

TL;DR: Este artigo analisa o estudo da Microsoft que comparou analyzers de idioma Lucene, Microsoft e a opção padrão (None) no Azure AI Search. Conclusão principal: sempre use um language analyzer — o ganho médio de qualidade de busca (NDCG@10) é de +15%, podendo chegar a +120% para idiomas como finlandês e coreano. A diferença entre Lucene e Microsoft é pequena (menos de 2% de variação), e não há penalidade de latência. Para conteúdo limpo (documentos estruturados), Lucene leva leve vantagem; para conteúdo ruidoso (tickets de suporte), Microsoft é superior. Recomenda-se testar com a Analyze API.
O que um language analyzer faz?
Por padrão, o Azure AI Search usa um tokenizer padrão que divide o texto em espaços e pontuação e converte para minúsculas — sem qualquer inteligência linguística. Um language analyzer adiciona processamento linguístico:
- Segmentação — Identifica limites de palavras em idiomas sem espaços (ex.: coreano → tokens separados)
- Lemmatization — Reduz formas flexionadas à base (ex.: fuimos, vamos, yendo → ir)
- Compound decomposition — Quebra palavras compostas (ex.: Krankenhausverwaltungssystem → Kranken + haus + verwaltung + system)
O Azure AI Search oferece quatro opções de analyzer:
| Opção | O que faz | Idiomas |
|---|---|---|
| None (padrão) | Tokenizer Lucene Standard. Apenas divisão por espaços/pontuação e minúsculas. Sem linguística. | N/A |
| Lucene | Analyzers open-source Apache Lucene. Usam stemming e remoção de stopwords. | ~35 |
| Microsoft | Tecnologia NLP proprietária da Microsoft (usada no Office e Bing). Inclui lemmatization, decompounding e entity recognition. | 50+ |
| Custom | Combinação definida pelo usuário de tokenizer, filtros e character filters. | Qualquer |
Tabela 1: Opções de language analyzer no Azure AI Search
Abaixo, como cada opção processa o mesmo texto em diferentes idiomas:
| Idioma | Entrada | None | Lucene | Microsoft |
|---|---|---|---|
| Inglês | "items in conflict and did not sync" | items, in, conflict, and, did, not, sync | item, conflict, did, sync | item, items, conflict, do, did, synch, sync |
| Coreano | "서울에서 맛있는 음식점 추천해주세요" | 서울에서, 맛있는, 음식점, 추천해주세요 | 서울, 울에, 에서, 맛있, 있는, 음식, 식점, 추천, ... | 서울에서, 서울, 맛있는, 음식점, 음식, 추천해주세요, 추천, 주세요 |
| Espanhol | "Los usuarios no pueden iniciar sesión" | los, usuarios, no, pueden, iniciar, sesión | usuari, pueden, iniciar, sesion | usuario, usuarios, no, poder, pueden, iniciar, sesion, sesión |
| Sueco | "Snabbstart fungerar inte från datorn" | snabbstart, fungerar, inte, från, datorn | snabbstart, funger, datorn | snabbstart, snabb, start, fungera, fungerar, inte, från, dator, datorn |
Tabela 2: Tokenização de cada analyzer para o mesmo texto de entrada
Os tokens foram gerados usando a Analyze API do Azure AI Search. Você pode testar com seu próprio texto.
A escolha do analyzer realmente importa?
Das 31 combinações idioma–dataset testadas, o tokenizer padrão (None) nunca venceu. Em todos os casos, um language analyzer entregou resultados superiores.
| Estratégia | Avg NDCG@10 | vs None |
|---|---|---|
| Microsoft | 0.4252 | +15.4% |
| Lucene | 0.4177 | +13.4% |
| None | 0.3684 | baseline |
Tabela 3: NDCG@10 médio em todas as 31 combinações
O ganho varia por idioma. Idiomas morfologicamente complexos (finlandês, coreano, polonês) têm os maiores lifts — acima de +70%. Idiomas CJK também se beneficiam muito por não terem espaços delimitadores.
