

TL;DR: Em clusters de IA baseados em RoCEv2, o controle de congestionamento deve seguir a sequência ECN → DCQCN → PFC. Configurar thresholds de PFC muito baixos antes do ECN causa pause storms, oscilações de throughput e picos de latência (ghost latency). A prática recomendada é dar ao ECN uma ampla faixa de marcação (ex: início em 150KB, 100% em 3MB) e usar o PFC apenas como proteção final, com thresholds logo acima da marcação total. Isso garante controle suave (analógico) em vez de on/off, resultando em maior utilização de GPU e latência previsível.
Introdução
Em clusters de treinamento de IA em larga escala, o controle de congestionamento é crítico para manter alta utilização das GPUs e baixos tempos de conclusão de jobs. Dois mecanismos chave em fabrics RoCEv2 (RDMA over Converged Ethernet) são o Explicit Congestion Notification (ECN) e o Priority Flow Control (PFC). Um ajuste excessivamente agressivo dos thresholds de marcação ECN e de pausa PFC – apertá-los demais – frequentemente sai pela culatra. Em vez de reduzir jitter e latência de cauda, pode causar instabilidade: pause storms, colapso de throughput, oscilações e picos de latência “fantasma” (tail latencies extremas).
Como ECN e PFC se complementam no gerenciamento de congestionamento?
Tanto o ECN quanto o PFC são usados para obter redes Ethernet sem perda para tráfego RDMA (RoCEv2), mas operam de formas muito diferentes:
- ECN é um sinal proativo de congestionamento. Quando a fila de um switch ultrapassa um threshold, em vez de descartar pacotes, o switch marca os pacotes com um bit “Congestion Experienced” (CE) no cabeçalho IP. A NIC (ou host) receptora vê a marcação CE e envia um Congestion Notification Packet (CNP) de volta ao remetente, que aciona o algoritmo RoCE/DCQCN para reduzir sua taxa de transmissão. Em essência, o ECN pede que os remetentes desacelerem suavemente. O tráfego não é interrompido – os pacotes continuam fluindo, mas em uma taxa reduzida. Isso preserva o throughput enquanto evita que as filas transbordem. [juniper.net], [cisco.com], [RDMA]
- PFC é um controle de fluxo reativo em nível de link. Se uma fila de egresso do switch atinge um threshold Xoff (indicando que o buffer está quase cheio), o switch envia um frame PAUSE para os dispositivos upstream para aquela classe de prioridade. A NIC upstream interrompe todos os pacotes nessa classe até receber um sinal de resume (Xon). O PFC impede perda de pacotes literalmente parando o tráfego quando os buffers enchem. No entanto, interromper o tráfego tem efeitos colaterais: quando a transmissão é retomada, uma rajada de pacotes pode chegar (pois os remetentes enfileiraram mais dados), causando outro episódio de congestionamento. Em outras palavras, o PFC é um instrumento bruto – garante ausência de perda, mas ao custo de potencial jitter e quedas de throughput se usado em excesso. [juniper.net], [RDMA], [cisco.com]
Em uma rede bem ajustada, ECN e PFC trabalham juntos: ECN é a primeira linha de defesa (estrangulamento gradual das fontes) e PFC é o último recurso (pausar apenas se absolutamente necessário para evitar drops). Esta abordagem complementar visa manter o tráfego fluindo o mais suavemente possível, sem perda de pacotes. Numerosos designs da indústria (de datacenters em nuvem a melhores práticas de fornecedores) enfatizam o uso de ECN + PFC em conjunto para clusters de IA/ML. A chave é configurar seus thresholds corretamente.
Qual a sequência correta de resposta ao congestionamento?
Em redes RoCE para workloads de IA, o congestionamento idealmente deve ser tratado na seguinte sequência:

Em resumo: o switch primeiro tenta sinais de “desacelere” (ECN) e somente depois recorre a sinais de “pare” (PFC). Por que essa ordem? Porque interromper o tráfego (mesmo que brevemente) pode cascata e perturbar muitos fluxos, enquanto a marcação permite que os fluxos continuem, mesmo a uma taxa menor. O backoff suave do ECN mantém as GPUs ocupadas com interrupção mínima; as paradas bruscas do PFC são uma rede de segurança para evitar drops, não um controle primário. Todos os grandes designs de rede para IA endossam esta ordenação – ela gera maior throughput e menor latência sob carga. [juniper.net], [engineering.fyi], [cisco.com], [RDMA]
Qual o erro comum ao ajustar thresholds de forma agressiva?
