

A maturidade do machine learning em uma organização não se mede pelo modelo mais complexo, mas pela resiliência e previsibilidade da infraestrutura que o sustenta. O cenário comum onde modelos são treinados em notebooks e salvos manualmente em pastas compartilhadas é a receita para o débito técnico: falta de versionamento, ausência de reprodutibilidade e dependência de pessoas específicas para manutenção. Quando o cientista de dados que criou a rotina sai de férias, o risco operacional se materializa.
Um pipeline de MLOps bem arquitetado elimina esse atrito. Ele torna o treinamento repetível, garante o versionamento rigoroso de artefatos e automatiza o deploy, permitindo que a transição de uma alteração no código para um endpoint em produção seja disparada por um simples merge no main.
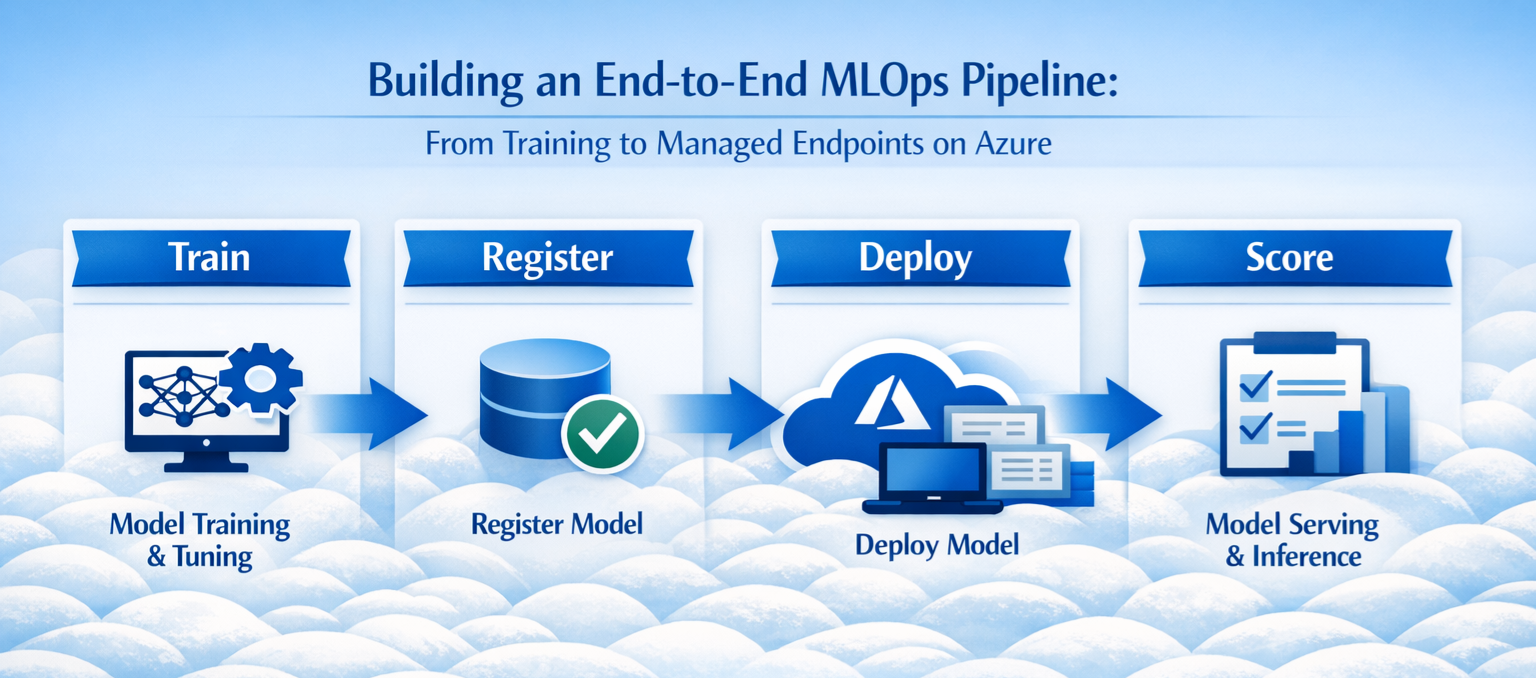
Este artigo detalha um padrão de referência (neste caso, focado em cenários utilizando scikit-learn) que abrange o ciclo de vida completo:
- Train: Execução do treinamento utilizando dados no Azure Blob Storage.
