

Resumo executivo
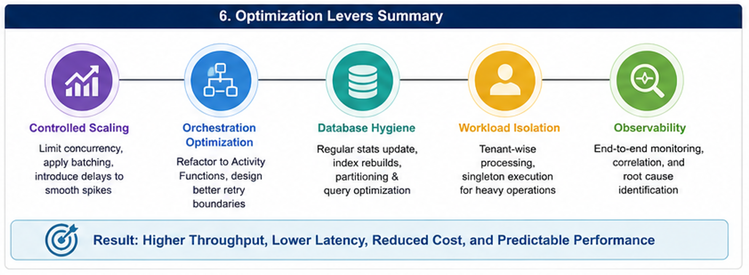
Este artigo analisa o desafio de escalar sistemas em nuvem, onde o aumento de recursos frequentemente falha em resolver gargalos de performance. A conclusão é que o escalonamento deve ser acompanhado por um design de orquestração eficiente, controle estrito de concorrência em Azure Functions, manutenção proativa de índices SQL e observabilidade rigorosa. O foco deixa de ser o aumento de capacidade e passa a ser a eficiência na execução e a redução da carga desnecessária.
Por que escalar nem sempre significa performar melhor?
Frequentemente, projetamos sistemas distribuídos com a premissa de que o scale-out é a solução universal para gargalos. No entanto, em cenários intensivos em orquestração e banco de dados, essa abordagem pode ser contraproducente. Em uma arquitetura processando milhões de registros via Azure Functions e SQL, observamos que o escalonamento descontrolado resultava em:
- CPU e memória sob estresse constante;
- Latência elevada em queries SQL;
- Throttling acionado no Service Bus;
- Ciclos de vida úteis prejudicados pelo aumento massivo de retries.
O problema não era a falta de recursos, mas a ineficiência do padrão de execução sob alta carga. A solução exigiu transitar do "brute-force scaling" para uma estratégia com controle rigoroso de concorrência e processamento em lote, garantindo throughput previsível e estável.
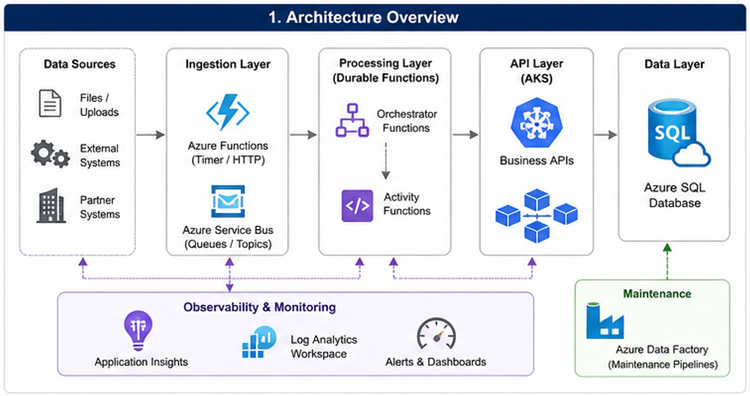
Como identificar o verdadeiro gargalo?
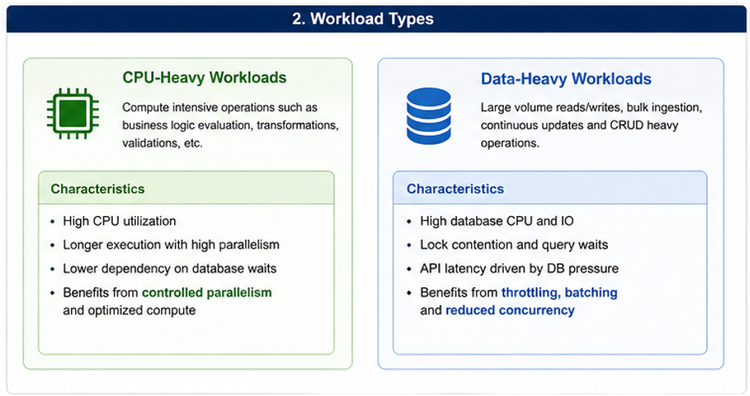
Antes de ajustar qualquer configuração, é vital distinguir se o seu workload é CPU-heavy ou Data-heavy. Essa classificação dita a natureza da otimização – seja na infraestrutura de compute ou no tunning da camada de persistência.
