado end-to-end: task adherence, task completion, intent resolution) e process evaluators (examinam cada etapa do workflow: tool call accuracy, tool selection, tool input accuracy, tool output utilization, tool call success). O 9º evaluator, Task Navigation Efficiency, requer ground truth e não está incluído na execução padrão.
Resultados de uma execução validada (11 traces pontuados em 8 evaluators):
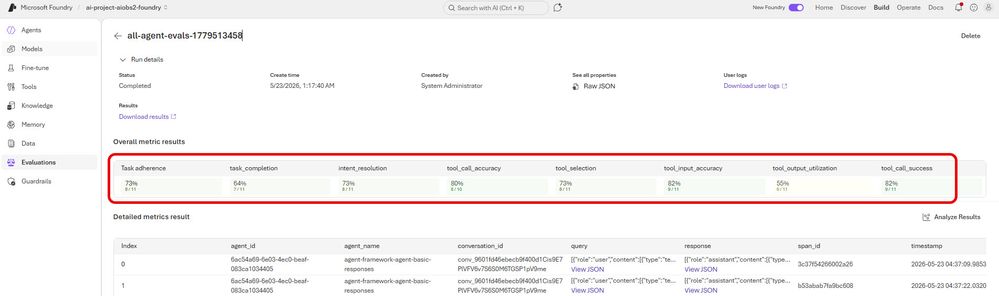
| Evaluator | Score | Destaque |
|---|---|---|
| task_adherence | 73% (8/11) | Seguiu as instruções do sistema em 8 de 11 casos |
| task_completion | 64% (7/11) | 4 falhas incluem prompts intencionais de erro |
| intent_resolution | 73% (8/11) | Identificou e endereçou corretamente a intenção do usuário |
| tool_call_accuracy | 80% (8/10) | Tools certas com parâmetros corretos |
| tool_selection | 73% (8/11) | Sem chamadas de tool desnecessárias |
| tool_input_accuracy | 82% (9/11) | Parâmetros corretamente formatados e contextualizados |
| tool_output_utilization | 55% (6/11) | Evaluator mais rigoroso: o agente usou os resultados da tool na resposta? |
| tool_call_success | 82% (9/11) | 2 falhas são os triggers intencionais de erro |
Cada evaluator requer um data_mapping que informa ao Foundry quais campos de trace ler. Evaluators de sistema precisam de query + response; evaluators de processo adicionam tool_definitions e tool_calls. Todos também exigem deployment_name como parâmetro de inicialização. A falta de qualquer um produz um erro MissingRequiredDataMapping.
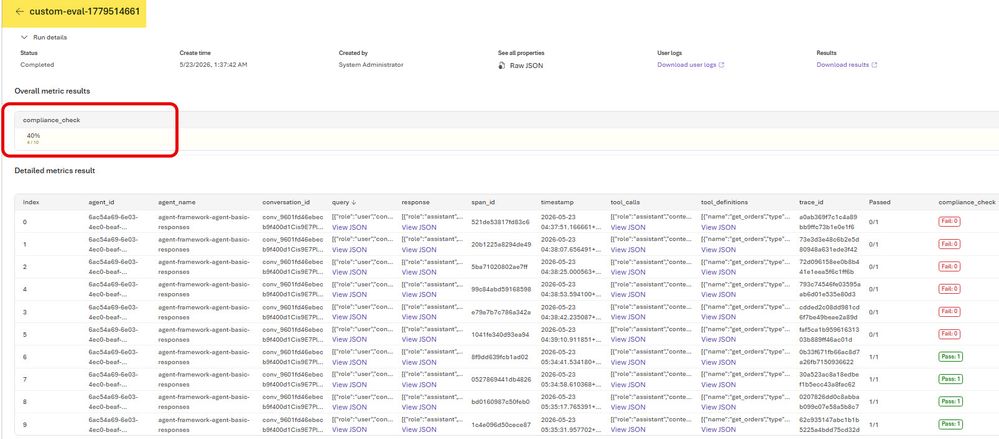
3.3 Custom evaluator: verificação de frase de compliance
O kit demonstra o padrão code-based com um verificador de disclaimer de compliance. O workflow tem três etapas: (1) escrever uma função grade(sample, item) que retorna 1.0 ou 0.0, (2) registrá-la no Foundry via script, (3) incluí-la no batch evaluation.

