

Como a Google evoluiu suas redes de data center e global para a era da IA
TL;DR: Este artigo analisa como a Google reimaginou suas redes de data center e global para suportar cargas de trabalho de IA. A conclusão principal é que a rede deixou de ser um mero duto para se tornar um componente crítico de desempenho, escalabilidade e resiliência. Para empresas brasileiras que buscam escalar IA, entender essas inovações ajuda a alinhar estratégias de cloud e evitar gargalos de infraestrutura.
Nos últimos 25 anos construindo a rede global da Google, navegamos por grandes eras arquitetônicas — da Internet, ao streaming e à cloud. Hoje, estamos firmemente no meio de uma quarta: a era da IA. As aplicações nesta era são fundamentalmente diferentes das aplicações de consumo e enterprise das eras anteriores e impõem um conjunto de requisitos novos e exigentes — sobre recursos de computação, obviamente, mas também sobre a rede.
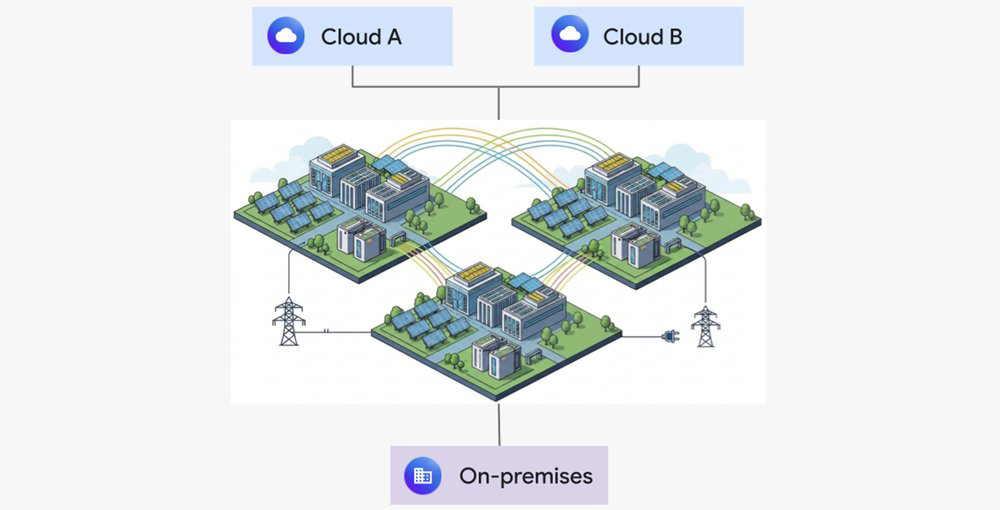
Considere o desafio físico fundamental: é muito mais difícil mover elétrons (energia elétrica) do que mover fótons (dados sobre fibra). Como a demanda por computação de IA frequentemente supera a capacidade de espaço e energia de instalações individuais, posicionamos estrategicamente data centers próximos a fontes de energia sustentáveis, ou em locais com caminhos para adicionar fontes de energia limpa à rede local. Então, utilizando a rede para distribuir workloads de IA entre os campuses, criamos um recurso de hipercomputação massivo e pooling que supera as limitações de energia de qualquer site único.
Para entregar isso, criamos uma stack de tecnologia de IA verticalmente integrada e end-to-end que compreende desde chips até sistemas, plataformas e ecossistemas de aplicações e agentes. Essa stack inclui um portfólio de agentes e aplicações pré-construídos; nossa Gemini Enterprise Agent Platform para você construir, escalar, governar e otimizar suas aplicações habilitadas para IA; modelos de IA de classe mundial; e nossa plataforma de dados unificada. Tudo isso é ancorado pelo AI Hypercomputer, uma infraestrutura unificada que combina hardware construído para propósito específico e software aberto, e que vem com opções flexíveis de consumo. Nossa rede, forjada por décadas de inovação, é o tecido essencial do AI Hypercomputer.
