

Para engenheiros e gestores que operam aplicações com alto volume de leituras, o desafio clássico é o gargalo no banco de dados primário. Historicamente, a solução era o desvio dessas cargas para read replicas, mas essa estratégia frequentemente esbarra na complexidade de gerenciamento: administrar manualmente múltiplos nós, configurar load balancers e garantir que o ciclo de vida dos containers ou instâncias não impacte a disponibilidade do serviço é uma tarefa que consome valiosas horas de engenharia.
O Google Cloud evoluiu essa abordagem com os Cloud SQL Read Pools. Agora, com a adição do autoscaling, essa funcionalidade deixa de ser uma simples alocação estática para se tornar um mecanismo dinâmico, disponível na edição Cloud SQL Enterprise Plus. O ponto central aqui não é apenas a feature em si, mas como o agrupamento de nós sob um único read endpoint simplifica o desenho da arquitetura e remove a necessidade de mudanças constantes no código da aplicação.
O conceito de Read Pools: Por que usar?
Quando você provisiona um read pool, o Cloud SQL abstrai a camada de réplicas em um conjunto de "nodes". O diferencial operacional reside no read endpoint: um único load balancer que distribui as queries via round-robin. Isso suporta de 1 a 20 nós, gerenciados como uma entidade única — se você altera uma configuração, flag de banco de dados ou tipo de VM, a alteração é aplicada a todos os nós do pool de forma consistente.
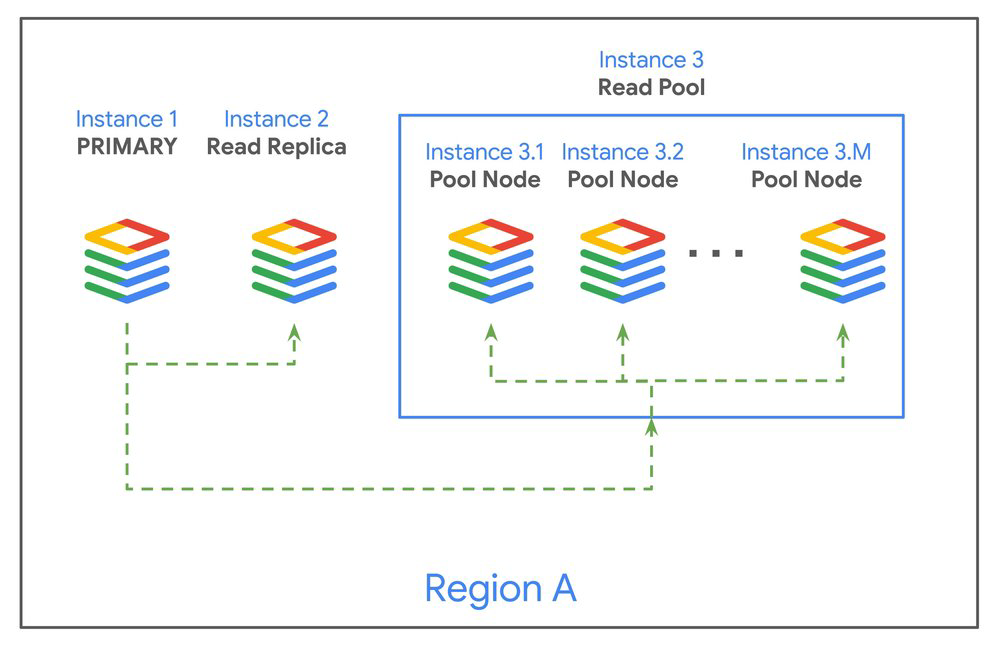
Essa gestão unificada é o que permite o scale-out e scale-in de forma transparente. Como a aplicação aponta sempre para o mesmo endpoint, os processos de deployment ou reconfiguração de infraestrutura ocorrem sem a necessidade de atualizar strings de conexão na camada de aplicação.
Escalabilidade dinâmica com Autoscaling
Em cenários brasileiros, onde picos de tráfego são comuns — especialmente no e-commerce ou em serviços de alto impacto — o over-provisioning é um inimigo silencioso (e caro) do seu orçamento de cloud. O autoscaling para read pools soluciona isso nativamente:
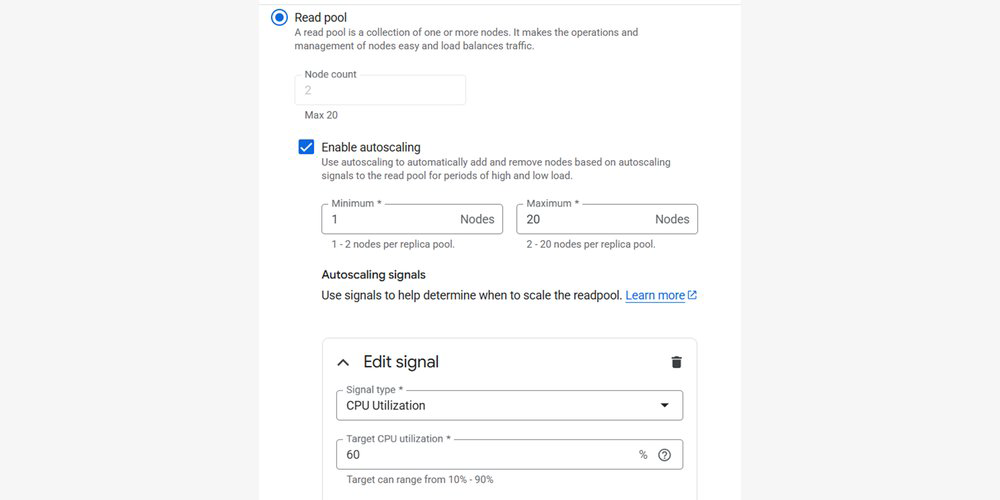
- Gestão automática de tráfego: O sistema escala até 20 nós com base em CPU ou número de conexões ativas, garantindo SLA sem intervenção manual.
