

Os workflows baseados em agentes já deixaram de ser uma promessa para se tornarem a espinha dorsal de muitas automações operacionais. Contudo, ao escalar essas soluções para executar lógicas de negócio complexas — que exigem múltiplas decisões concatenadas —, equipes de engenharia estão enfrentando um obstáculo crítico: o erro composto.
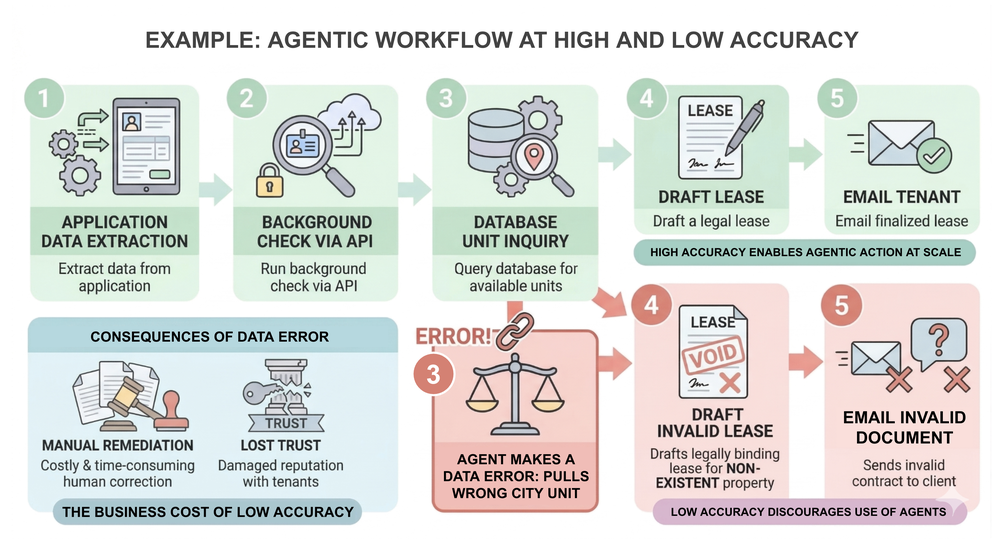
Para entender o risco, precisamos analisar a métrica de sucesso. Em um fluxo de IA de passo único, uma precisão de 90% pode parecer aceitável. No entanto, em um workflow onde o agente executa uma sequência de chamadas interdependentes, os erros se acumulam exponencialmente. Se um processo de cinco etapas, cada uma com 90% de taxa de acerto, for executado, a probabilidade de sucesso real cai para 59%. Com agentes de 80% de precisão, chegamos a um cenário de 33%, o que é operacionalmente inviável e financeiramente perigoso.
Em ambientes corporativos, especialmente em setores regulados onde a conformidade e a segurança são inegociáveis, a busca por uma precisão próxima a 100% não é um luxo, mas uma necessidade de sobrevivência. Além da precisão, a explainability torna-se mandatória: o human-in-the-loop deve ser capaz de auditar exatamente por que o agente tomou determinada decisão. Quando um agente falha ao consultar uma base de dados em uma etapa crítica — como a emissão de um contrato de locação — o custo do retrabalho e o dano à imagem da empresa são consequências diretas da falta de controle sobre a infraestrutura de dados.
Ferramentas para Precisão e Explainability
Para mitigar esses riscos, a abordagem tem se deslocado para o uso de ferramentas especializadas, como o QueryData. O objetivo é claro: criar uma ponte técnica entre a linguagem natural e a query SQL, garantindo que o modelo não apenas "entenda", mas consulte sua base de dados com exatidão.