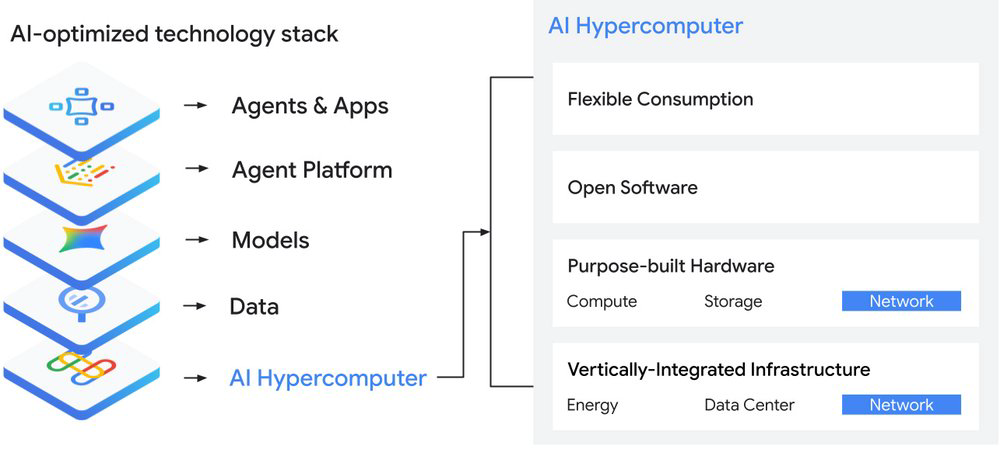
A rede que suporta essa stack precisa atender às rigorosas necessidades de bandwidth, escala e performance dos workloads de IA. Isso se aplica não apenas dentro do campus, onde a rede deve escalar para cima e para fora, mas também através da rede de longa distância (WAN), juntamente com interconexões de alta largura de banda, para trazer dados de treinamento de IA da fonte para os recursos de computação.
Para enfrentar esses desafios, reimaginamos três pilares principais de nossa infraestrutura de rede: a fabric dentro do AI Hypercomputer, a fabric através do AI Hypercomputer e nossa rede global. Vamos analisar cada um deles.
Por que a fabric dentro do AI Hypercomputer é crítica?
A escala massiva dos modelos de IA atuais, alimentada pelo crescimento explosivo dos parâmetros dos modelos fundacionais, torna o treinamento de IA muito intensivo em computação e rede.
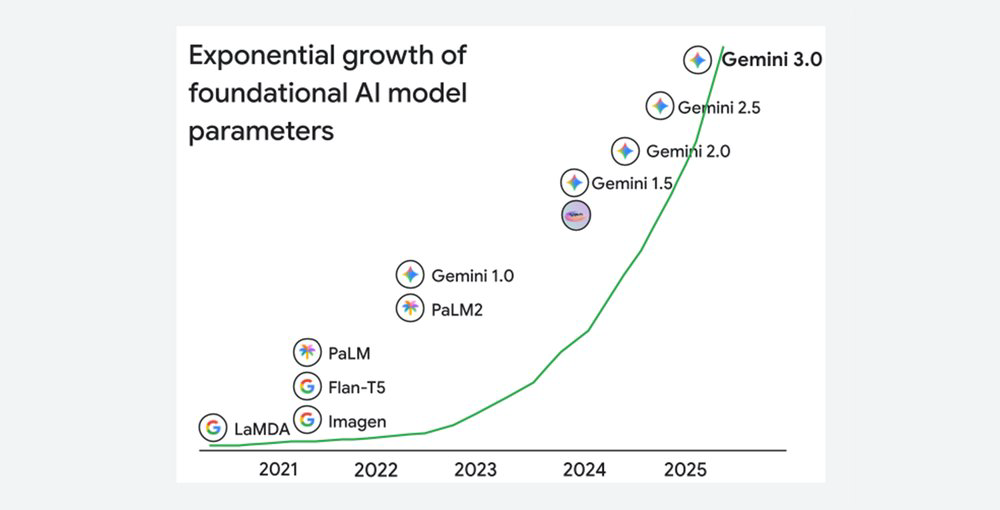
Isso exige um aumento exponencial na largura de banda da rede, com limites rigorosos de delay (ex: tail latency) para acomodar os padrões peculiares de tráfego dos workloads de IA, que são caracterizados pela sensibilidade à variação de performance e rajadas sincronizadas (intensos spikes de tráfego em nível de milissegundos). Além disso, como jobs de treinamento em larga escala são particularmente vulneráveis a falhas e stragglers de performance, manter alta confiabilidade e performance previsível é absolutamente essencial.
