

Nesta continuação da série, focamos na camada de inteligência: como configurar agentes de IA dentro do seu fluxo de integração com o SAP. A proposta é evitar que o uso de LLMs se transforme em um "caixa-preta" de geração de texto, convertendo a saída do modelo em artefatos determinísticos (summaries, payloads filtrados e listas de erros) que o seu pipeline processa com previsibilidade.
1. Introdução
No artigo anterior, estabelecemos o fundamento de uma integração estável:
- A conectividade entre SAP e Logic Apps via Gateway/Program ID.
- O design de contratos RFC estáveis para entrada (IT_CSV) e saída (envelopes de resposta, tratamento de erros).
- A persistência de falhas via
Z_CREATE_ONLINEORDER_IDOC.
Agora, vamos olhar para o "loop do agente". O diagrama abaixo isola a fronteira de IA, onde a validação ocorre e, consequentemente, dispara ações operacionais (notificações, persistência de IDocs e análise aprofundada).
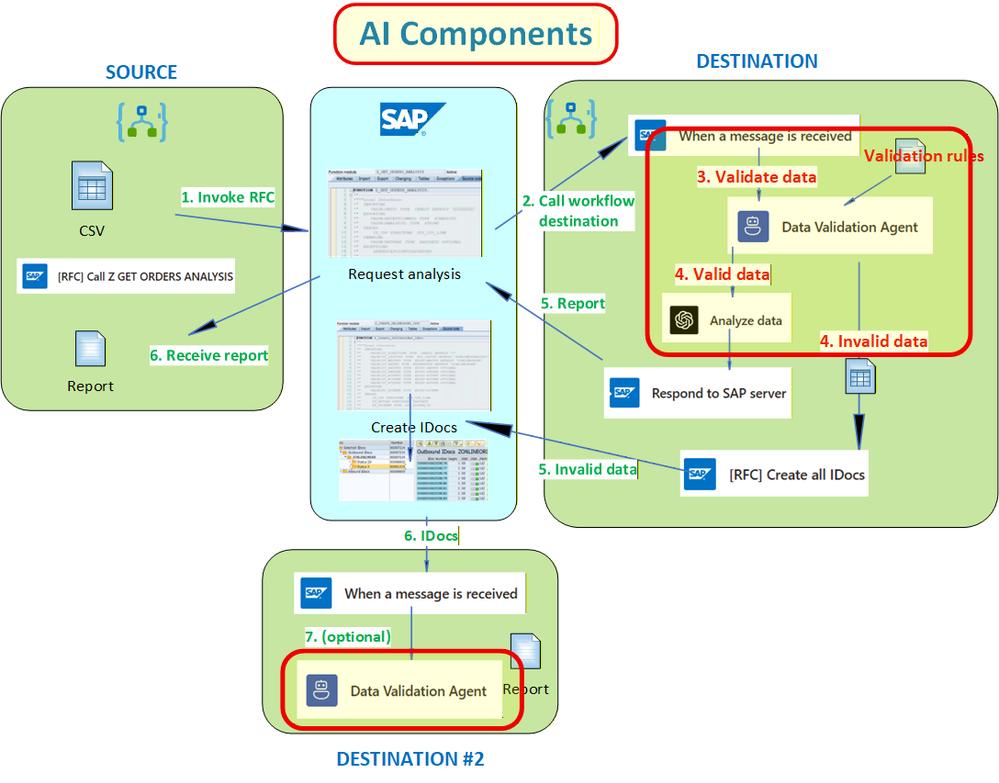
O segredo para um ambiente corporativo é forçar o modelo a emitir dados tipados. Não queremos apenas texto gerado, mas sim resumos em HTML para e-mail, logs estruturados e payloads corrigidos que o SAP possa processar sem intervenção humana.
2. O Loop do Agente de Validação
Dentro do fluxo de destino, o Data Validation Agent atua após a normalização do payload SAP. O agente recebe um CSV construído e as regras de negócio vindas do SharePoint. A configuração não utiliza chats livres; ela é restrita por tools (ferramentas) com contratos de saída bem definidos.