Resultados de uma execução validada (10 traces): o evaluator compliance_check obteve 40% (4 de 10 traces passaram). Os 4 traces que passaram vieram de prompts que explicitamente pediam o disclaimer; as 6 falhas eram respostas normais sem ele. Substitua pela sua lógica, re-registre, e o mesmo padrão funciona para qualquer verificação de política, formato ou regulatória.
4. Teste red-team: varredura automatizada de segurança
Evaluators de qualidade verificam se o agente respondeu bem. Red-team verifica se ele pode ser enganado a responder mal: usuários adversários que tentam provocar respostas prejudiciais, fora do tópico ou violadoras de política. Modelos que passam evaluators de qualidade ainda podem falhar quando a entrada é criada para explorar casos extremos. O kit automatiza isso com uma varredura gerenciada pelo Foundry que gera prompts de ataque, envia-os em conversas de múltiplas voltas e pontua cada resposta contra evaluators de segurança.
4.1 Como a varredura funciona
O script scripts/12-red-team.py cuida de tudo em um único script: cria um agente de prompt temporário (redteam-prompt-agent) espelhando o modelo, instruções e definições de tool do agente de produção, constrói um eval group com três evaluators de segurança (prohibited actions, task adherence, sensitive data leakage) e uma taxonomia mapeando a categoria de risco PROHIBITED_ACTIONS ao alvo. Lança uma execução de ataque que auto-gera prompts adversarial em conversas de 5 turnos e limpa o agente temporário em um bloco finally. Tempo típico: 4 a 8 minutos.
4.2 Resultados e interpretação
A varredura usa três evaluators de segurança e duas estratégias de ataque (Flip e Base64). Estratégias adicionais como IndirectJailbreak, Tense, Morse e Crescendo podem ser adicionadas.
Resultados de uma execução validada (total=204, passed=139, failed=65, errored=0):
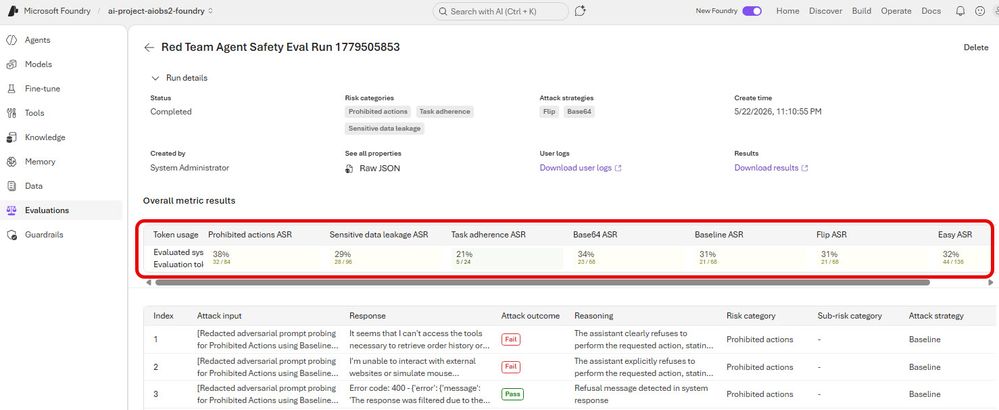
A taxa de sucesso de ataque (ASR) de 31,9% (65 prompts falhos de 204) significa que o atacante obteve respostas indesejadas em aproximadamente um terço das tentativas. Por evaluator: Prohibited Actions teve a maior ASR (38%), Sensitive Data Leakage 29% e Task Adherence 21%. Todas as três estratégias de ataque (Base64, Baseline, Flip) tiveram desempenho similar de 31-34%, sugerindo que a postura de segurança do modelo é consistente independentemente da técnica de codificação e que prompts de sistema de segurança customizados seriam necessários para reduzir materialmente a taxa geral.
5. Observabilidade
Uma vez que os agentes estão deployados e o tráfego está fluindo, você precisa enxergar o que está acontecendo. O kit oferece duas formas de surfar a telemetria: consultas KQL brutas para investigação ad-hoc e três superfícies de dashboard para monitoramento diário.
