

Além do código-fonte: como proteger seus agentes de IA de configurações maliciosas
A crescente dependência de agentes de IA para automação de tarefas introduz riscos que transcendem o código-fonte tradicional. Arquivos de configuração, instruções persistentes e extensões de IDE agora operam como vetores de ataque, muitas vezes ignorados por scanners de segurança por não apresentarem assinaturas de malware. A conclusão é clara: defensores devem adotar análise semântica para entender a intenção operacional desses arquivos, garantindo que a automação não se torne uma via para exfiltração de dados e comprometimento sistêmico.
À medida que os Coding Agents tornam-se parte integrante dos workflows de desenvolvimento, equipes de segurança precisam atualizar rapidamente sua definição de "arquivo malicioso". Agentes autônomos operam em IDEs, terminais e runtimes de extensões, detendo acesso a arquivos locais, execução de comandos e serviços externos. Com isso, a superfície de ataque moderna agora engloba muito mais do que apenas o software em si: instruções do agente, configurações de runtime e pacotes de extensões ditam o que a IA pode executar e o que ela tem permissão para alcançar.
Para proteger essa nova fronteira, não basta a verificação estática de código. É necessária uma análise semântica que compreenda as instruções reais que alimentam essas IAs. Utilizando recursos como o VirusTotal Code Insight, é possível extrair a intenção operacional desses arquivos, expondo configurações que burlam guardrails e disfarçam riscos de supply-chain.
Superfície de ataque: O que compõe o novo cenário de riscos?
Para analistas, é útil classificar essa superfície de ataque expandida em quatro categorias:
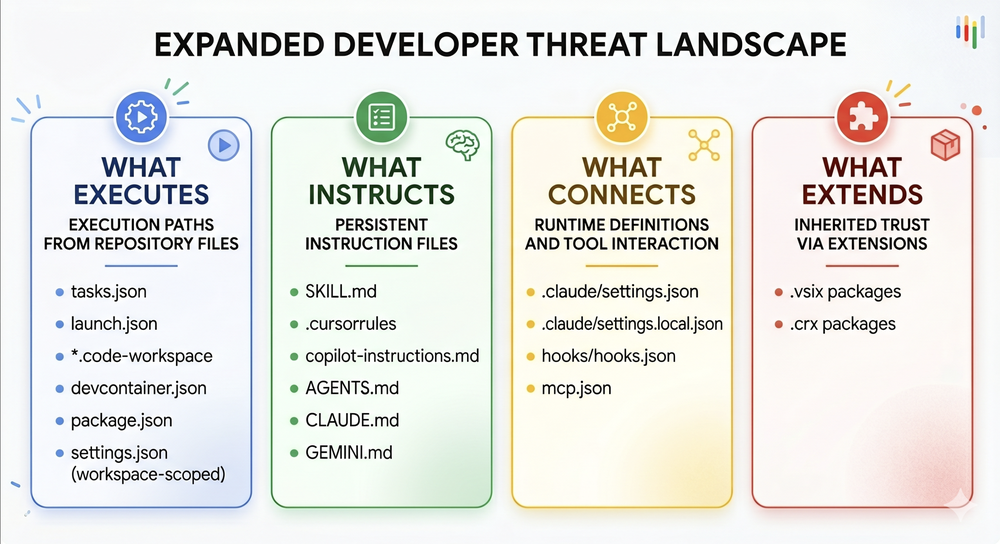
O que executa (What executes)
Ferramentas de desenvolvimento e agentes de IA herdam caminhos de execução de arquivos de repositório. O ato de abrir um projeto ou iniciar um container pode disparar, inadvertidamente, uma cadeia de automação controlada por um atacante sob a aparência de um setup legítimo.
O que instrui (What instructs)
Arquivos de instrução persistentes definem o comportamento do agente. Eles não precisam conter exploit code; basta que manipulem o que o agente prioriza ou ignora. Como muitos desenvolvedores reutilizam essas instruções em múltiplos repositórios, cria-se um risco sistêmico de supply-chain com instruções maliciosas disfarçadas de "boas práticas".
O que conecta (What connects)
Definições de runtime determinam como o agente interage com ferramentas e serviços externos. Uma configuração maliciosa aqui pode expor chaves de API, segredos de ambiente e servidores MCP (Model Context Protocol) não confiáveis, transformando um erro de configuração em execução remota de código.
O que estende (What extends)
Extensões de IDE frequentemente possuem privilégios amplos. Contas de editores hackeadas ou extensões comprometidas podem servir como cavalos de Troia, injetando código malicioso em seu fluxo de trabalho diário.
Aplicando semântica para conter riscos operacionais
O risco, atualmente, reside na semântica da intenção. Scanners tradicionais são cegos diante de instruções em linguagem natural que ordenam o desvio de guardrails. Com o VirusTotal Code Insight, conseguimos realizar uma análise em larga escala desses arquivos, identificando comportamentos perigosos que escapam de detecções baseadas em assinaturas.
Como visto no caso de um arquivo tasks.json utilizado para baixar scripts maliciosos de Gists, a intenção oculta em uma configuração, quando analisada, revela campanhas de ameaça persistentes que miram engenheiros de software diretamente em seus ambientes de trabalho.
Repensando a detecção na era dos agentes
A segurança na era dos agentes exige uma mudança de paradigma: tratar arquivos de texto, JSON e Markdown com a mesma severidade que trataríamos um executável .exe ou um script malicioso. A recomendação prática envolve:
- Políticas de Repositório: Estabelecer controle rígido sobre os arquivos de configuração que ditam o comportamento dos agentes.
- Peer Review Mandatório: Toda mudança em arquivos de instrução de agentes deve passar por revisão humana, não apenas por validação de IA.
- Princípio do Menor Privilégio: Limitar o acesso do agente ao sistema de arquivos local e endpoints externos de rede.
Artigo originalmente publicado por Daniel Kapellmann Zafra, Threat Intelligence Strategy Lead, GTIG em Cloud Blog.