- Serialize: Empacotamento do modelo como um pickle bundle autocontido.
- Register: Registro em um Azure ML Registry para descoberta entre times.
- Deploy: Implementação em um Azure ML Managed Online Endpoint para inferences em tempo real.
Quando adotar este padrão
Este modelo é ideal se:
- Seus dados estão estruturados no Azure Blob Storage (ex: Parquet ou CSV).
- Você utiliza frameworks Python como
scikit-learn. - Você precisa de artefatos de modelo versionados centralmente.
- O objetivo é um caminho automatizado para scoring em produção.
- Você busca eliminar o treinamento baseado em notebooks sem controle de versão.
Atenção: Se o seu caso requer treinamento distribuído ou GPU massiva para inferência, valide as capacidades dos Azure ML Pipelines ou ajustes específicos de configuração para Managed Endpoints.
Visão Geral da Arquitetura
A esteira segue quatro estágios fundamentais:
- DevOps Stage: Gate de controle que registra o
BuildNumbere valida a execução da pipeline. - Train Stage: Instalação de dependências, execução do script de treino e publicação do pickle bundle como um pipeline artifact.
- Register Stage: Download do artefato e registro no Azure ML Registry com versionamento automático.
- Deploy Stage: Provisionamento ou atualização do Managed Online Endpoint.
O Train Stage é, na verdade, o coração de toda a operação. Ele deve ser um CLI Python standalone, testável de ponta a ponta localmente antes de qualquer integração com o Azure DevOps. Ele deve carregar dados (usando bibliotecas como adlfs ou pyarrow), validar o schema, realizar o feature engineering e, crucialmente, persistir o pré-processamento (ex: StandardScaler) juntamente ao modelo no mesmo artifact.
Otimização e Segurança de Artefatos
O conteúdo do seu arquivo pickle deve ser um contrato de scoring completo. Além do estimator, inclua o scaler, o feature_order (para evitar bugs de reordenação silenciosa), metadados de treinamento (trained_at) e versões das bibliotecas. Isso garante que qualquer consumidor do modelo consiga utilizá-lo sem conhecer os detalhes internos do treinamento.
Quanto ao formato de serialização:
pickle: Ótimo para bundles completos, mas requer cautela. Nota de segurança: Nunca carregue arquivos pickle de fontes não confiáveis; a desserialização pode executar código arbitrário. Em um pipeline controlado, com acesso restrito, isso é seguro.joblib: Preferível para modelos com grandes arrays NumPy.ONNX: Ideal para interoperabilidade cross-framework.
Pipeline YAML (Estrutura de Exemplo)
Abaixo, a estrutura essencial para orquestrar o processo:
trigger:
branches:
include:
- main
stages:
- stage: Train
displayName: 'Treinar e Publicar Artifact'
jobs:
- job: TrainModel
steps: # ... steps para python -m pip e execução do script ...
- task: PublishPipelineArtifact@1
inputs:
artifactName: 'model-pkl'
- stage: Register
# ... task az ml model create ...
- stage: Deploy
# ... task az ml online-deployment create ...
Pontos de Atenção para Engenharia
- Gerenciamento de Identidade: Substitua o uso de
AZURE_STORAGE_ACCOUNT_KEYpor User Managed Identity (UMI). Isso elimina o risco de exposição de chaves e a complexidade de rotacioná-las. - Separação de Etapas: Manter
TraineRegisterem estágios distintos permite que você registre novas versões sem precisar re-treinar o modelo se algo falhar na etapa de registro. - Ambientes de Agente: Se estiver utilizando self-hosted agents Windows, certifique-se de ajustar a sintaxe de comandos PowerShell. Bash não é o padrão aqui.
- Pinning de Versões: Nunca deixe de fixar as versões no
requirements.txt. Uma atualização menor noscikit-learnpode alterar o comportamento do modelo silenciosamente durante opredict().
O valor do MLOps não reside na complexidade da nuvem, mas na eliminação de passos manuais. Ao automatizar esse fluxo, seu time de engenharia ganha a confiança necessária para evoluir os modelos com métricas claras, rollbacks rápidos via blue-green deployments e uma infraestrutura auditável.
Artigo originalmente publicado em Azure Updates - Latest from Azure Charts.
