

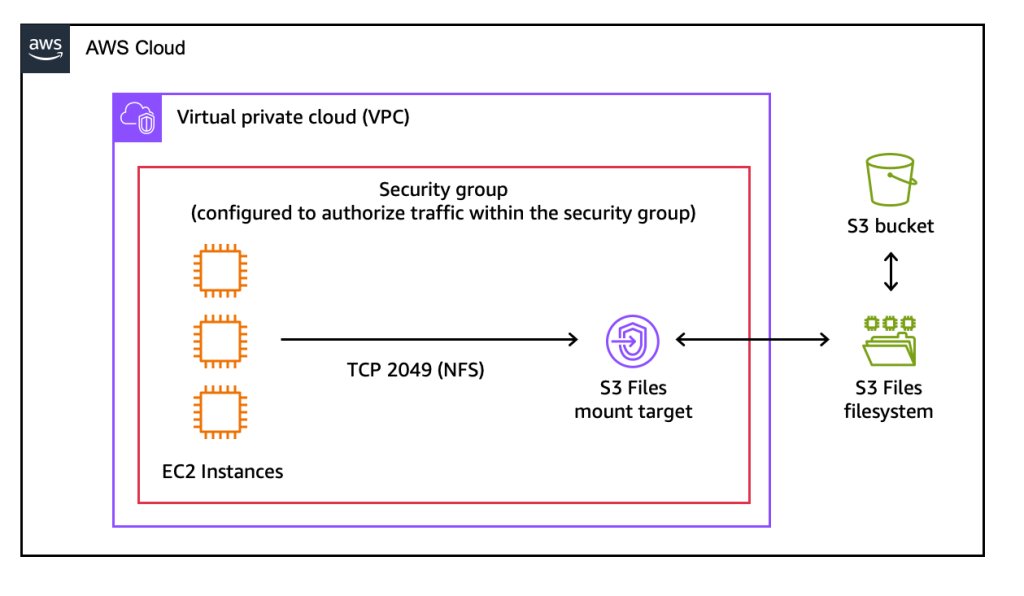
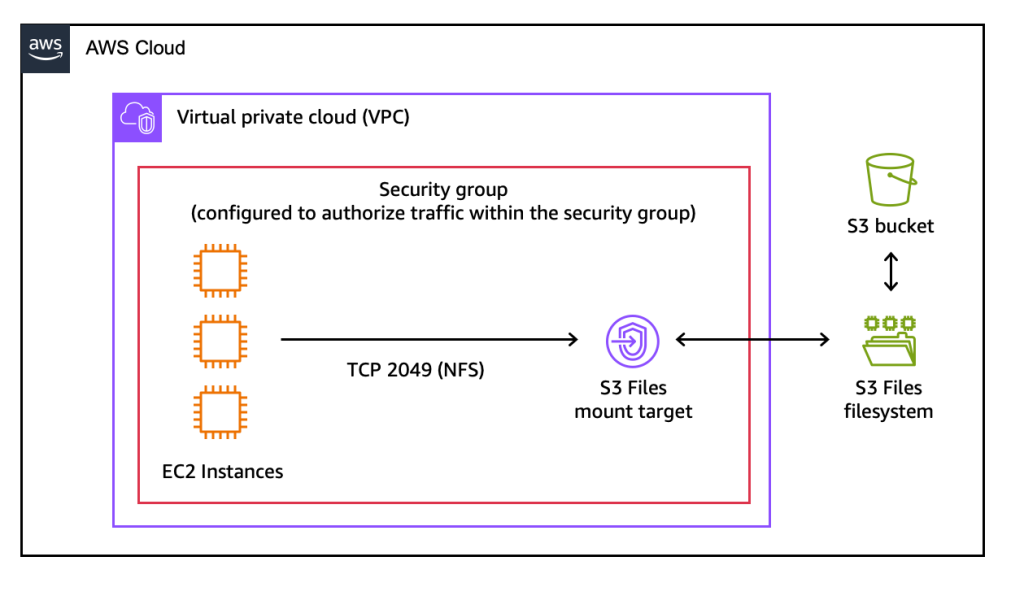
A AWS anunciou o Amazon S3 Files, uma funcionalidade que endereça um dos dilemas mais clássicos da engenharia de dados: a barreira técnica entre o armazenamento de objetos e os sistemas de arquivos tradicionais. Durante anos, arquitetos tiveram que desenhar pipelines complexos para mover dados entre a resiliência do S3 e a interatividade de um File System POSIX. O S3 Files promete reduzir essa camada de abstração, tratando buckets como sistemas de arquivos montáveis.
Historicamente, a distinção era clara: S3 para armazenamento massivo, imutável e de baixo custo; sistemas de arquivos (como EFS ou FSx) para aplicações que exigem leitura/escrita frequente, metadados persistentes e semântica de arquivos. Com o S3 Files, essa fronteira é atenuada, permitindo que instâncias EC2, containers (ECS/EKS) e funções Lambda interajam via NFS v4.1+ diretamente com o bucket, mantendo a sincronização entre a camada de cache de alta performance do sistema e o armazenamento objeto persistente.
O impacto prático na engenharia
O funcionamento técnico é baseado no uso do Amazon EFS sob o capô, garantindo latências na ordem de ~1ms para dados ativos. A grande vantagem estratégica não é apenas a conveniência, mas a eliminação da replicação de dados. Ao evitar o movimento manual entre bucket e volume, reduzimos o operational overhead e o risco de inconsistência em cenários de agentic AI ou ML training pipelines.