O Ingrediente Chave: Contexto de Negócio Abrangente
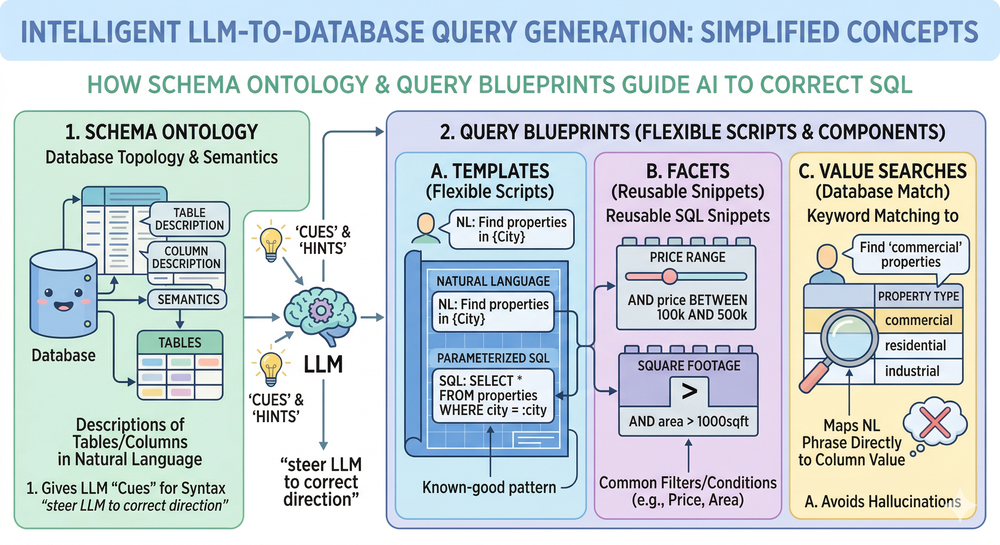
Um LLM domina múltiplos dialetos SQL, mas desconhece suas regras de negócio e a estrutura do seu ambiente. A performance do agente depende da engenharia de contexto, estruturada em três pilares: Schema Ontology, Query Blueprints e Value Searches.
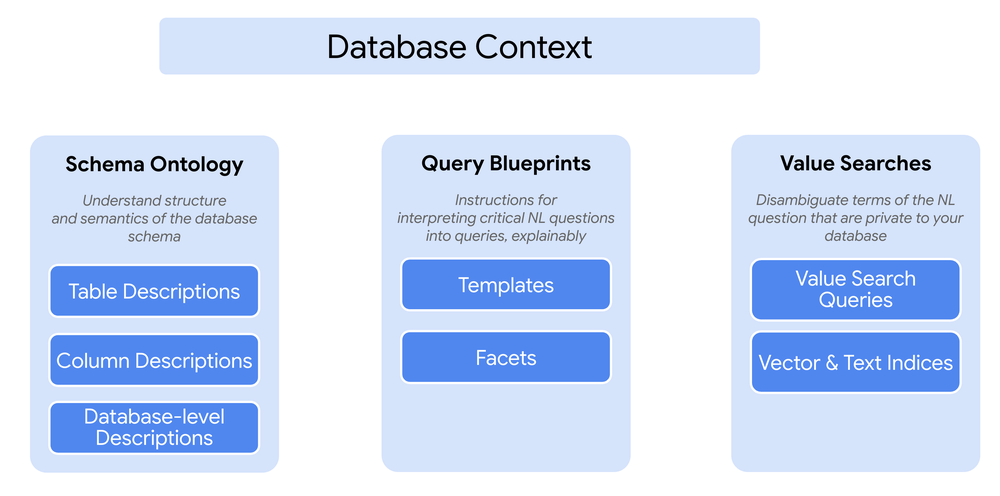
1. Schema Ontology
Consiste em fornecer descrições em linguagem natural para tabelas e colunas. Isso funciona como um conjunto de "dicas" semânticas que orientam o LLM a mapear corretamente os dados, indo além de simples nomes de campos técnicos.
2. Query Blueprints
Aqui reside o controle fino sobre o SQL gerado. Em vez de deixar a interpretação de conceitos vagos (ex: "casas próximas a boas escolas") a cargo apenas do modelo, o desenvolvedor provê templates: um par que associa uma intenção a uma query parametrizada. Isso permite que você embarque regras de negócio, como funções de ranking customizadas e limiares (cutoffs) de performance, dentro do fluxo do agente.
As facets permitem expandir esse conceito, combinando a precisão dos templates com a flexibilidade necessária para queries complexas de filtragem (preço, metragem, localização).
3. Value Searches
Resolve o problema de ambiguidades latentes nos dados, como erros de digitação (ex: "Westwod" vs "Westwood") ou a sobreposição de entidades (uma cidade e uma corretora com o mesmo nome). O uso de capacidades de vector+text search integradas às suas bases de dados permite que o agente disambigue termos de forma muito mais inteligente.
O Futuro: Precisão como Base Operacional
A engenharia de contexto é o caminho para transformar agentes de "experimentos" em sistemas estáveis. Para times de engenharia, o próximo passo é estruturar seus Context Sets em bancos de dados nativos na nuvem como AlloyDB, Cloud SQL ou Spanner, garantindo que a escalabilidade da nuvem seja acompanhada pela integridade do dado.
Artigo originalmente publicado por Yannis PapakonstantinouDistinguished Engineer em Cloud Blog.