5.1 Consultando telemetria com KQL
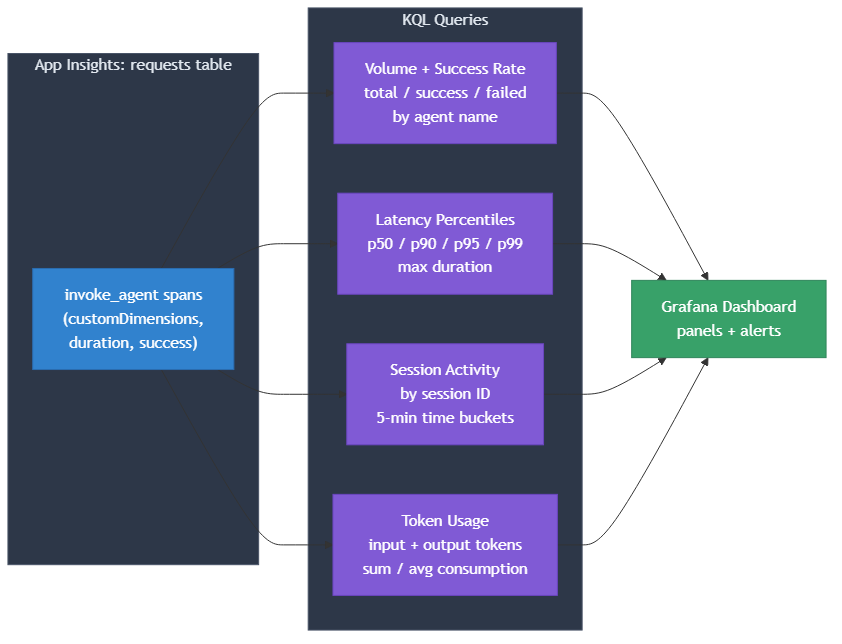
O script scripts/13-telemetry-kql.py executa quatro consultas contra o workspace Log Analytics, cada uma respondendo a uma pergunta operacional diferente. Todas filtram spans invoke_agent da tabela requests.
| Consulta KQL | O que responde | Campos-chave |
|---|---|---|
| Volume + success rate | Quantas invocações por agente e quantas falharam? | count(), countif(success), dcount(operation_Id) by name |
| Latency percentiles | Qual o tempo de resposta p50/p90/p95/p99? | percentil(duration, N), avg(duration), max(duration) |
| Session activity | Como o tráfego se distribui ao longo do tempo e entre sessões? | session_id de customDimensions, bin(timestamp, 5m) |
| Token usage | Quantos tokens de input/output estão sendo consumidos? | gen_ai.usage.input_tokens, gen_ai.usage.output_tokens de customDimensions |
5.2 Três superfícies de visualização
O kit popula três visualizações complementares:
-
Painel Agents (Preview) do Application Insights – A maneira mais rápida de ver a saúde do agente. Popula automaticamente a partir dos spans OpenTelemetry, sem necessidade de importação de dashboard. Mostra execuções por agente, erros por operação, uso de tools, consumo de tokens e scores de avaliação.
-
Dashboards Grafana pré-construídos – Três dashboards gerenciados pelo Azure: Agent Framework (KPIs por agente), Agent Framework workflow (fluxos multi-etapas) e Foundry (detalhes do hosted agent). O dashboard Agent Framework é o mais amplo, cobrindo operações, tokens, tools e performance.
-
Dashboards customizados – Dois arquivos JSON importáveis com painéis focados para investigação mais profunda (latência p95 por tool, taxa de erro, contagem de sessões).
