

Visão Geral
Failover groups (FOG) para Azure SQL Managed Instance (SQL MI) são a solução de replicação geo-redundante da Microsoft, garantindo consistência de dados e endpoints estáveis durante desastres. No entanto, em arquiteturas de rede corporativa — especificamente topologias Hub-Spoke com firewalls centralizados (NVA) —, a implementação pode encontrar obstáculos invisíveis. Este artigo analisa um cenário crítico onde a comunicação entre regiões parecia operacional, mas a inicialização do FOG falhava consistentemente.
O Cenário do Cliente
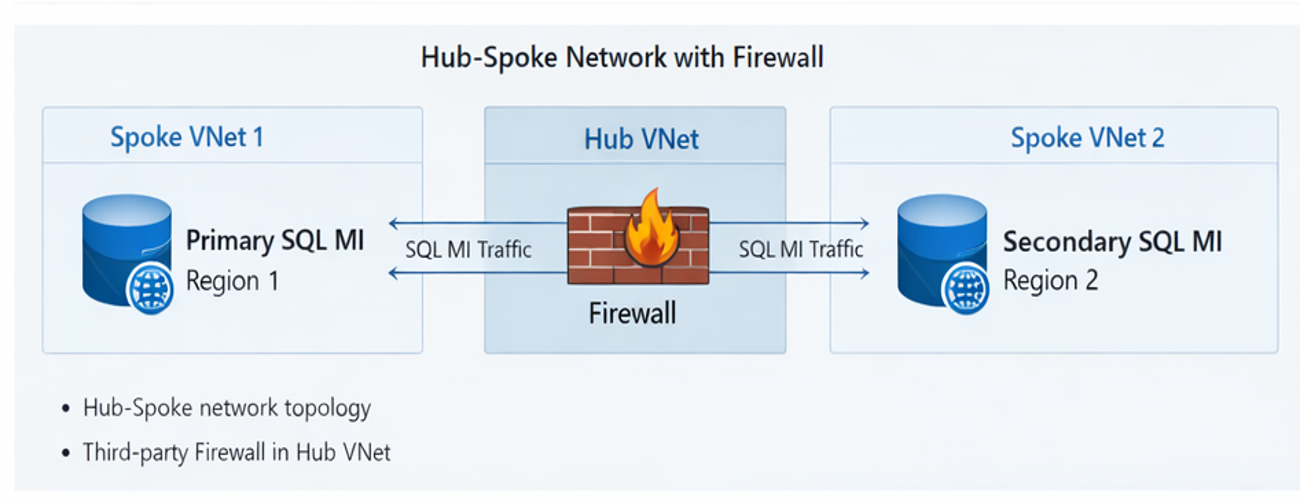
A infraestrutura utilizava uma topologia robusta conforme abaixo:
- Spoke VNet (Região 1): Instância de SQL MI primária em uma subnet dedicada.
- Spoke VNet (Região 2): Instância de SQL MI secundária em uma subnet dedicada.
- Hub VNet: Centralização de segurança através de um firewall de terceiros (NVA).
- Roteamento: Fluxo de tráfego east-west forçado pelo firewall do Hub via UDRs.
O SQL MI opera de forma distinta, dependendo do data-plane e control-plane. Mudanças no design de rede não são apenas opcionais; elas são determinantes para o comportamento do serviço e a viabilidade da replicação.
Problema Identificado
Durante o provisionamento, a criação do Failover Group travava ou falhava por timeout. Embora a conectividade básica entre as VNets estivesse correta, o sistema de validação da plataforma rejeitava a configuração, impedindo o início da replicação dos dados.
Pontos de atenção observados:
- Falhas constantes no provisionamento do cluster de replicação.
- Nenhuma atividade de seeding entre as instâncias.
- Validadores de rede (como
pingou testes simples de rotas) não refletiam as restrições reais de porta específicas exigidas pelo SQL MI.
O Desafio da Conectividade "Aparente"
Para que o FOG funcione, o SQL MI exige conectividade bidirecional via:
- TCP 5022: Porta de replicação.
- TCP 11000–11999: Portas de gerenciamento e comunicação interna.
Em ambientes com NVA, a inspeção de pacotes introduz variáveis complicadoras como UDR steering, NAT/SNAT, e, crucialmente, Timeouts de sessão ociosas. Muitas vezes, o firewall encerra a conexão antes que o processo de handshake da replicação SQL complete, causando falhas "silenciosas" que não aparecem no TRACEROUTE.
Abordagem de Investigação
Para diagnosticar, seguimos uma estratégia em camadas:
- Validação de Pré-requisitos: Verificação rigorosa de requisitos técnicos, como instâncias secundárias vazias, alinhamento de Service Tier e o uso obrigatório do mesmo DNS Zone ID (ponto frequente de erro).
- Testes "SQL MI-Aware": Abandonamos testes de ping tradicionais em favor de scripts de SQL Agent dentro das instâncias, que validam a conectividade real nos endpoints específicos da replicação.
- Análise do Caminho de Firewall: Inspeção de como o NVA tratava o tráfego east-west. Verificamos, especificamente, se políticas de inspeção TLS ou NAT/SNAT estavam alterando os pacotes de replicação.
Hipóteses de Falha Comuns
Em nossas análises de casos similares, isolamos sete causas raízes recorrentes:
- Abertura incompleta de portas: Apenas a porta 5022 é liberada, ignorando o range 11000-11999.
- Regras em conflito: NSGs (Network Security Groups) configurados corretamente, mas políticas de firewall com prioridade superior bloqueando o fluxo.
- Roteamento Assimétrico: O tráfego de saída sai pelo firewall, mas o de retorno tenta tomar um atalho sem passar pela inspeção, rompendo o estado de conexão do NVA.
- SNAT/NAT excessivo: Modificação do IP de origem/destino, violando a identidade da instância SQL.
- Timeouts de sessão ociosas: A replicação, quando em latência ou em grandes volumes iniciais, sofre interrupção por inatividade forçada.
- Mismatches de DNS Zone ID: Impossibilidade de modificação pós-criação.
- Sobreposição de Address Space: Conflitos de CIDR entre VNets peered.
Lições Aprendidas e Checklist de Pré-Voo
Ao desenhar topologias Hub-Spoke, ignore a tentação de tratar o tráfego entre bancos de dados como qualquer outro tráfego de aplicação. Inclua isto no seu checklist:
- Planejamento de Endereçamento: Garanta isolamento total de CIDRs.
- DNS: Reuso obrigatório de DNS Zone ID na criação da secundária.
- Regras de Firewall: Liberação estrita (Inbound/Outbound) nas portas 5022 e 11000–11999 em todos os pontos de enforcement.
- Estabilidade de Rota: Evite qualquer forma de NAT ou inspeção profunda (Deep Packet Inspection) sobre o fluxo de replicação.
O principal aprendizado aqui é estratégico: falhas em Failover Groups raramente são problemas do SQL em si, mas sim reflexos de uma rede que não foi desenhada para a natureza proprietária dos fluxos de replicação do Azure PaaS.
Artigo originalmente publicado em Azure Updates - Latest from Azure Charts.