Para lidar com a escala, baixa latência e alta previsibilidade que os workloads modernos de IA exigem — bem como a proteção contra rajadas extremas — adotamos uma filosofia de "campus como um computador", desacoplando nossa rede em três domínios distintos:
- um domínio scale-up para conectividade intra-pod
- uma fabric scale-out dedicada para tráfego leste-oeste
- a rede Jupiter frontend para acesso de tráfego norte-sul a computação e armazenamento
Essa arquitetura desacoplada oferece três vantagens estratégicas: permite que os domínios evoluam independentemente para uma inovação mais rápida; fornece uma rede scale-out não-bloqueante com enorme largura de banda de treinamento; e ajuda a garantir que a rede possa ser co-projetada em sintonia com os novos aceleradores ML.
Recentemente, apresentamos o Virgo Network, nossa fabric scale-out de data center projetada especificamente para IA moderna. O Virgo utiliza switches de alto radix e uma topologia não-bloqueante plana de duas camadas para fornecer largura de banda de bissecção massiva, enquanto minimiza a latência ao reduzir os tiers de rede. Seu design multi-planar, com domínios de controle independentes para cada plano, fornece resiliência em nível de hardware e isolamento de falhas. Além disso, o Virgo pode se expandir por vários data centers, removendo as limitações físicas dos prédios e permitindo a escalabilidade flexível da computação de IA.
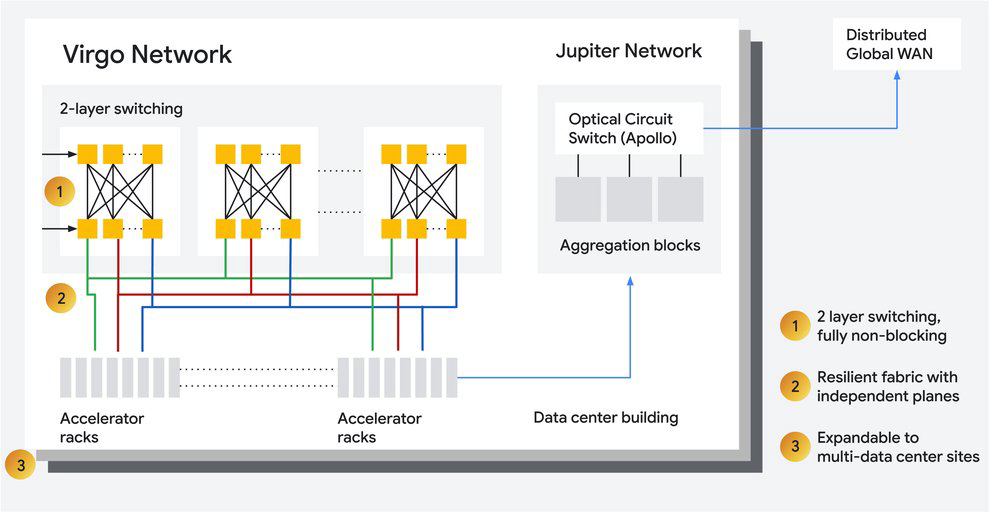
A eficácia do co-design entre nossa rede e acelerador é perfeitamente ilustrada pelos recém-lançados TPUs de oitava geração. Dentro dessa arquitetura, o Virgo Network pode conectar 134.000 chips TPU 8t com até 47 petabits/sec de largura de banda de bissecção não-bloqueante em uma única fabric. O Virgo Network entrega até 4x a largura de banda por acelerador TPU 8t em relação à geração anterior, e 40% menos latência de fabric descarregada para TPU 8t em comparação com a rede anterior para TPUs. Nessa configuração, o Virgo gerencia o tráfego bruto do acelerador, enquanto o Jupiter fornece acesso confiável e rápido à WAN global e ao armazenamento. Quando integrado com Pathways e JAX, esse motor de rede do AI Hypercomputer facilita a escalabilidade quase linear para até um milhão de chips TPU 8t em um único cluster lógico.
Confiabilidade autônoma: protegendo o goodput do workload
Construir uma fabric megascale resiliente representa apenas parte do desafio. Em um cluster de centenas de milhares de chips, falhas de hardware são uma certeza estatística. Uma única instância travada pode interromper um job de treinamento síncrono inteiro, desperdiçando ciclos de computação valiosos. Como tal, a localização eficiente de falhas é crítica.