Na prática, operadores de rede às vezes configuram thresholds incorretamente de modo que o PFC dispara antes que o ECN tenha chance de agir. Isso geralmente ocorre na tentativa de eliminar quase todo o buffer: por exemplo, definindo thresholds ECN muito baixos e thresholds PFC Xoff ainda mais baixos (limites de fila mínimos). A intenção é minimizar o atraso de enfileiramento e sinalizar ou pausar rapidamente qualquer congestionamento. Parece lógico – “apertar” os loops de controle para evitar filas grandes – mas pode sair dramaticamente pela culatra.
O que dá errado quando o PFC dispara cedo demais? Se o threshold de pausa do PFC for muito baixo, o switch enviará um frame PAUSE quase imediatamente quando uma rajada chegar, antes que a fila seja grande o suficiente para a marcação ECN entrar em ação. Efetivamente, o PFC contorna o mecanismo ECN. A NIC nunca recebe sinais ECN para reduzir a taxa; em vez disso, é abruptamente pausada. Quando o timer de pausa expira ou a fila drena, a NIC dispara tráfego novamente (já que nunca desacelerou internamente) – apenas para ser pausada mais uma vez. A rede acaba em um ciclo stop-start.
Abaixo está uma ilustração conceitual da ordenação “errada” versus “correta” de ECN e PFC:
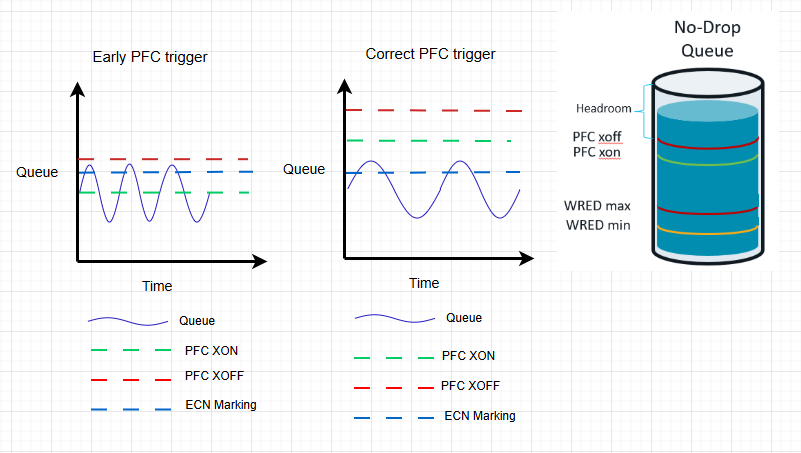
No caso mal configurado (esquerda), cada rajada de tráfego faz a fila atingir momentaneamente o pequeno threshold Xoff e desencadear uma pause storm. Não há “período de graça” para o ECN. O resultado é um padrão de oscilação: a fila está ou quase vazia (quando pausada) ou espigando (quando não pausada). Essa oscilação é ineficiente e brutal para a latência – as GPUs veem suas trocas de mensagens pararem durante cada pausa, depois explodirem, depois pararem novamente. Essas oscilações on/off manifestam-se como altas latências de cauda (algumas iterações demoram muito mais) e throughput subutilizado. Operadores às vezes se referem a esses atrasos periódicos misteriosos como “ghost latency spikes” porque são imprevisíveis e não decorrem de perda de pacotes óbvia.
No caso corretamente ajustado (direita), a faixa de marcação ECN pode abranger várias centenas de KB de fila. Quando uma rajada chega, a fila pode crescer moderadamente (dezenas ou centenas de KB) e o switch começará a marcar pacotes com CE bem antes de o buffer estar criticamente cheio. As fontes RDMA rapidamente obtêm feedback de congestionamento e reduzem sua taxa de envio. Isso mantém a fila abaixo do threshold PFC na maioria dos casos – o tráfego é modulado continuamente pelo ECN/DCQCN (controle analógico), em vez de ser golpeado por pausas on/off (controle digital). Somente se uma rajada pesada e sustentada superar o controle ECN (por exemplo, congestionamento cresce mais rápido que o feedback), o PFC entra em ação para evitar drops.
Em resumo: thresholds agressivos (muito baixos) de PFC combinados com thresholds baixos de ECN podem inverter a hierarquia pretendida. O PFC acaba liderando e o ECN torna-se ineficaz. Este é um dos erros mais comuns em implantações iniciais de RoCE para clusters de IA, e já foi observado causando sérios problemas de performance.