| Idioma | Dataset | Melhor Analyzer | NDCG@10 (Melhor) | NDCG@10 (None) | Lift |
|---|---|---|---|---|---|
| Finlandês | Support | Microsoft | 0.2752 | 0.1253 | +119.6% |
| Coreano | Support | Lucene | 0.3252 | 0.1520 | +113.9% |
| Polonês | Support | Microsoft | 0.2759 | 0.1611 | +71.3% |
| Espanhol | Support | Lucene | 0.2469 | 0.1596 | +54.7% |
| Coreano | MIRACL | Microsoft | 0.6895 | 0.4624 | +49.1% |
| Japonês | MIML | Lucene | 0.5348 | 0.3806 | +40.5% |
| Chinês | MIML | Microsoft | 0.5668 | 0.4292 | +32.1% |
Tabela 4: Idiomas com maior ganho de qualidade de busca usando language analyzer
Conclusão principal: Sempre use um language analyzer.
Como os clientes usam analyzers hoje?
A Microsoft analisou o uso de analyzers nos índices do Azure AI Search:
| Métrica | Valor |
|---|---|
| Índices usando algum language analyzer | 27.8% |
| Participação Microsoft (entre quem usa) | 64.8% |
| Participação Lucene (entre quem usa) | 31.2% |
| Misto (ambos) | 4.0% |
Tabela 5: Métricas de adoção de language analyzer
Entre os que usam, o comportamento alinha-se com os achados do estudo: francês prefere Lucene, coreano prefere Microsoft, inglês inclina-se para Microsoft (68.4%).
Conclusão: A maioria dos clientes ainda não usa um language analyzer.
Lucene vs Microsoft — o quadro completo
| Analyzer | Vitórias (de 31) | % do NDCG@10 ótimo |
|---|---|---|
| Microsoft | 17 | 96.7% |
| Lucene | 14 | 95.0% |
| None | 0 | 86.8% |
Tabela 6: Vitórias por analyzer em NDCG@10
As diferenças são pequenas: inglês (Microsoft 0.9413 vs Lucene 0.9383 — diferença de 0.0030), chinês (Microsoft 0.5668 vs Lucene 0.5646 — diferença de 0.0022). Não há diferença significativa de qualidade entre os dois.
Cobertura de idiomas
Microsoft suporta 50 idiomas; Lucene, ~35. Para mais de 20 idiomas, Microsoft é a única opção: croata, estoniano, gujarati, hebraico, hindi, islandês, kannada, letão, lituano, malaiala, malaio, marata, punjabi, sérvio, eslovaco, esloveno, tâmil, telugu, ucraniano, urdu, vietnamita.
Efeito do tipo de corpus
Definimos duas categorias:
- Texto limpo: conteúdo bem formatado e editado (artigos acadêmicos, Wikipedia, bases de conhecimento curadas).
- Texto ruidoso: conteúdo gerado por usuário ou operacional (tickets de suporte, consultas curtas, fóruns).
A escolha entre Lucene e Microsoft depende do tipo de conteúdo:
| Dataset | Tipo de Conteúdo | Vitórias Lucene | Vitórias Microsoft | Vitórias None | Média NDCG Lucene | Média NDCG Microsoft |
|---|---|---|---|---|---|---|
| MIML | Limpo, documentos multisetoriais | 4/6 | 2/6 | 0/6 | 0.6845 | 0.6359 |
| MIRACL | Limpo, passagens Wikipedia | 5/7 | 2/7 | 0/7 | 0.6444 | 0.6425 |
| Support | Ruidoso, tickets de suporte | 5/18 | 13/18 | 0/18 | 0.2406 | 0.2705 |
Tabela 7: Desempenho do analyzer por tipo de conteúdo
Em dados limpos, Lucene tem vantagem (+7.6% no MIML). Em dados ruidosos, Microsoft vence decisivamente: 13 de 18 idiomas, com NDCG médio +12.4% superior ao Lucene.