Projetamos o Virgo Network com capacidades de confiabilidade autônoma para maximizar a eficiência do workload em escala, também conhecida como goodput. Expandindo nossa detecção de stragglers existente, o Virgo agora também possui detecção automatizada de hangs. No momento em que um fail-stop event ocorre, nossos agentes especializados localizam a falha, isolam a instância defeituosa e permitem que você restaure o job de treinamento a partir de um checkpoint — colocando sua linha do tempo de treinamento de volta nos trilhos, com o mínimo de intervenção manual. Saiba mais assistindo a esta demonstração:
![Demo] Autonomous ML Reliability - Data Center Network](https://youtube.com/watch?v=0yKGILWlngY)
Para complementar essas capacidades, também usamos telemetria de alta resolução (sub-milissegundo) para identificar micro-bursts de rede elusivos que geralmente são perdidos pelos intervalos de monitoramento convencionais de 30 segundos. Esses avanços em telemetria de alta resolução permitem operações de rede mais eficientes, melhor provisionamento e menor tempo médio para recuperação.
![Demo] High Resolution Network Telemetry: Data Center Network](https://youtube.com/watch?v=jah2yf2rARg)
Como funciona a fabric através do AI Hypercomputer?
O crescimento exponencial dos workloads modernos de IA exige que escalemos e distribuamos workloads de IA através de múltiplos campuses sobre uma WAN. Ao mesmo tempo, as redes tradicionais não foram construídas para a alta largura de banda e rajadas extremas do tráfego de IA, e frequentemente falham em detectar microbursts que podem levar a uma degradação severa de performance. Desenvolvemos um conjunto de inovações para otimizar a performance da WAN para implantações de IA cross-site, incluindo:
- Uma rede global multi-shard que permite escalabilidade horizontal. Nossa rede global sustentou um crescimento de tráfego WAN de 10 vezes entre 2020 e 2025.
- Ajuste da fabric para atributos essenciais de disponibilidade, latência e qualidade de serviço (QoS). O gerenciamento de microbursts em tempo real ajuda a garantir alocação justa de largura de banda e isolamento de infraestrutura em nossa infraestrutura multi-tenant.
- Isolamento multi-shard para garantir que cada shard de rede opere com seus próprios planos de controle, dados e gerenciamento.
Combinado com isolamento regional e Protective Reroute, essa arquitetura minimiza o impacto de falhas e encurta as interrupções visíveis ao usuário — entregando a confiabilidade além dos "nove noves" essencial para workloads de IA.
Fornecer interconectividade de alta velocidade, flexível e econômica também é uma prioridade. O treinamento de IA depende de vastos datasets que muitas vezes estão localizados on-premises ou em várias clouds. Dado o alto custo da computação de IA, minimizar o tempo ocioso é essencial; por exemplo, atualizar de um link de 100 Gbps para uma conexão de 3.2 Tbps reduz o tempo para transferir um petabyte de dados de 22,2 horas para apenas 0,7 horas — uma redução de 97% no tempo ocioso da computação de IA esperando por dados. Nosso AI-native Cloud Interconnect é construído para as necessidades de alta largura de banda e baixa latência dos workloads de IA, apresentando um caminho de dados otimizado com links de 400 Gbps que escalam em incrementos de 3.2 Tbps para atingir capacidade de petabit por segundo. Ele também oferece diferenciação de tráfego e opções de conexão flexíveis, incluindo peering de fibra direta e instalações de colocation. O AI-native Cloud Interconnect suporta transferência de dados em escala de petabit com conectividade privada e confiável necessária para seu treinamento e serving de IA cross-cloud.
Como a rede global da Google se preparou para a era da inferência de IA?
Aplicações que servem inferência de IA para uma população global de usuários ou que suportam uma empresa agentic são muito mais exigentes do que aplicações web convencionais. A necessidade de uso oportunista de computação de IA cara disponível em locais distantes, dependências de serviço distribuídas e a natureza de rajada do tráfego exigem uma rede de alta largura de banda com presença global, bem como peering profundo com provedores de SaaS, ISPs e hyperscalers. Para manter a capacidade de resposta e disponibilidade "always-on", as aplicações precisam de baixa latência e uma rede altamente resiliente.