Quais as consequências de configurações excessivamente agressivas?
| Sintoma | Causa Subjacente |
|---|---|
| Pause Storms Frequentes – Frames de pausa PFC repetidos em muitas portas | PFC dispara antes que o loop de feedback ECN possa reagir; rajadas menores causam pausa imediata. O congestionamento se propaga hop-by-hop via pause frames (clássica PFC storm). |
| Oscilação de Taxa – Throughput instável, padrão dente-de-serra | NICs nunca encontram uma taxa de envio estável. DCQCN não converge para um equilíbrio porque o tráfego vai de explosão total a pausa rapidamente. |
| Alta Latência P99 – Picos de latência “fantasma” no tempo de conclusão de jobs | Ondulações de pausa introduzem longas paradas na entrega de pacotes. Uma pausa em um link pode travar fluxos dependentes em outros links (Head-of-line blocking), inflando a latência de cauda imprevisivelmente. |
| Colapso de Throughput em Escala – Throughput médio menor conforme o cluster cresce | Em fabrics grandes, muitos fluxos apresentam comportamento stop-start. Micro-bursts seguidos de pausas significam que os links frequentemente ficam ociosos ou em recuperação, não carregando tráfego constante. |
| Congestionamento Digital (On/Off) – A rede alterna entre buffers vazios e cheios | Em vez de um controle de congestionamento suave, o fabric se comporta de forma binária (verde ou vermelho, sem amarelo). A falta de controle “analógico” impede o compartilhamento fino de banda. |
⚠️ Checklist de Diagnóstico Rápido
- ☐ Os frames de pause PFC estão aumentando enquanto as marcações ECN permanecem baixas? → Aumente o threshold de início do ECN ou diminua o Xoff do PFC – o ECN precisa participar antes que o PFC domine.
- ☐ Padrões de throughput dente-de-serra? → Provavelmente problema de PFC-antes-ECN; verifique a ordenação dos thresholds e confirme que o ECN atinge marcação total antes do Xoff do PFC.
- ☐ Latência P99 alta mas P50 baixa? → Verifique propagação de pause storms entre hops de switch, especialmente onde o congestionamento converge para uplinks compartilhados.
Esses problemas se traduzem diretamente em baixa performance de treinamento de IA: GPUs esperam mais por comunicações, tempos de iteração tornam-se inconsistentes (prejudicando treinamento síncrono) e adicionar mais nós não melhora o throughput como esperado (retornos decrescentes devido à ineficiência da rede). Em casos extremos, podem ocorrer colapso de congestionamento patológico ou deadlocks se as PFC storms se espalharem (embora redes modernas geralmente implementem PFC watchdogs para proteção).
Um relato real: implantações iniciais de grandes clusters de GPU às vezes definiam thresholds de buffer muito pequenos (para minimizar qualquer enfileiramento). O resultado era frequentemente performance decepcionante – logs mostravam incessantes frames de pause PFC e oscilações dramáticas na latência da rede. Somente após afrouxar os thresholds para dar ao ECN mais espaço para respirar é que as redes se estabilizaram e o throughput de treinamento melhorou.
Qual a estratégia recomendada para ajustar ECN e PFC?
O princípio chave é: dê ao ECN uma chance de agir antes que o PFC entre em ação. Na prática, isso significa configurar uma faixa substancial de marcação ECN e um threshold de pausa PFC que seja maior (em termos de profundidade de fila), mas não tão alto a ponto de arriscar perda real de pacotes. Eis uma estratégia típica empregada por operadores experientes de redes de IA:
No Switch (configuração ECN/WRED): Habilite a marcação ECN na classe de tráfego RDMA e defina thresholds de dois níveis:
- ECN Start Threshold: quando a fila de egresso RDMA atinge uma ocupação moderada (por exemplo, algumas centenas de KB por porta), comece a marcação probabilística de pacotes com CE. Muitas implantações escolhem da ordem de 100–300 KB como ponto de início para links de 100 GbE. [cisco.com]
- ECN Full (100% Marking) Threshold: em uma profundidade de fila maior (por exemplo, próxima ao tail do buffer), aumente para marcar todos os pacotes. Por exemplo, pode-se definir 100% de marcação por volta de 2–3 MB de comprimento de fila em um switch 100 Gb. Isso garante que, se a fila continuar crescendo, todos os fluxos sejam sinalizados agressivamente antes de qualquer perda de pacotes.
- (Opcional) Perfil RED (Random Early Detection): ajuste a curva de probabilidade de marcação entre os thresholds de início e full para evitar marcação muito explosiva. O objetivo é um aumento suave na taxa de marcação conforme a fila cresce.