Otimizando a Computação: CPU e Memória
Após estabilizar o comportamento de escala, focamos na eficiência computacional:
- CPU: Reduzimos o fan-out desnecessário em orquestrações e limitamos a execução paralela de funções críticas, evitando a briga por CPU entre processos que deveriam ser sequenciais.
- Memória: A pressão de memória, muitas vezes causada por payloads massivos, foi mitigada processando dados em chunks menores, evitando carregar grandes conjuntos de dados inteiramente na RAM.
Trade-offs: Vertical vs. Horizontal Scaling
Não existe bala de prata. O scale-up (vertical) é ideal para estabilização imediata sem alterações arquiteturais, enquanto o scale-out (horizontal) é essencial para o longo prazo. O segredo da resiliência reside no meio-termo: combinar escalabilidade horizontal com restrições severas de concorrência.

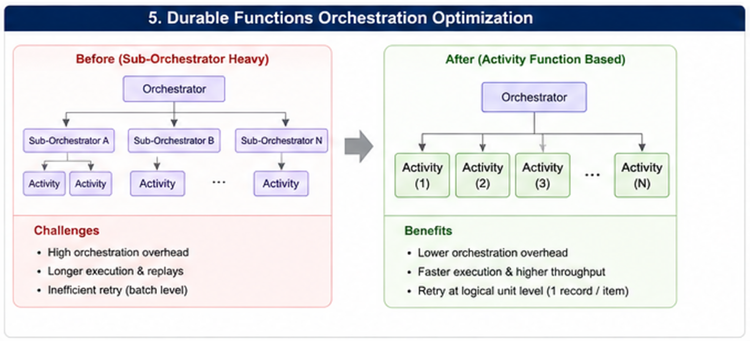
Refatorando Durable Functions
Durable Functions são poderosas, mas o aninhamento excessivo de sub-orchestrators cria um overhead de replay e persistência que degrada a performance. Ao reestruturar fluxos para Activity Functions simples, reduzimos significativamente a latência e os custos de infraestrutura. Além disso, uma estratégia de retry que respeita a unidade lógica de trabalho isola falhas, evitando que uma única falha de lote reprocessasse milhares de registros com sucesso.
Higiene de Banco de Dados e Observabilidade
O banco de dados é habitualmente a vítima da ineficiência da aplicação. A fragmentação de índices e estatísticas obsoletas tornam planos de execução ineficazes. Programar rotinas de index rebuild e update statistics é inegociável. Para arquiteturas multi-tenant, a execução em modo singleton de tarefas intensivas garantiu uma distribuição de carga mais justa.
A observabilidade end-to-end é o que separa um engenheiro de um adivinhador. Sem rastreamento de nível de aplicação e correlação de load testing, é impossível diferenciar um gargalo de DB de um erro de orquestração.
Perguntas Frequentes
-
Por que o escalonamento horizontal automático (autoscale) pode piorar a performance?
O escalonamento agressivo pode gerar um efeito cascata, aumentando o tráfego em bancos de dados, elevando a contenção de locks e intensificando o número de retries, o que satura os recursos downstream em vez de aliviar a carga. -
Como as Durable Functions influenciam a latência em sistemas de alta escala?
O uso excessivo de sub-orchestrators aninhados na Azure Durable Functions gera alto overhead de orquestração e operações de persistência redundantes. Refatorar essas estruturas para Activity Functions mais granulares melhora o throughput e reduz custos. -
Qual é o papel da higiene de banco de dados na estabilidade da aplicação?
Em ambientes de alta transação, a fragmentação de índices e a desatualização de estatísticas degradam planos de consulta. Manutenções proativas e a execução de processos pesados via padrão 'singleton' em nível de tenant evitam gargalos críticos.
Artigo originalmente publicado em Azure Updates - Latest from Azure Charts.