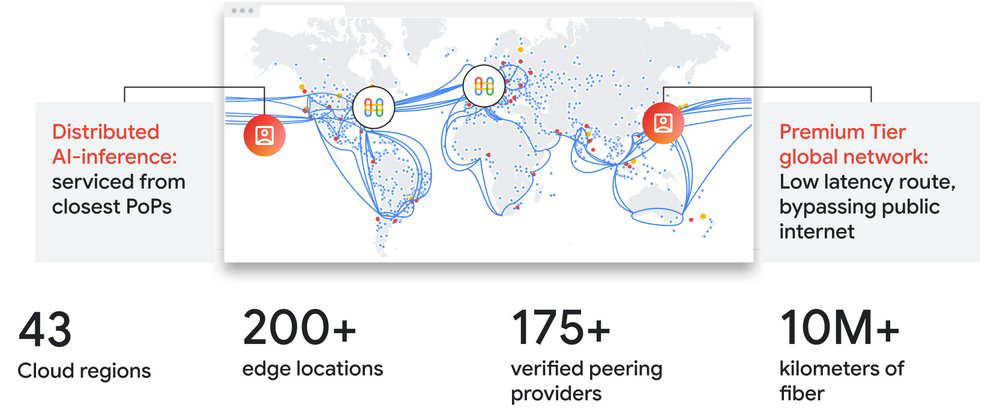
Com sua conectividade, escala e resiliência, a rede global da Google está bem equipada para lidar com as demandas da era da inferência de IA. Nossa rede abrange mais de 10 milhões de quilômetros de fibra terrestre e submarina, conecta nossas 43 regiões cloud e apresenta mais de 200 edge locations, fornecendo a presença essencial para servir inferência de IA. Nossa rede Premium Tier oferece a baixa latência e confiabilidade necessárias para uma experiência de usuário global consistente e de alta qualidade. Ao otimizar os pontos de entrada e saída de tráfego, a rede aumenta significativamente a performance das aplicações, com a resiliência no centro dessa infraestrutura "always-on".
Construindo o futuro, juntos
Como cliente do Google Cloud, essas inovações de rede são incorporadas diretamente ao seu ambiente. A rede da Google oferece a escala massiva, capacidade, confiabilidade e performance essenciais para seus workloads de IA.
A era da IA exige mais do que apenas computação bruta; ela necessita de uma fabric de rede robusta para escalar. Nossa stack de tecnologia de IA verticalmente integrada — do silício aos ecossistemas de software — é alimentada pelo AI Hypercomputer para acelerar sua transformação e tornar a IA útil para todos. Seja através de nossa fabric megascale, de nossa rede global resiliente para inferência ou do AI-native Cloud Interconnect, garantimos que sua jornada de IA seja eficiente e confiável.
Perguntas Frequentes
-
O que é o Virgo Network e como ele beneficia cargas de trabalho de IA?
O Virgo Network é a nova fabric de scale-out da Google para data centers, projetada especificamente para IA. Ele usa switches de alto radix e topologia não-bloqueante de duas camadas para fornecer largura de banda massiva e baixa latência. Isso permite escalar clusters de até 134.000 chips TPU com desempenho previsível. -
Como a rede da Google lida com as falhas de hardware em clusters enormes?
A Google implementou capacidades de 'confiabilidade autônoma' no Virgo, incluindo detecção automática de hangs e falhas. Quando um componente falha (um fail-stop event), agentes especializados localizam e isolam a instância defeituosa, permitindo restaurar o treinamento a partir de um checkpoint com intervenção manual mínima, maximizando o goodput. -
Por que a largura de banda da rede é tão crítica para treinamento de IA?
O treinamento de IA exige transferência massiva de dados entre milhares de aceleradores. A Google mostra que, ao atualizar de um link de 100 Gbps para 3.2 Tbps, o tempo de transferência de 1 petabyte cai de 22,2 horas para 0,7 horas, reduzindo drasticamente o tempo ocioso do computação de IA. -
O que é o AI-native Cloud Interconnect e para que serve?
É uma interconexão de cloud otimizada para IA, com links de 400 Gbps escaláveis em incrementos de 3.2 Tbps para atingir capacidade de petabit por segundo. Ela oferece diferenciação de tráfego e opções de conexão flexíveis (fibra direta, colocation), sendo ideal para transferir grandes datasets entre clouds ou ambientes on-premises com baixa latência e confiabilidade.
Artigo originalmente publicado por Arjun SinghEngineering Fellow, Google Cloud em Cloud Blog.

![![Demo] Autonomous ML Reliability - Data Center Network](https://storage.googleapis.com/gweb-cloudblog-publish/images/maxresdefault_aGs9w20.max-1000x1000.jpg){kind=link}
![![Demo] High Resolution Network Telemetry: Data Center Network](https://storage.googleapis.com/gweb-cloudblog-publish/images/maxresdefault-1_rh3wgyf.max-1000x1000.jpg){kind=link}