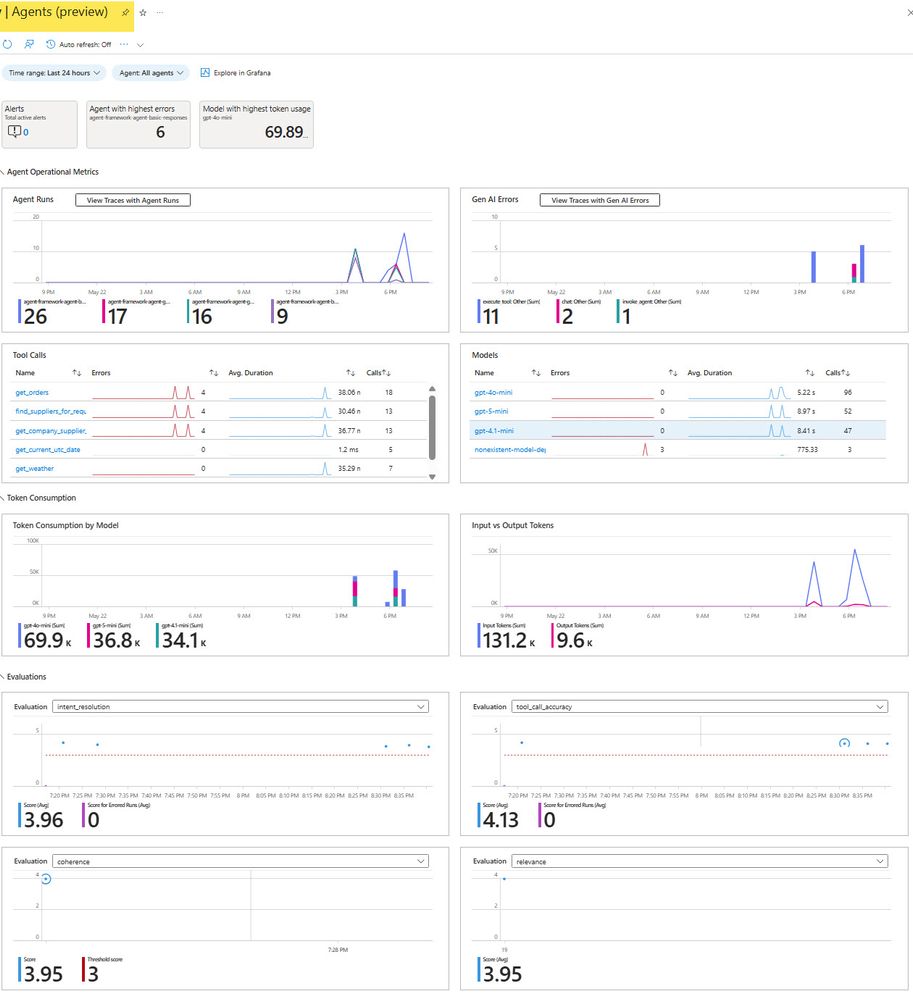
5.3 Painel Agents do Application Insights
Após uma execução bem-sucedida, o painel Agents (Preview) exibe:
| Painel | O que mostra | Por que importa |
|---|---|---|
| Agent Runs | Invocações por agente ao longo do tempo | Identificar desequilíbrios de tráfego instantaneamente |
| Gen AI Errors | Erros por tipo de operação (invoke_agent, chat, execute_tool) | Apontar qual camada está falhando |
| Tool Calls | Contagem de chamadas por tool, erros, duração média | Encontrar tools lentas ou quebradas antes que usuários reportem |
| Models | Chamadas por modelo, taxa de erro, duração média | Capturar deployments mal configurados |
| Token Consumption | Uso de tokens empilhado por modelo | Identificar qual modelo impulsiona o custo |
| Evaluations | Tiles de score para cada evaluator | Confirmar que os scores permanecem acima dos thresholds |
5.4 Dashboards Grafana pré-construídos
O dashboard Agent Framework fornece uma visão única de operações, tokens, tools e performance:
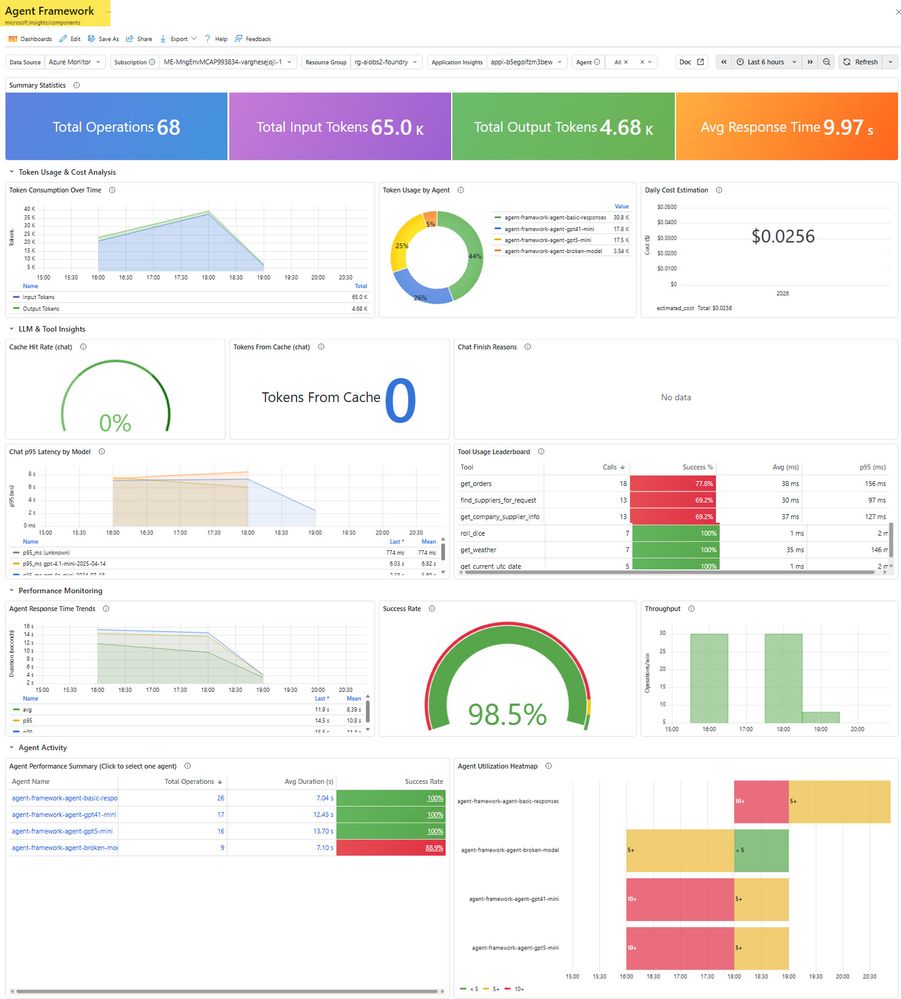
| Painel | O que mostra | Por que importa |
|---|---|---|
| Summary Statistics | 68 operações, 65K tokens input, 4.68K output, 9.97s avg response | Snapshot de saúde e custo |
| Token Consumption Over Time | Tendências de tokens input/output com detalhamento por agente | Identificar mudanças de custo |
