

A gestão de observabilidade em larga escala no Azure Monitor frequentemente atinge um ponto crítico de maturidade operacional: transformar sinais em valor. Para muitos times brasileiros que operam ambientes complexos, os alertas tornaram-se mais um ruído de fundo do que uma ferramenta de confiança.
O Problema do Alerta: A Fadiga Operacional
Organizações que escalam rapidamente tendem a acumular um "legado de alertas". Regras de threshold de CPU criadas durante migrações ou health probes obsoletas permanecem ativas anos após a necessidade inicial. Quando esses alertas disparam, a equipe tende a ignorá-los ou fechar tickets automaticamente, criando um risco real: incidentes críticos podem ser negligenciados no mar de notificações irrelevantes.
Além disso, o esforço humano é dispendido de forma ineficiente. Engenheiros realizam o mesmo trabalho de triagem repetidamente — validando diagnósticos para falsos positivos ou picos transitórios — sem que o aprendizado seja aplicado para corrigir a regra na origem.
A lacuna é clara: falta uma camada de inteligência entre o Azure Monitor e a equipe de operação. O Azure SRE Agent atua aqui como um mediador inteligente, processando alertas em tempo real, consolidando eventos correlacionados e fornecendo insumos para que a engenharia ajuste as regras de observabilidade com base em dados, não em suposições.
Aqui está uma análise técnica de como estruturar essa inteligência operacional.
1. Manipulação Inteligente: Cooldown e Planos de Resposta
A configuração mais impactante para otimizar o Azure Monitor é o novo reinvestigation cooldown. Trata-se de uma configuração por response plan que dita o ciclo de vida do agente frente a disparos repetidos da mesma regra.
Quando um alerta dispara e o agente já possui uma thread ativa para aquele cenário, ele consolida os disparos. Se a thread anterior estiver dentro da janela de cooldown, ele a reabre, tratando o evento como parte do mesmo incidente e evitando que novos tickets sejam abertos desnecessariamente.
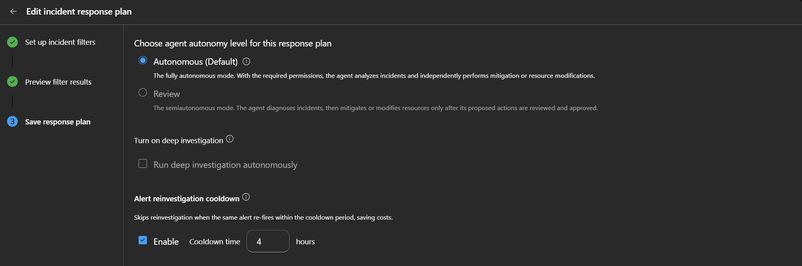
Para cenários críticos, a recomendação é desabilitar o merge para garantir que cada disparo exija atenção imediata:
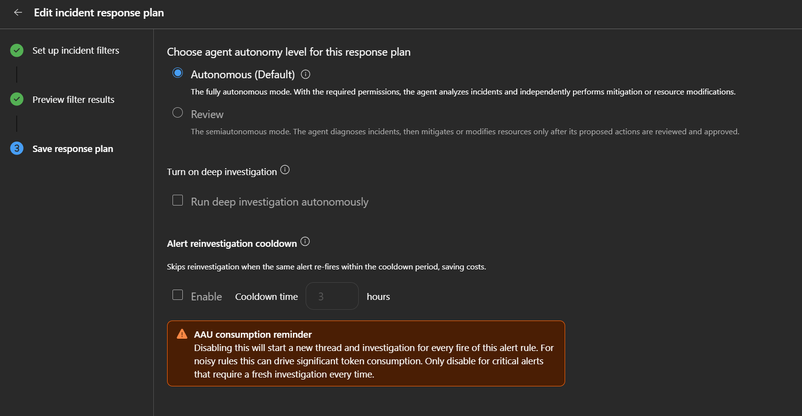
A segmentação por response plans é fundamental para o sucesso dessa estratégia:
- Alertas Críticos (Sev0-1): Desabilite o cooldown. Falhas críticas de segurança ou disponibilidade exigem resposta dedicada sempre.
- Alertas Operacionais (Sev2): Aplique um cooldown de 6 horas. Picos recorrentes de CPU ou latência dentro desse intervalo quase sempre apontam para a mesma causa raiz.
- Alertas de Baixa Prioridade (Sev3-4): Utilize um cooldown curto de 1 hora. Eles fornecem contexto sem drenar a energia do time com análises redundantes.
2. Monitoramento de Ruído: O Círculo de Melhoria Contínua
Após configurar o manuseio inteligente, o próximo nível é permitir que o agente realize seu próprio audit. A implementação de um relatório semanal de higiene de alertas é o diferencial para times que buscam eficiência operacional (FinOps e DevOps).
A análise de threads dos últimos 7 dias permite identificar:
- Regras com altas taxas de auto-resolução (candidatas a ajuste de threshold).
- Regras com causas raízes recorrentes (necessitam de correção de engenharia, não apenas resposta ao incidente).
- Severidade desalinhada com o impacto real.
Complementarmente, a auditoria mensal de thresholds comparando valores atuais com percentis (P50, P90, P99) permite otimizar as regras com base em métricas reais, eliminando disparos desnecessários permanentemente.
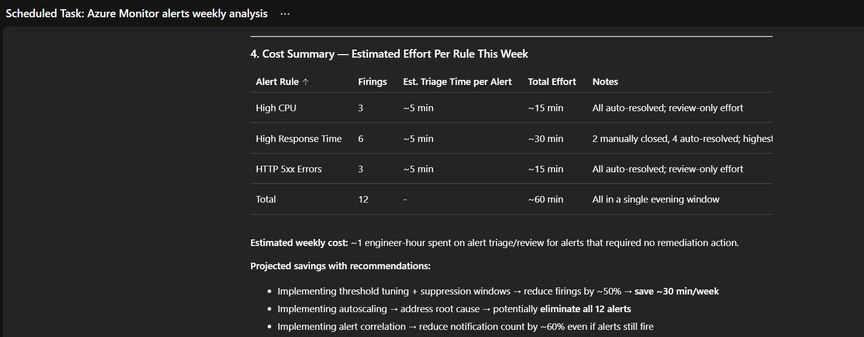
Considerações sobre Custos de Inteligência
A inteligência não é gratuita em termos de tokens. O uso desmedido de LLMs para investigar todos os disparos pode inflar os custos inesperadamente. Portanto, a configuração de cooldown eficiente e o uso de planos de resposta hierárquicos não são apenas boas práticas de SRE, mas estratégias de FinOps. O uso de hooks como o PostToolUse, que restringe o escopo temporal de consultas em Log Analytics, é altamente recomendado para evitar contextos conversacionais excessivamente longos e caros.
Por Onde Começar?
- Conecte o Azure Monitor como fonte no SRE Agent.
- Habilite o reinvestigation cooldown (3h é um excelente ponto de partida).
- Crie planos de resposta segmentados por severidade.
- Automatize o relatório de higiene semanal.
- Quando tiver dados suficientes, execute a auditoria mensal de thresholds.
Artigo originalmente publicado em Azure Updates - Latest from Azure Charts.