- Eficiência de custos (FinOps): A capacidade de reduzir a escala em horários de baixa demanda é aplicada diretamente na redução do custo fatural.
- Simplicidade operacional: O endpoint único mantém a consistência enquanto os nós são rotacionados ou escalados.
Para cenários de alta disponibilidade, o Cloud SQL mantém no mínimo dois nós, integrando-se ao SLA de 99,99%. O sistema é inteligente o suficiente para realizar manutenções com near-zero downtime e remover automaticamente instâncias consideradas insalubres (unhealthy) da rota de load balancing.
Aplicação Prática: O caso do Varejo
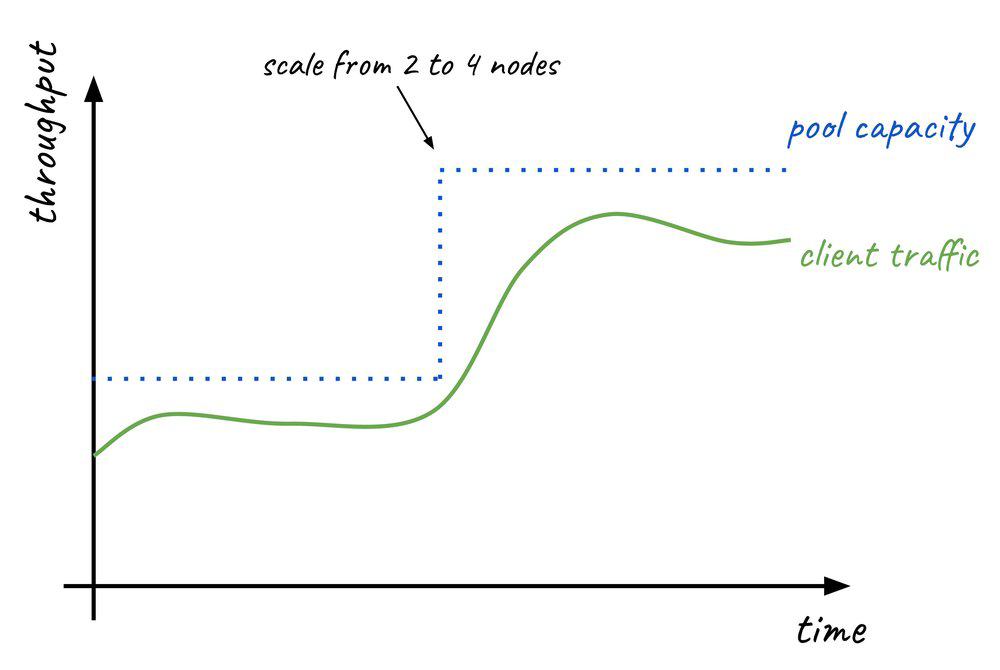
Considere picos sazonais, como a Black Friday. Com o escalonamento horizontal automático, sua infraestrutura absorve a carga adicional sem sacrificar a latência, e retrai instantaneamente quando o volume normaliza.
Exemplo de Implementation via gcloud CLI
Para criar um pool com autoscaling configurado para usar a utilização de CPU como métrica (alvo de 60%), utilize o comando abaixo:
gcloud sql instances create myautoscaledreadpool \
--tier=db-perf-optimized-N-4 --edition=ENTERPRISE_PLUS \
--instance-type=READ_POOL_INSTANCE \
--master-instance-name=myprimary \
--region=us-west1 \
--node-count=2 \
--auto-scale-enabled \
--auto-scale-min-node-count=2 \
--auto-scale-max-node-count=10 \
--auto-scale-target-metrics=AVERAGE_CPU_UTILIZATION=0.60
Para pools existentes, o comando de patch habilita o recurso:
gcloud sql instances patch myreadpool \
--auto-scale-enabled \
--auto-scale-min-node-count=2 \
--auto-scale-max-node-count=10 \
--auto-scale-target-metrics=AVERAGE_DB_CONNECTIONS=100
Caso precise retomar o controle manual, o parâmetro --node-count sobrescreve a política de autoscaling. Em ambientes de missão crítica, a recomendação é utilizar estas automações para reduzir o toil (trabalho manual operacional) e focar a atuação do seu time de engenharia em deploy e performance, delegando a infraestrutura de replicação ao plano gerenciado.
Artigo originalmente publicado por Shahzeb FarrukhProduct Manager em Cloud Blog.