No Switch (configuração de thresholds PFC): Ajuste o threshold Xoff do PFC para a fila lossless para logo acima do threshold full de marcação ECN – essencialmente a margem mínima necessária para capturar quaisquer pacotes em trânsito que já estejam no pipe após o ECN ter sinalizado. Na prática, esse Xoff pode ser bastante pequeno em KB absolutos:
- Por exemplo, em alguns datacenters cloud usando links de 100 Gb, o PFC pause é disparado quando uma fila atinge apenas algumas dezenas de KB além da faixa ECN. Essa pequena margem (dezenas de KB) é suficiente para absorver pacotes já no fio ou nos buffers da NIC enquanto o feedback CNP está voltando aos remetentes. O número exato depende da velocidade do link e do RTT.
- Defina o threshold Xon (resume) apropriadamente abaixo do Xoff (considerando histerese) para que, uma vez emitida a pausa e a fila drene, a retomada ocorra em um nível baixo seguro para evitar thrashing.
Seguir essa estratégia produz uma sequência de congestionamento como: (1) marcar com CE, (2) fontes reduzem taxa, (3) se e somente se a redução não for rápida o suficiente, pausar. Em termos numéricos, para um link de 100 Gbps, uma configuração de exemplo pode ser: [cisco.com], [engineering.fyi]
- Marcação ECN começa em ~150 KB, rampa para 100% em ~3.000 KB.
- PFC Xoff ~3.100 KB (logo acima).
- PFC Xon um pouco menor (por exemplo, ~2.500 KB).
Em um switch diferente com buffers menores, os números absolutos podem variar, mas o princípio de separação permanece: centenas de KB (ou vários microssegundos de buffer) para ECN, e apenas uma pequena margem adicional para PFC.
Crucialmente, operadores aprenderam que é melhor permitir algum buffer (alguns KB são triviais em relação aos típicos 12-16 MB de buffers em uma porta de switch) para obter performance estável. Tentar eliminar o buffer completamente é contraproducente – um pouco de fila não é ruim se for usado para sinalizar congestionamento precocemente via ECN.
Exemplo de Configuração de Thresholds ECN/PFC
# Exemplo Conceitual de Configuração de Thresholds ECN/PFC (adaptar ao seu switch OS)
# Para classe de tráfego RoCEv2 em 100 GbE
# Thresholds de Marcação ECN
ecn-marking-threshold start 150KB
ecn-marking-threshold full 3000KB
ecn-marking-probability linear
# Thresholds PFC (devem ser > ECN full threshold)
pfc-xoff-threshold 3100KB
pfc-xon-threshold 2500KB
# Verificar com: show qos ecn-statistics
Nota: A sintaxe exata varia conforme o sistema operacional de rede (NX-OS, EOS, Junos, SONiC, etc.). O princípio crítico permanece: a marcação ECN deve começar bem antes do threshold Xoff do PFC, e o Xoff deve ficar acima do ponto de marcação total do ECN para que o comportamento de pausa permaneça um mecanismo de proteção de último recurso.
Melhores práticas e conclusões
Em redes complexas de treinamento de GPU, pode parecer natural tentar eliminar todo o enfileiramento para a menor latência possível. No entanto, o trabalho do engenheiro de rede não é eliminar o buffer completamente, mas usá-lo de forma inteligente. Uma pequena quantidade de buffer combinada com ECN permite que a rede flua continuamente em alta utilização, enquanto ainda evita perda de pacotes. O PFC, por outro lado, é o freio de segurança – acione-o apenas como último recurso.
Recapitulando as melhores práticas para controle de congestionamento em clusters de IA baseados em RoCE:
- ECN é o primeiro respondedor; PFC é o último recurso. Configure sempre para que a marcação ECN aconteça antes de qualquer pausa PFC. Isso geralmente significa um threshold maior para ECN e um muito menor para PFC. A maioria das explosões de latência de cauda em grandes clusters de GPU foi rastreada até o uso excessivo de PFC em detrimento do ECN. [juniper.net], [engineering.fyi]
- Não aperte demais a rédea. Configurações agressivas (valores minúsculos de ECN/PFC) podem prejudicar a estabilidade. Você quer um controle de congestionamento suave e analógico, não um padrão digital on/off. Um pouco de enfileiramento não é apenas OK, mas necessário para o loop de controle funcionar.
- Ajuste usando feedback empírico. Comece com valores recomendados (por exemplo, de um fornecedor ou design de referência) e observe: se você ainda vir frames PFC frequentes, pode ser necessário aumentar a agressividade da marcação ECN (ou diminuir um pouco o threshold inicial). Se não vir PFC algum, mas alta ocupação de fila no switch, pode ser necessário diminuir ligeiramente os thresholds ECN ou considerar se o PFC deve disparar um pouco antes. O equilíbrio perfeito pode depender dos padrões de workload (rajadas, tamanhos de mensagem), portanto, o ajuste fino em um ambiente de teste com tráfego representativo é prudente.
