

TL;DR: Este artigo mostra como construir um external scaler para KEDA que lê métricas diretamente das GPUs via NVML, algo que o scaler nativo não permite por restrições de CGO e localidade. A solução é um DaemonSet que expõe dados como utilização, memória e temperatura via gRPC. Para empresas brasileiras que rodam LLMs e agentic inference, isso reduz custos com GPUs ociosas e melhora a eficiência energética (GreenOps).
Se você roda workloads de GPU no Kubernetes — vLLM, Triton, jobs de treinamento ou as novas stacks de agentic inference — já deve ter esbarrado em um problema clássico: o caminho padrão de autoscaling ainda raciocina sobre CPU e memória, enquanto a GPU que realmente está fazendo o trabalho fica oculta. Esse desalinhamento desperdiça capacidade de aceleradores caros, aumenta a latência de inferência e gera consumo de energia desnecessário exatamente no momento em que as empresas estão tentando escalar LLMs e Agentic Ops de forma responsável.
Eu queria que o KEDA escalasse com base nos sinais que importam para workloads de GPU: utilização, memória, temperatura e consumo de energia. Na prática, isso não é só um problema de custo. É também um problema de GreenOps, porque ciclos de GPU desperdiçados se traduzem diretamente em energia desperdiçada e maiores emissões de Escopo 3.
Acontece que isso é mais difícil do que parece.
O problema
O KEDA é compilado com CGO_ENABLED=0. A NVIDIA Management Library (NVML) — a forma padrão de ler métricas da GPU — exige CGO. Então você não pode simplesmente adicionar um scaler de GPU no core do KEDA como faria com um scaler de Prometheus ou Kafka.
Há um segundo problema: o operador do KEDA roda como um único deployment. As chamadas NVML são locais — elas leem métricas da GPU no mesmo node. Você não consegue consultar a GPU 0 do node-A a partir de um pod rodando no node-B.
Portanto, um scaler nativo do KEDA estava fora de cogitação. Eu precisava de algo que rodasse em cada node com GPU e expusesse métricas pela rede.
A arquitetura
Para resolver isso, construímos um DaemonSet personalizado (veja a implementação de referência aqui: keda-gpu-scaler) que roda nos nodes com GPU. Nessa arquitetura, cada pod:
- Chama NVML via go-nvml para ler métricas locais da GPU.
- Serve essas métricas via gRPC usando a interface ExternalScaler do KEDA.
- O operador KEDA se conecta ao scaler e conduz as decisões do HPA.
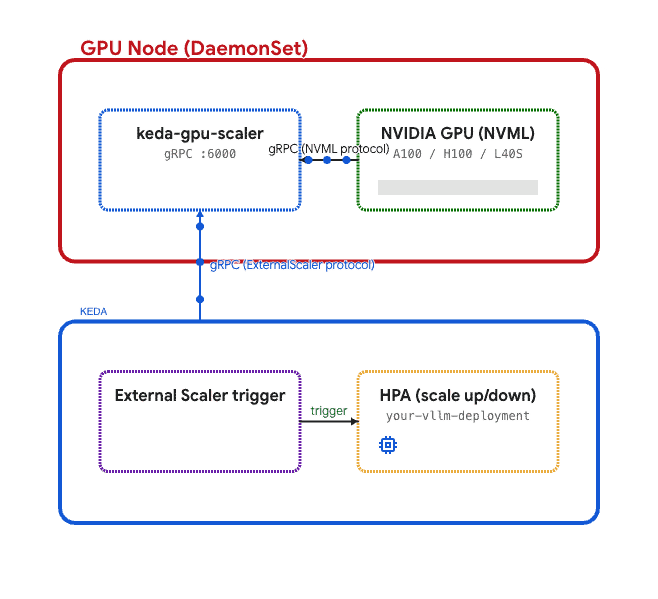
Esse é o mesmo padrão que o Kubernetes usa para device plugins e o metrics server — um agente por node que coleta dados de hardware local.
Em quais métricas você pode escalar?
O scaler expõe estas métricas por GPU:
gpu_utilization– percentual de utilização SM (compute)memory_utilization– utilização do controlador de memóriamemory_used_percent– uso de VRAM como percentualtemperature– temperatura do die da GPU em Celsiuspower_draw– consumo atual de energia em watts
Para nodes multi-GPU, você escolhe uma agregação: max, min, avg ou sum. Ou pode mirar em um índice específico de GPU.