Por dentro — por que os resultados diferem?
Lucene
Analyzers Lucene reduzem palavras a radicais curtos usando algoritmos baseados em regras (Porter, Snowball). Isso aumenta recall — uma busca por attach encontrará attachments, attached ou attaching. É eficaz em textos limpos, mas em textos ruidosos o stemming pode ser agressivo demais, prejudicando a precision.
| Entrada | Token Lucene | Efeito |
|---|---|---|
| settings | set | Matching mais amplo, mas colide com set, setup, setter |
| brightness | bright | Perde a forma nominal específica |
| attachments | attach | Recall bom, mas puxa conteúdo vagamente relacionado |
| Windows (polonês) | winc | Nome próprio truncado por regras de stemming |
Tabela 8: Exemplos de comportamento do stemming Lucene
Microsoft
Analyzers Microsoft preservam o termo original e adicionam variantes normalizadas — por exemplo, settings gera tanto settings quanto setting. Isso dá benefícios de recall similares ao stemming, mas mantém a forma original para matching preciso.
Além disso:
- Preservam nomes próprios: Windows permanece Windows.
- Decompõem compostos: sueco snabbstart → snabb + start.
- Retêm mais stopwords: onde Lucene remove in, not, and, Microsoft mantém mais.
Comparação em texto ruidoso
Considere uma consulta típica de suporte: "how to fix Windows settings not responding after update"
- None (9 tokens): how, to, fix, windows, settings, not, responding, after, update
- Lucene (7 tokens): how, fix, window, set, respond, after, updat — perde to, not, windows; colapsa settings → set, update → updat
- Microsoft (10 tokens): how, fix, window, windows, setting, settings, respond, responding, after, update — mantém originais e adiciona formas normalizadas
Lucene perde not (contexto de negação) e settings vira o genérico set. Microsoft preserva o significado.
Há custo de latência durante a busca?
Analyzers rodam tanto na indexação quanto na consulta, mas o processamento mais pesado ocorre na indexação. Em tempo de consulta, as três opções produzem latências p50 e p95 idênticas. Verificamos isso em vários idiomas sob carga concorrente. Sua escolha de analyzer não afeta a performance da busca.
Recomendações práticas
Árvore de decisão
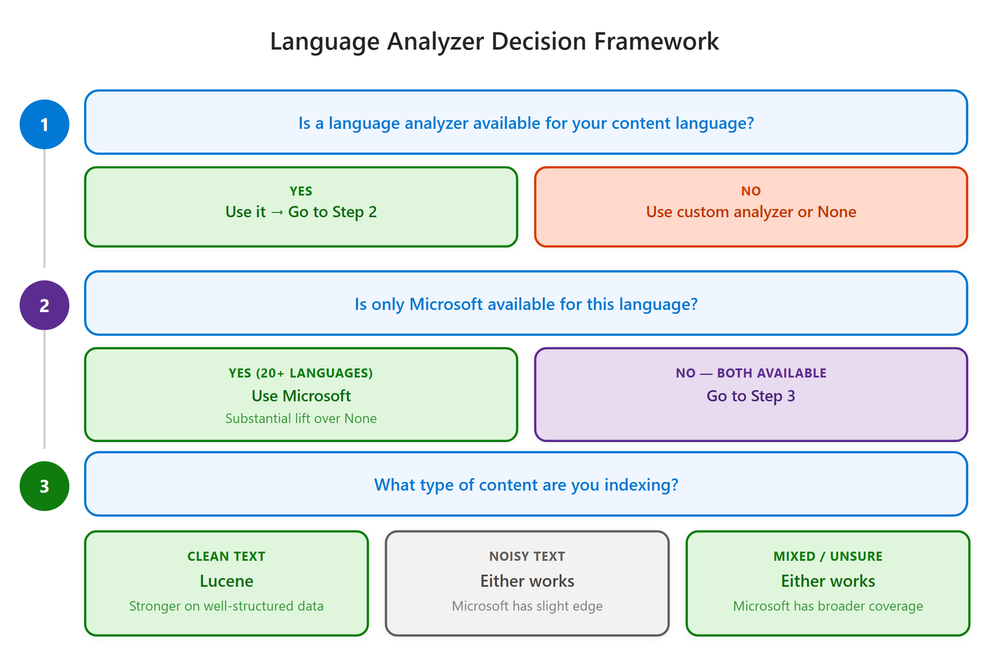
Figura 1: Quadro de decisão para escolha de language analyzer
Overrides específicos por idioma
Para três idiomas, os dados são consistentes em todos os datasets:
| Idioma | Recomendado | Evidência | Margem NDCG |
|---|---|---|---|
| Alemão (de) | Lucene | Vence 2/2 datasets (MIML, Support) | +0.042 |
| Espanhol (es) | Lucene | Vence 3/3 datasets (MIML, MIRACL, Support) | +0.040 |
| Chinês (zh) | Microsoft | Vence 2/2 datasets (MIML, Support) | +0.010 |
Tabela 9: Idiomas com preferência consistente