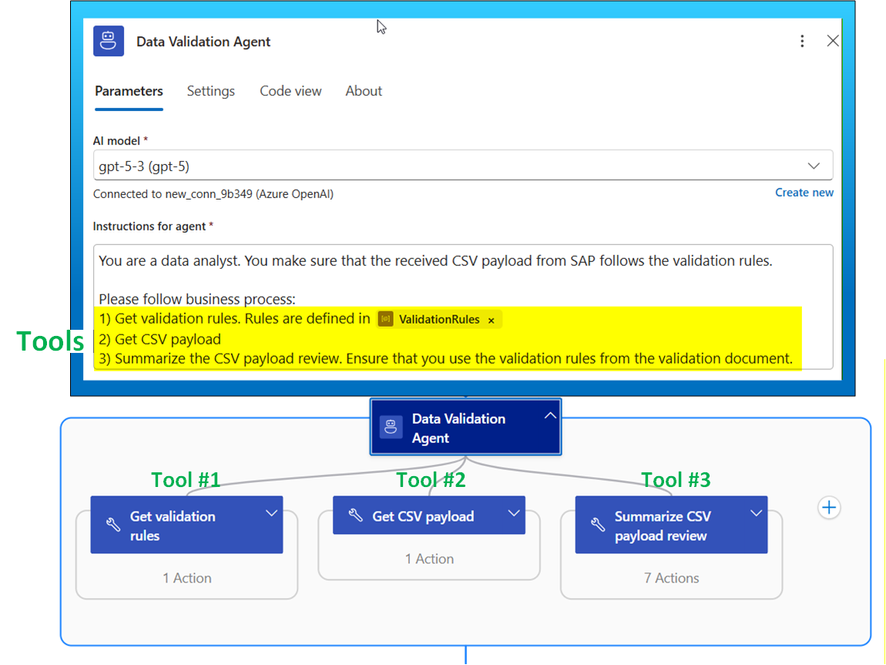
O design é modular: as instruções guiam o processo, enquanto as tools definem o acesso a sistemas externos (Rule retrieval, Get CSV, Summarize). Assim, alterações nas regras de negócio (via documento no SharePoint) não exigem redeploy dos Logic Apps.
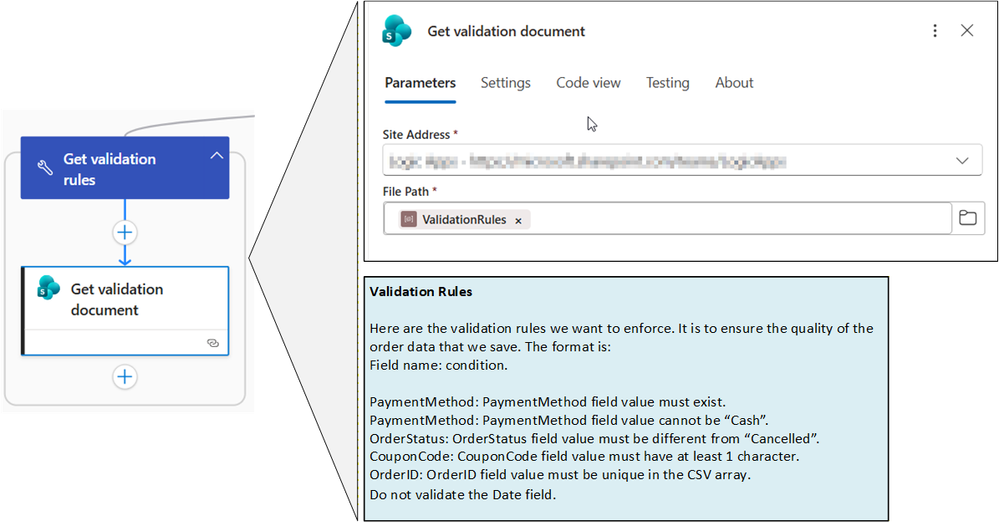
2.1 Recuperação de Regras Externas
Para garantir flexibilidade, as regras residem no SharePoint e são carregadas dinamicamente via GetFileContentByPath. Isso permite que o time de negócio ajuste as condições (ex: "Field X deve ser obrigatório") sem tocar no código do pipeline.
2.2 Binding e Contratos de Dados
Cada tool possui parâmetros de entrada e saída, o que chamamos de "contrato de retorno tipado". Ao definir a saída como CSV ou JSON, garantimos que a função split() ou json() no Logic App funcione de maneira determinística, eliminando falhas de parsing.