Implementação: Fluxo simplificado
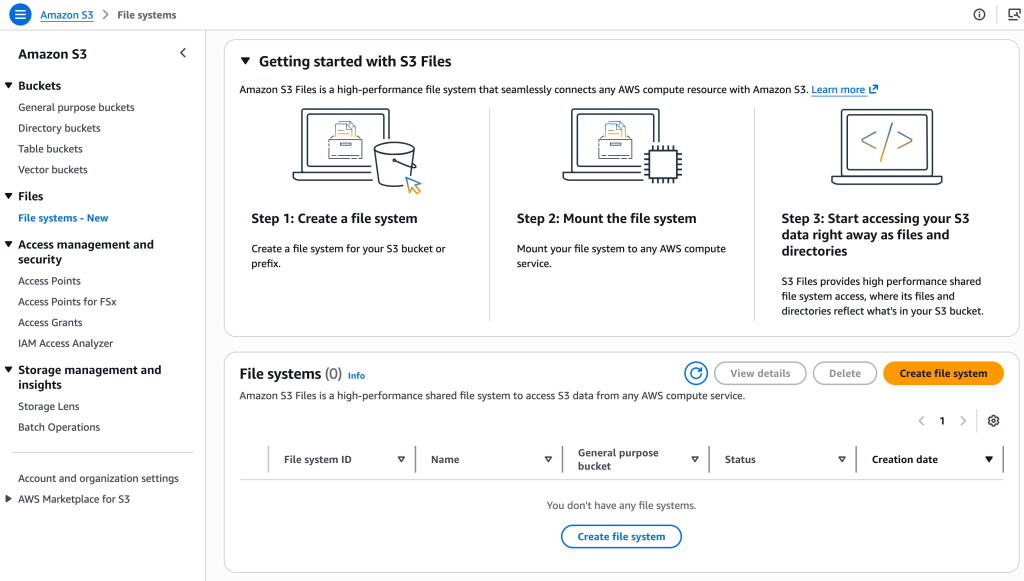
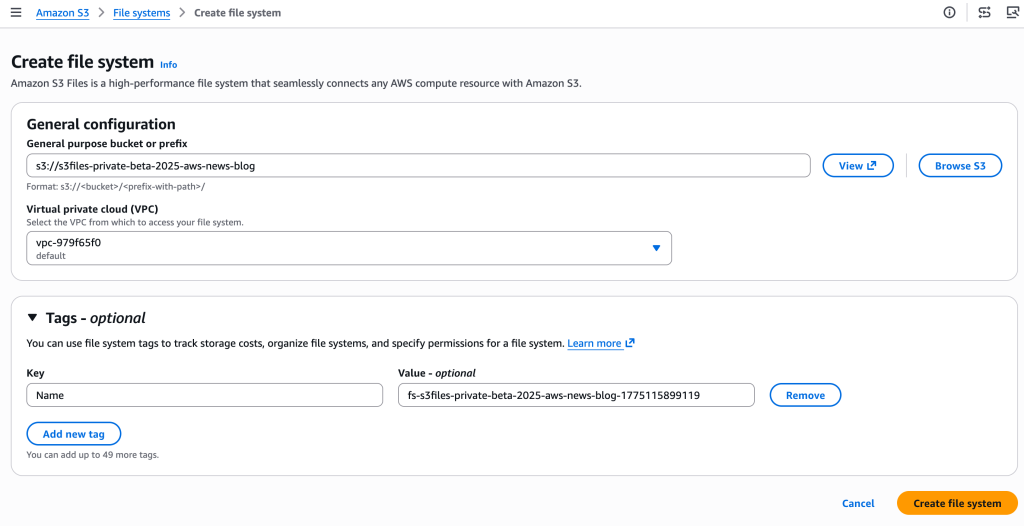
A criação do S3 Files é estruturada em torno de mount targets dentro da sua VPC. O provisionamento, via Console, CLI ou IaC, segue a lógica abaixo:
-
Criação do File System apontando para o bucket de destino.
-
Configuração dos endpoints para conexão do compute.
-
Verificação dos mount targets para integração com o EC2.
Pontos de atenção para empresas no Brasil
Para times que buscam eficiência operacional, é fundamental considerar que, embora o S3 Files simplifique a interface, a precificação é ditada pelo armazenamento ocupado na camada de alta performance e pelo tráfego de dados. Em cenários de grande escala, auditoria de custos (FinOps) se faz necessária para evitar surpresas no billing ao tratar arquivos grandes ou acessos recorrentes que podem disparar requisições de sincronização desnecessárias.
Além disso, lembre-se que, apesar de ser um padrão NFS, a consistência seguindo o modelo close-to-open exige que aplicações legadas sejam validadas em produção antes de migrações massivas. O uso do pacote amazon-efs-utils é um requisito mandatório para assegurar a compatibilidade correta em instâncias baseadas em AMIs customizadas.
Quando utilizar o S3 Files vs. FSx?
A recomendação técnica aqui é clara: para workflows que exigem colaboração via file system sobre dados no S3, o S3 Files é a escolha direta. Contudo, se a carga de trabalho for HPC (High Performance Computing), processamento GPU intensivo (via FSx for Lustre) ou dependência de protocolos específicos de mercado (como NetApp ONTAP para integração com storages NAS on-premises), o Amazon FSx continua sendo o serviço de escolha pelo seu conjunto rico de funcionalidades de nível empresarial e compatibilidade específica.
Artigo originalmente publicado por Sébastien Stormacq em AWS News Blog.