Para outros idiomas, a melhor escolha depende do tipo de conteúdo — Lucene para dados limpos, Microsoft para dados ruidosos. Nota: Estes resultados são baseados em três datasets de teste. Recomendamos validar seus próprios dados usando a Analyze API.
Principais conclusões
- Sempre configure um language analyzer. O maior ganho vem de usar qualquer analyzer vs None (+15% médio). A diferença Lucene-vs-Microsoft é secundária.
- Ambos Lucene e Microsoft são escolhas seguras. Sempre-Lucene captura 95.0% do NDCG ótimo; Sempre-Microsoft captura 96.7%.
- Não há penalidade de latência. A escolha do analyzer não afeta a performance da consulta.
- Use analyzers por campo em índices multilíngues. Cada campo deve usar seu próprio analyzer para melhores resultados.
- Microsoft é o padrão mais amplo. 50 idiomas, normalização que preserva significado e única opção para mais de 20 idiomas.
Artigo originalmente publicado por Abhishree Shetty, Alec Berntson, Lihang Li em Azure Updates - Latest from Azure Charts.
Perguntas Frequentes
-
Devo usar sempre um language analyzer no Azure AI Search?
Sim. Em todos os 31 testes realizados, o uso de qualquer analyzer (Lucene ou Microsoft) superou a opção padrão (None). O ganho médio foi de +15% no NDCG@10, e para idiomas complexos como finlandês e coreano o ganho ultrapassou +100%. É a configuração mais impactante que você pode fazer. -
Qual a diferença prática entre Lucene e Microsoft analyzers?
Lucene usa stemming (redução a radicais curtos) e é melhor para textos limpos e bem formatados. Microsoft preserva termos originais e adiciona variantes normalizadas, sendo melhor para textos ruidosos como tickets de suporte. A diferença de qualidade média entre os dois é inferior a 2%, então ambos são seguros. -
Há impacto na latência das consultas ao escolher um analyzer?
Não. Os testes da Microsoft mostraram que os tempos de resposta (p50 e p95) são idênticos entre None, Lucene e Microsoft para todos os idiomas testados sob carga concorrente. O processamento mais pesado ocorre na indexação, não na consulta. -
Quais idiomas têm preferência clara por Lucene ou Microsoft?
Alemão e espanhol consistentemente favorecem Lucene (com margem de +0.042 e +0.040 NDCG, respectivamente). Chinês favorece Microsoft (margem +0.010). Para os demais idiomas, a escolha depende do tipo de conteúdo: Lucene para dados limpos, Microsoft para dados ruidosos. Microsoft é a única opção para mais de 20 idiomas. -
Como validar qual analyzer é melhor para meu conteúdo?
Use a Analyze API do Azure AI Search para testar como diferentes analyzers tokenizam seu texto real. O estudo recomenda validar com seus próprios dados, especialmente se seu conteúdo for de um domínio específico ou tiver características linguísticas particulares.