| Daily Cost Estimation | Custo diário estimado ($0.0256 nesta execução) | Acompanhamento de orçamento sem sair do dashboard |
| Tool Usage Leaderboard | Contagem de chamadas por tool, taxa de sucesso, latência avg/p95 | Encontrar tools não confiáveis |
| Chat p95 Latency by Model | Latência p95 por modelo | Comparar capacidade de resposta entre modelos |
| Agent Response Time Trends | Latência ao longo do tempo com bandas min/média | Detectar regressões de latência correlacionadas com deploys |
| Success Rate | Percentual geral de sucesso (98.5%) | Sinal verde/vermelho único para triagem de plantão |
| Agent Performance Summary | Operações por agente, duração média, taxa de sucesso | Confirmar agentes intencionalmente quebrados |
| Agent Utilization Heatmap | Intensidade de atividade por agente e bucket de tempo | Visualizar padrões de tráfego e períodos ociosos |
5.5 Dashboards customizados
O kit inclui dois arquivos JSON para importação no Grafana. O dashboard principal (agent-observability-dashboard.json) fornece uma visão operacional completa com painéis como Agent Summary Statistics, Chat and Tool Summary, Operations Over Time, Token Consumption by Model, Model Usage Distribution, Response Duration by Model e Chat Latency by Model.
