

A Inteligência Artificial é sustentada pela qualidade dos dados. Eles são o combustível essencial para o treinamento de modelos, o raciocínio de agentes e a experiência do usuário final. No entanto, essa dependência cria uma superfície de ataque crítica, onde vazamentos de dados sensíveis e o uso indevido de informações privadas tornam-se riscos constantes para operações corporativas.
Na era da IA, controles de segurança baseados apenas em tagging manual ou simple keyword matching tornaram-se obsoletos. A proteção efetiva agora exige uma compreensão profunda do contexto, uma abordagem muito mais sofisticada do que os métodos tradicionais de data loss prevention.
Para enfrentar esse desafio, o Google Cloud evoluiu o seu Sensitive Data Protection (SDP). A nova tecnologia utiliza classificadores de contexto avançados — incluindo domínios médicos e financeiros — e detectores de objetos em imagens (como faces e documentos de identidade). Essa camada extra de inteligência permite que o motor de regras identifique e mascare informações sensíveis mesmo dentro de documentos não estruturados ou arquivos de mídia, garantindo que agentes de IA acessem apenas o necessário para suas funções.
A disponibilidade geral dessas capacidades permite às empresas viabilizar o uso de dados em todo o ciclo de vida da IA, desde o fine-tuning até as respostas em tempo real, mitigando riscos de exposição de PII (Personally Identifiable Information).
AI tuning e sanitização de dados no Vertex AI
Ao realizar o tuning de modelos como o Gemini com dados proprietários, você pode estar inserindo riscos ocultos no seu pipeline. No Vertex AI, o SDP atua como uma camada de observabilidade, escaneando continuamente seu ambiente em busca de marcadores sensíveis.
Um diferencial prático é a capacidade de processar dados não estruturados via OCR e detecção de objetos: em vez de descartar imagens valiosas para o treinamento, o sistema pode mascarar seletivamente apenas as partes sensíveis (como uma face em uma foto de um processo de suporte).
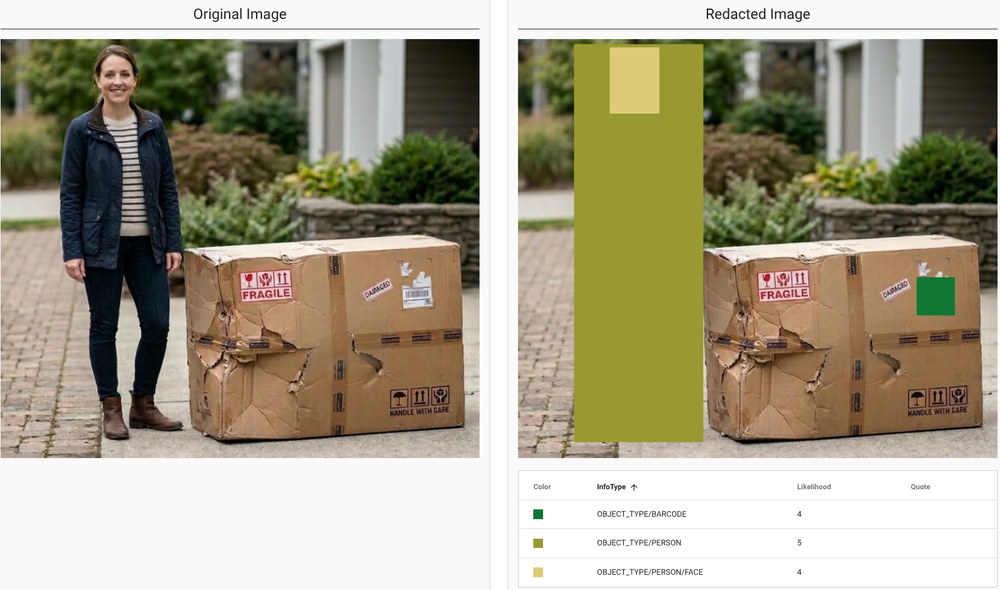
Você pode consultar a lista completa de object types que o SDP consegue identificar e aplicar redação.
Securing live AI interactions
Após o deployment, o desafio migra para a gestão de interações em tempo real. Cada prompt enviado por um usuário deve ser validado quanto à conformidade antes de ser processado pelo modelo.