Perfis pré-construídos
A maioria das pessoas roda um de poucos tipos de workload de GPU, então adicionei perfis que definem defaults sensíveis:
triggers:
- type: external
metadata:
scalerAddress: "keda-gpu-scaler.gpu-scaler.svc.cluster.local:6000"
profile: "vllm-inference"
| Perfil | Métrica | Target | Activation | Uso |
|---|---|---|---|---|
| vllm-inference | memory_used_percent | 80% | 5% | LLM serving, scale-to-zero |
| triton-inference | gpu_utilization | 75% | 10% | Triton model serving |
| training | gpu_utilization | 90% | 0% | Treinamento, sem scale-to-zero |
| batch | memory_used_percent | 70% | 1% | Inferência em lote, scale-down agressivo |
Você pode sobrescrever qualquer valor. Ou ignorar os perfis e definir metricType, targetValue e activationThreshold diretamente.
Início rápido
Instalar com Helm
helm install gpu-scaler deploy/helm/keda-gpu-scaler \
--namespace gpu-scaler --create-namespace
O chart cria um DaemonSet que mira nodes com nvidia.com/gpu.present=true e tolera o taint nvidia.com/gpu. Ele usa o container runtime NVIDIA por padrão — se seu cluster não tiver isso, defina nvmlHostMounts.enabled=true para montar os device files diretamente.
Criar um ScaledObject
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: vllm-gpu-scaler
spec:
scaleTargetRef:
name: vllm-deployment
minReplicaCount: 0
maxReplicaCount: 8
triggers:
- type: external
metadata:
scalerAddress: "keda-gpu-scaler.gpu-scaler.svc.cluster.local:6000"
profile: "vllm-inference"
Pronto. Agora o KEDA vai escalar seu deployment vLLM com base no uso de memória da GPU, incluindo scale-to-zero quando ocioso.
Testando sem GPUs
O scaler tem um modo mock para testes. A suíte de testes e2e sobe um servidor gRPC real com dados falsos de GPU e exercita o fluxo completo: IsActive → GetMetricSpec → GetMetrics. São 11 testes cobrindo perfis, caminhos de erro, streaming e modos de agregação. Tudo roda em CI sem hardware de GPU.
go test -v -tags=e2e -race ./tests/e2e/
O que vem a seguir
Construir external scalers personalizados é uma forma poderosa de estender o ecossistema CNCF. Mostra como um projeto graduado como o KEDA pode permanecer flexível, permitindo que engenheiros criem DaemonSets customizados que se adaptam a padrões mais recentes de infraestrutura de IA, sem forçar toda workload à mesma abstração.
Os trechos de código e o repositório compartilhados acima servem como uma implementação de referência open-source dessa arquitetura. Se você está rodando workloads de GPU no Kubernetes e quer autoscaling que entenda nativamente métricas de GPU, explorar a interface ExternalScaler do KEDA é um excelente ponto de partida.
GitHub: keda-gpu-scaler
Perguntas Frequentes
-
Como o KEDA consegue escalar GPUs se ele não suporta NVML nativamente?
KEDA é compilado com CGO_ENABLED=0, o que impede o uso direto da biblioteca NVML (que exige CGO). A solução é rodar um DaemonSet em cada node com GPU, que chama NVML localmente e expõe as métricas via gRPC usando a interface ExternalScaler do KEDA. O KEDA então consulta esse serviço para tomar decisões de scaling. -
Quais métricas de GPU o external scaler expõe?
O scaler expõe cinco métricas por GPU: gpu_utilization (percentual de utilização SM), memory_utilization (utilização do controlador de memória), memory_used_percent (uso de VRAM), temperature (temperatura do die em °C) e power_draw (consumo em watts). Para nós multi-GPU, é possível agregar com max, min, avg ou sum, ou mirar em um índice específico. -
É possível testar o scaler sem ter GPUs físicas?
Sim. O scaler inclui um modo mock que gera dados falsos de GPU. O conjunto de testes e2e sobe um servidor gRPC real com esses dados e exercita todo o fluxo (IsActive, GetMetricSpec, GetMetrics). São 11 testes que cobrem perfis, caminhos de erro, streaming e modos de agregação, executados em CI sem hardware de GPU. -
Como configurar perfis pré-definidos para vLLM ou Triton?
O scaler oferece perfis como vllm-inference (baseado em memory_used_percent com target 80%), triton-inference (gpu_utilization 75%), training (gpu_utilization 90%) e batch (memory_used_percent 70%). Basta definir o campo profile no ScaledObject, podendo sobrescrever qualquer valor ou definir metricType e targetValue manualmente. -
Quais as vantagens desse scaler para empresas brasileiras?
Empresas que rodam LLMs ou agentic inference em clusters Kubernetes podem reduzir drasticamente o custo com GPUs ociosas, já que o scaling é baseado em métricas reais de utilização e memória. Além disso, a economia de energia (GreenOps) é tangível, pois GPU parada consome energia sem produzir throughput, algo crítico em ambientes com restrições orçamentárias e de sustentabilidade.
Artigo originalmente publicado por epower em Cloud Native Computing Foundation.