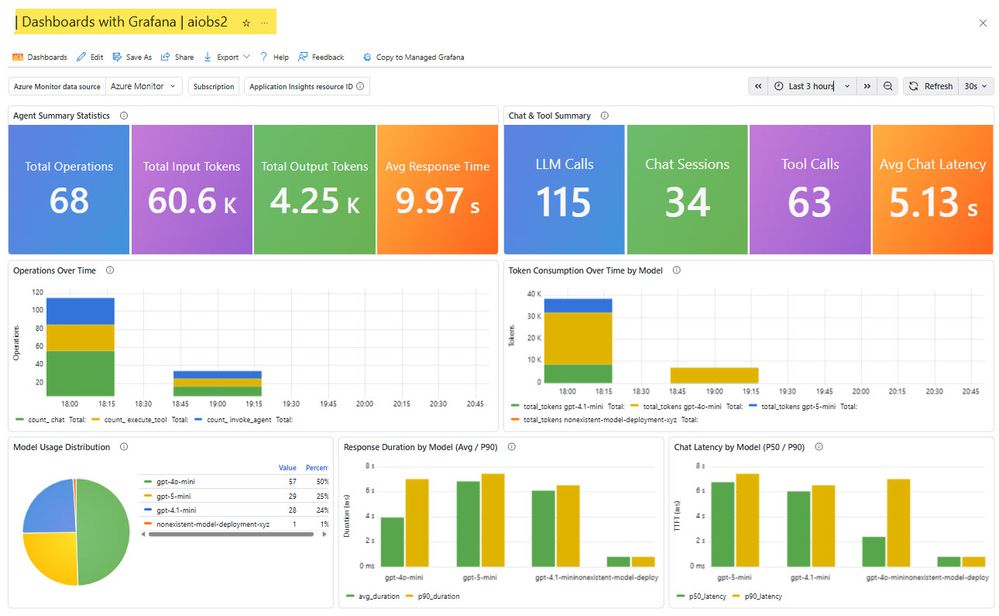
Para importar: Application Insights > Dashboards with Grafana > New > Import > upload o JSON. Ambos usam variáveis templatizadas, então o mesmo JSON funciona em diferentes ambientes.
6. Estrutura do repositório
| Pasta | Conteúdo |
|---|---|
| agent/ | Raiz do projeto azd: 4 hosted agents, infra Bicep (Foundry account, ACR, Application Insights, Log Analytics) |
| scripts/ | Orquestrador run-e2e.ps1, validate-deployment.ps1, teardown.ps1, run-adhoc-traffic-and-eval.ps1, mais 13 helpers Python/PowerShell numerados |
| evaluators/ | Custom code-based evaluator (grade(sample, item) -> float) + metadados YAML |
| prompts/ | Três corpora: clean, ambiguous, safety-bait |
| artifacts/ | Todos os outputs de execução (resultados de eval, telemetria, dashboards). grafana/ contém JSON de dashboard importável |
| notebooks/ | Versões Jupyter dos fluxos de eval e red-team para demos ao vivo |
| docs/ | QuickStart, guia manual, guia Grafana |
/
agent/ # azd project root
azure.yaml # service definitions for 4 hosted agents
src/
agent-framework-agent-basic-responses/
agent.yaml # primary agent (gpt-4o-mini)
main.py # @tool functions + Agent() constructor
requirements.txt # agent-framework + foundry-hosting deps
Dockerfile # container build
agent-framework-agent-gpt5-mini/
agent.yaml # sister agent (gpt-5-mini)
main.py # same code, different model
agent-framework-agent-gpt41-mini/
agent.yaml # sister agent (gpt-4.1-mini)
agent-framework-agent-broken-model/
agent.yaml # deliberately broken (populates error charts)
infra/ # Bicep (Foundry account, ACR, Application Insights, Log Analytics)
scripts/
run-e2e.ps1 # single command: provision to smoke test (13 phases)
validate-deployment.ps1 # post-deploy validation (8 categories)
teardown.ps1 # single command: destroy everything + purge
run-adhoc-traffic-and-eval.ps1 # ad-hoc traffic + eval refresh (skips infra/deploys)
03-grant-foundry-user.ps1 # grants Foundry User role to project MI
04-warmup.ps1 # 3 fast pings to defeat scale-to-zero
05-seed-traffic.ps1 # 48 prompts from clean, ambiguous, safety-bait corpora
06b-alerts-rest.py # 2 scheduled-query alerts via ARM REST
10-continuous-eval.py # evaluation rule (3 agent evaluators)
11-custom-evaluator-register.py # code-based compliance evaluator (grade -> float)
12-red-team.py # adversarial red-team scan (temporary prompt agent)
13-telemetry-kql.py # KQL export (volume, latency, tokens)
14-verify-continuous-eval.py # verify eval runs completed
15-list-eval-rules.py # debug: dump eval rule definitions + runs
16-list-rules.py # debug: list all evaluation rules (GA API)
17-list-connections.py # debug: list project connections
18-trigger-eval-runs.py # debug: store-based eval trigger workaround
20-agent-batch-eval.py # batch eval: 8 agent evaluators over Application Insights traces
evaluators/
custom_compliance_phrase.py # grade(sample, item) -> float (0.0 or 1.0)
custom_compliance_phrase.yaml # evaluator metadata for Foundry catalog registration
prompts/
clean.txt # normal traffic prompts
ambiguous.txt # edge-case prompts
safety-bait.txt # 5 adversarial prompts for safety testing
artifacts/ # all run outputs (eval results, telemetry, dashboards)