O SDP utiliza a compreensão semântica para diferenciar contextos. Se um usuário relata: “Meu braço está quebrado e não consigo usar a tela”, o sistema identifica o contexto DOCUMENT_TYPE/CONTEXT/HEALTH e bloqueia ou mascara a informação sensível. Já diante de um “Meu wifi parou de funcionar”, o motor compreende que se trata de uma demanda técnica, mantendo o fluxo funcional.
Essa capacidade de classificação é crucial para times que buscam manter o throughput de seus agentes sem ignorar o compliance.
Aumentando a precisão com contexto e regras
O grande problema das abordagens puramente baseadas em RegEx é o alto volume de falsos positivos. O SDP resolve isso combinando detecção de padrões com análise semântica. Ao entender a categoria (financeiro, legal, médico), o sistema ajusta o nível de confiança das suas detecções.
Por exemplo: o número de uma ordem de serviço não deve ser tratado com a mesma sensibilidade que uma chave de acesso bancária, mesmo que ambos possuam padrões numéricos similares. É o contexto – a palavra “carteira” ou “wallet” – que dita o gatilho de segurança.
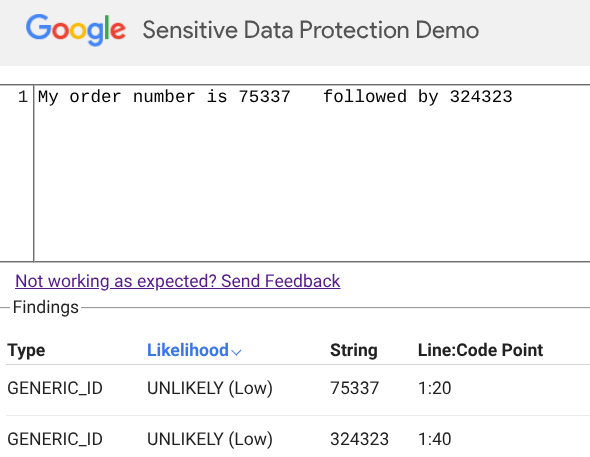
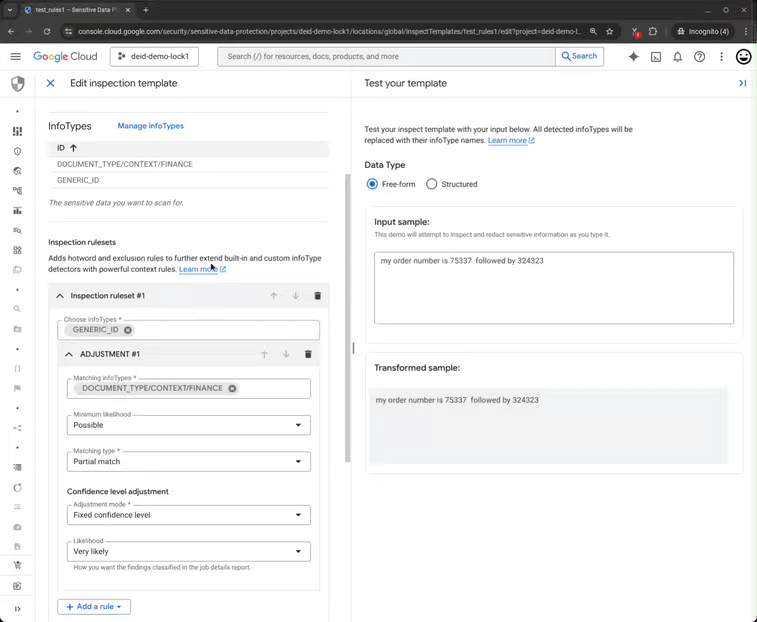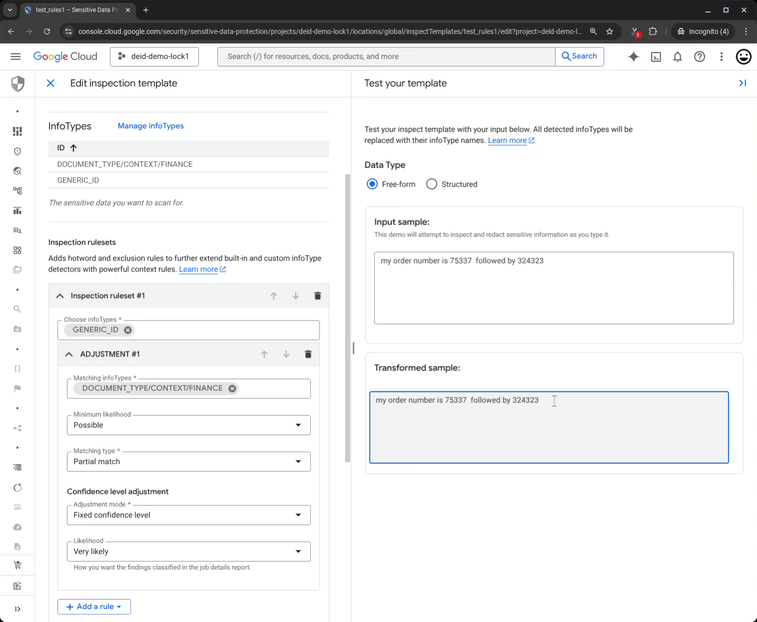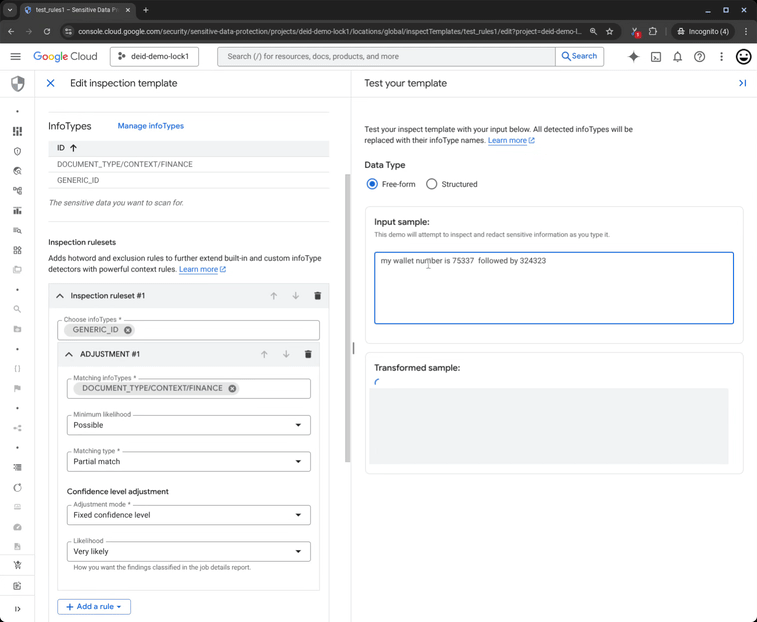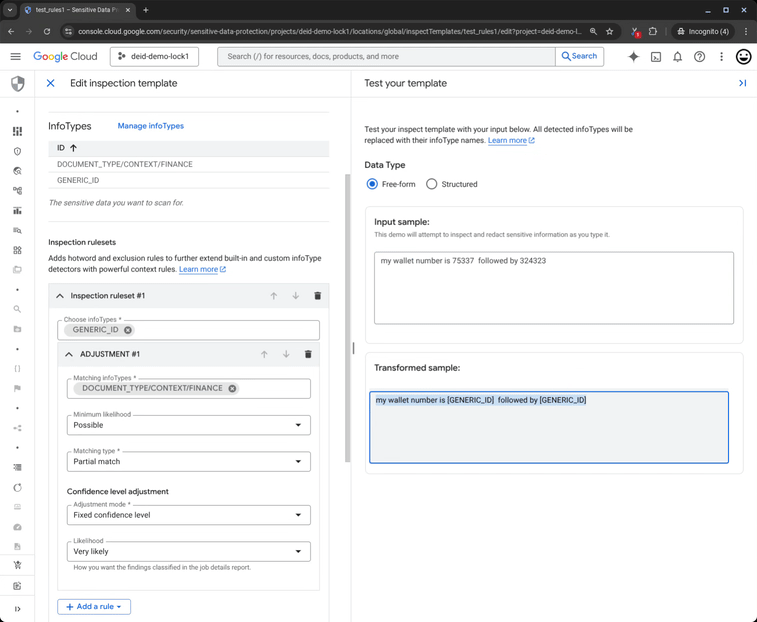
Para empresas brasileiras, essa automação é um ganho de eficiência operacional imenso. Menos falsos positivos significam menos tickets para os times de SecOps e uma jornada de desenvolvimento (shift-left) mais fluida.
O SDP já serve como a fundação de segurança para ferramentas como Model Armor e Security Command Center. Integrar essa camada de contexto no seu pipeline não é apenas uma boa prática de segurança, é um requisito estratégico para escalar modelos de IA com confiança.
Artigo originalmente publicado por Ivan MedvedevEngineering Manager em Cloud Blog.