Em conclusão, evitar as desvantagens do ajuste agressivo de ECN/PFC resume-se a respeitar os papéis naturais desses mecanismos. Use o ECN para lidar com congestionamento “moderado” e manter o tráfego fluindo, e reserve o PFC apenas para os momentos de “oh não”. Essa abordagem hierárquica produz throughput muito melhor, latência mais baixa e performance mais previsível para workloads de IA distribuídos. Ao configurar uma faixa generosa de marcação ECN e uma margem mínima necessária para PFC, você pode eliminar em grande parte os blowups de latência de cauda e oscilações que afligem fabrics RoCE mal ajustados. O padrão vencedor que emerge na indústria é exatamente esse: ECN como controle proativo de congestionamento, PFC como plano de backup. Seguir esse padrão ajudará a garantir que seus clusters de treinamento de IA rodem em escala com rede suave e de alta performance. [cisco.com], [cisco.com]
Próximos passos: Aplicando estas práticas
Acertar o design de thresholds não é um exercício único – requer validação em laboratório, telemetria de produção e reajuste periódico à medida que velocidades de link, arquiteturas de buffer e padrões de workload evoluem.
🔧 Mãos à obra: Configuração prática
Mapeie o modelo conceitual de thresholds deste artigo para o sistema operacional do seu switch usando guias de implementação dos fornecedores:
- Cisco Nexus QoS Configuration Guide for RoCEv2 – Configuração passo a passo de thresholds para plataformas NX-OS
- Juniper AI Data Center Deployment Guide – Exemplos completos de configuração ECN/PFC para fabrics baseadas em Junos
Essas referências ajudarão a traduzir a intenção de enfileiramento em comandos, unidades e etapas de validação específicos da plataforma.
📊 Valide sua configuração
Após a implantação, verifique se seu fabric se comporta como pretendido:
- Use
show interface priority-flow-control(Cisco) ou o comando equivalente no seu switch OS para monitorar contagens de frames PFC - Acompanhe taxas de marcação ECN via telemetria do switch ou dashboards de estatísticas de fila
- Sinal chave: Se o PFC dispara com frequência, mas as marcações ECN estão baixas, seus thresholds precisam de ajuste – o ECN não está tendo chance de agir antes do PFC assumir.
💬 Participe da discussão
- Compartilhe suas experiências de ajuste nos comentários abaixo
- Tem um desafio de topologia específico? Descreva-o e a comunidade pode ajudar a solucionar
Artigo originalmente publicado em Azure Updates - Latest from Azure Charts.
Perguntas Frequentes
- Por que configurar thresholds muito baixos de PFC pode piorar a performance?
- Porque o PFC dispara antes que o ECN tenha tempo de sinalizar a redução de taxa, causando pause storms e um padrão on/off. O DCQCN nunca converge para uma taxa estável, resultando em oscilações de throughput, picos de latência (ghost latency) e menor utilização da GPU.
- Qual a sequência correta de resposta ao congestionamento em redes RoCE?
- A sequência ideal é: (1) ECN marca pacotes quando a fila atinge um threshold moderado, (2) o receptor envia CNP e o algoritmo DCQCN reduz a taxa de envio dos remetentes, (3) apenas se o controle ECN não for suficiente, o PFC dispara como último recurso para evitar perda de pacotes.
- Como diagnosticar se o PFC está liderando em vez do ECN?
- Sinais típicos: frames de pause do PFC aumentam enquanto as marcações ECN permanecem baixas, throughput apresenta padrão dente-de-serra, e a latência P99 é alta enquanto a P50 é baixa. Use comandos como 'show interface priority-flow-control' para monitorar contagens de PFC.
- Quais valores de exemplo para thresholds ECN e PFC em links de 100 Gbps?
- Referência de projetos validados: ECN start ~150 KB, ECN full (100% marking) ~3.000 KB, PFC Xoff ~3.100 KB (logo acima do full), PFC Xon ~2.500 KB. Os valores absolutos variam conforme o switch, mas o princípio é ter uma faixa ampla para ECN e uma margem mínima para PFC.
- ECN e PFC são mutuamente exclusivos ou devem trabalhar juntos?
- Devem trabalhar em conjunto, com papéis complementares. ECN é o controle proativo que mantém o tráfego fluindo suavemente; PFC é o reativo de último recurso para evitar drops. A má configuração ocorre quando os thresholds invertem essa hierarquia, fazendo o PFC atuar antes do ECN.