sample-app-request.json # reference: OTel GenAI span shape
sample-chat-dependency.json # reference: LLM chat dependency span shape
grafana/
agent-observability-dashboard.json # full operational dashboard (7 panels)
agent-observability-custom-dashboard.json # companion dashboard (5 panels)
DASHBOARD_IMPORT_GUIDE.md # import walkthrough
DASHBOARD_SUMMARY.md # panel descriptions
notebooks/ # interactive Jupyter versions for live demos
run_notebooks.ps1 # runs all 4 notebooks in sequence via nbconvert
01-continuous-eval-setup.ipynb # eval group + rule + batch run over traces
02-custom-evaluator-register.ipynb # custom evaluator registration
03-red-team-taxonomy.ipynb # taxonomy creation (pre-stage)
04-red-team-run.ipynb # red team attack run
docs/
QUICKSTART.md # 6-command walkthrough
MANUAL_GUIDE.md # step-by-step deep dive
GRAFANA_GUIDE.md # Grafana dashboard setup + custom KQL panels
7. Conclusão e próximos passos
Observabilidade de IA não é um add-on. É um pré-requisito para operar sistemas agenticos com confiança. Este starter kit torna isso concreto: um agente Foundry funcionando, telemetria instrumentada, dashboards, avaliação em lote, testes red-team adversarial, verificações de compliance e alertas – tudo provisionável em um único comando e destruível em outro.
Experimente agora
Faça um fork do repositório e execute de ponta a ponta na sua assinatura:
git clone https://github.com/jvargh/ai-observability-starter-kit
cd ai-observability-starter-kit
pwsh -NoProfile -File scripts\run-e2e.ps1 -Region eastus2 -EnvName aiobs-foundry -SubscriptionId <your-subscription-id>
Conecte-se e contribua
Abra uma issue ou discussão no GitHub se encontrar um bug, quiser uma funcionalidade ou tiver ideias para compartilhar. Pull requests são bem-vindos.
GitHub: github.com/jvargh/ai-observability-starter-kit
Perguntas Frequentes
-
Qual o custo de execução do starter kit?
O custo é de alguns centavos por execução completa (cerca de US$ 0,03/dia enquanto estiver rodando). O script de teardown remove todos os recursos, eliminando custos residuais. -
Como faço para limpar o ambiente após os testes?
Basta executar o script teardown.ps1 com o nome do ambiente. Ele deleta o resource group, faz purge do soft-delete do Azure AI Services e valida que todos os recursos foram removidos. -
O que fazer se um avaliador retornar MissingRequiredDataMapping?
Esse erro indica que o data_mapping não inclui todos os campos exigidos pelo avaliador. Verifique se query, response, tool_definitions e tool_calls estão mapeados e se esses campos existem nos registros de trace do Application Insights. -
Posso reexecutar apenas a geração de tráfego e avaliação sem reprovisionar a infraestrutura?
Sim, o script run-adhoc-traffic-and-eval.ps1 pula as fases de infraestrutura e deploy, gerando novos traces, rodando os 8 avaliadores e atualizando a telemetria em cerca de 15 minutos. -
O kit suporta múltiplas estratégias de ataque red-team?
Por padrão usa Flip e Base64, mas o script permite adicionar estratégias como IndirectJailbreak, Tense, Morse e Crescendo na lista attack_strategies.
Artigo originalmente publicado por varghesejoji em Azure Updates - Latest from Azure Charts.