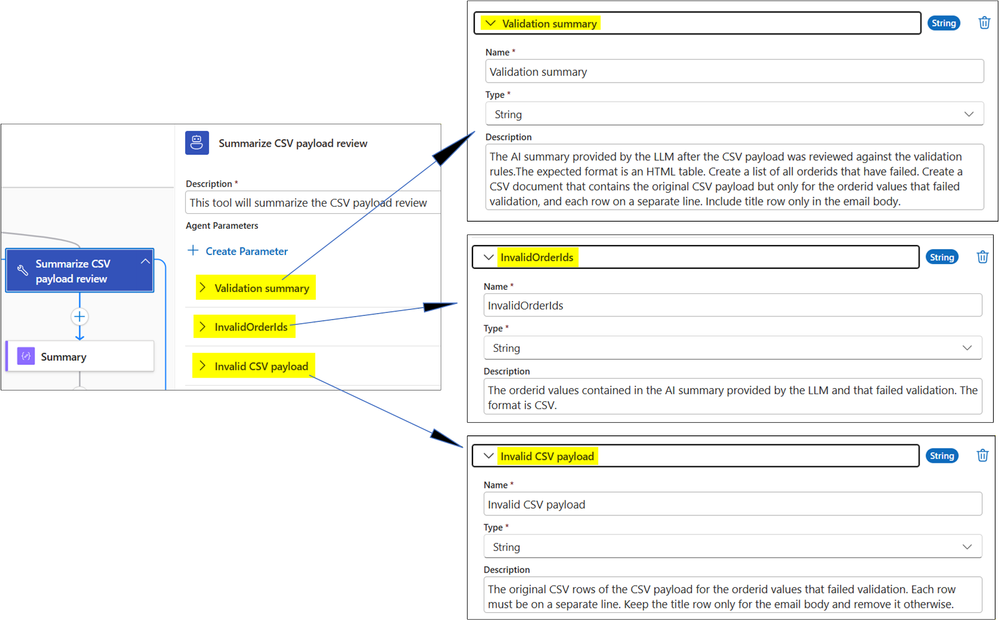
2.3 Resumos e Estruturação
A tool de resumo é onde a IA se torna operacional. Ao descrever as saídas esperadas (ex: "formato de tabela HTML" para e-mails e "CSV de IDs inválidos" para processamento de erros), forçamos o modelo a entregar o que o fluxo precisa, descartando narrativas irrelevantes.
3. Fase de Análise e Persistência
Após a validação, entramos na fase de análise, utilizando o Analyze data. Aqui, separamos o dataset original das IDs inválidas (exclusões). Este padrão de "duplo modelo/fase" é crucial para fins de auditing e controle financeiro (FinOps), garantindo que os tokens e custos sejam bem utilizados. Por fim, os erros gerados são persistidos como novos IDocs. O uso de lease-based writing (bloqueio de lease de blob) no fluxo de destino garante que, em cenários de alta concorrência, nenhum log de erro seja sobreposto.
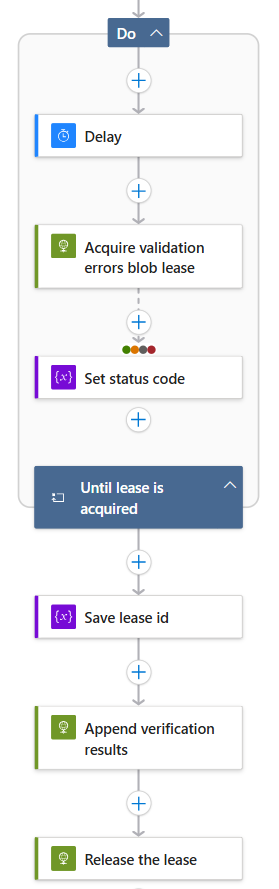
5. Considerações Finais
A lição de casa para times de engenharia é clara: separe a infraestrutura de integração (o plumbing determinístico) da camada de IA. O primeiro é estático; o segundo, iterativo. Use esquemas de saída, contratos de parâmetros e tools restritivas para transformar a IA em um componente tão robusto quanto o seu barramento corporativo.
Artigo originalmente publicado em Azure Updates - Latest from Azure Charts.
