

O desafio da fragmentação na era das LLMs on-device
O TL;DR: O Google AI Edge Portal agora suporta benchmarking e debugging automatizados para LLMs rodando diretamente em dispositivos Android. Com suporte a mais de 120 tipos de dispositivos, a ferramenta permite analisar métricas críticas como latência, prefill, decode e uso de memória. Para gestores e engenheiros, a conclusão é clara: a fragmentação do ecossistema Android exige validação baseada em dados reais, e o Portal torna o diagnóstico de gargalos em modelos genAI um processo sistemático e eficiente.
Embora os LLMs tenham se tornado mais compactos e capazes, o deploy em ambientes de borda (edge), especialmente celulares, permanece um desafio crítico de engenharia. A realidade para os times de desenvolvimento é lidar com uma combinação complexa de aceleradores, versões de SO e inúmeras configurações de System-on-a-Chip (SoC). Historicamente, isso resultava em testes manuais limitados a um pequeno grupo de aparelhos, expondo o produto a riscos de user experience inconsistente.
O Google AI Edge Portal surge para tangibilizar esse cenário, permitindo que engenheiros testem workloads de ML em uma frota de mais de 120 tipos de dispositivos Android, coletando insights profundos sobre a latência e a performance sob backends de CPU, GPU e NPU.
Benchmarking de LLMs em escala: o que monitorar?
Quando uma aplicação integra um LLM, o usuário espera uma resposta quase instantânea. Problemas como tempo excessivo de inicialização podem fazer o app parecer congelado, enquanto modelos que exigem memória acima da capacidade do aparelho podem causar crashes graves. Com a atualização recente, o Portal suporta benchmarks automatizados de gen AI para modelos no formato LiteRT-LM.
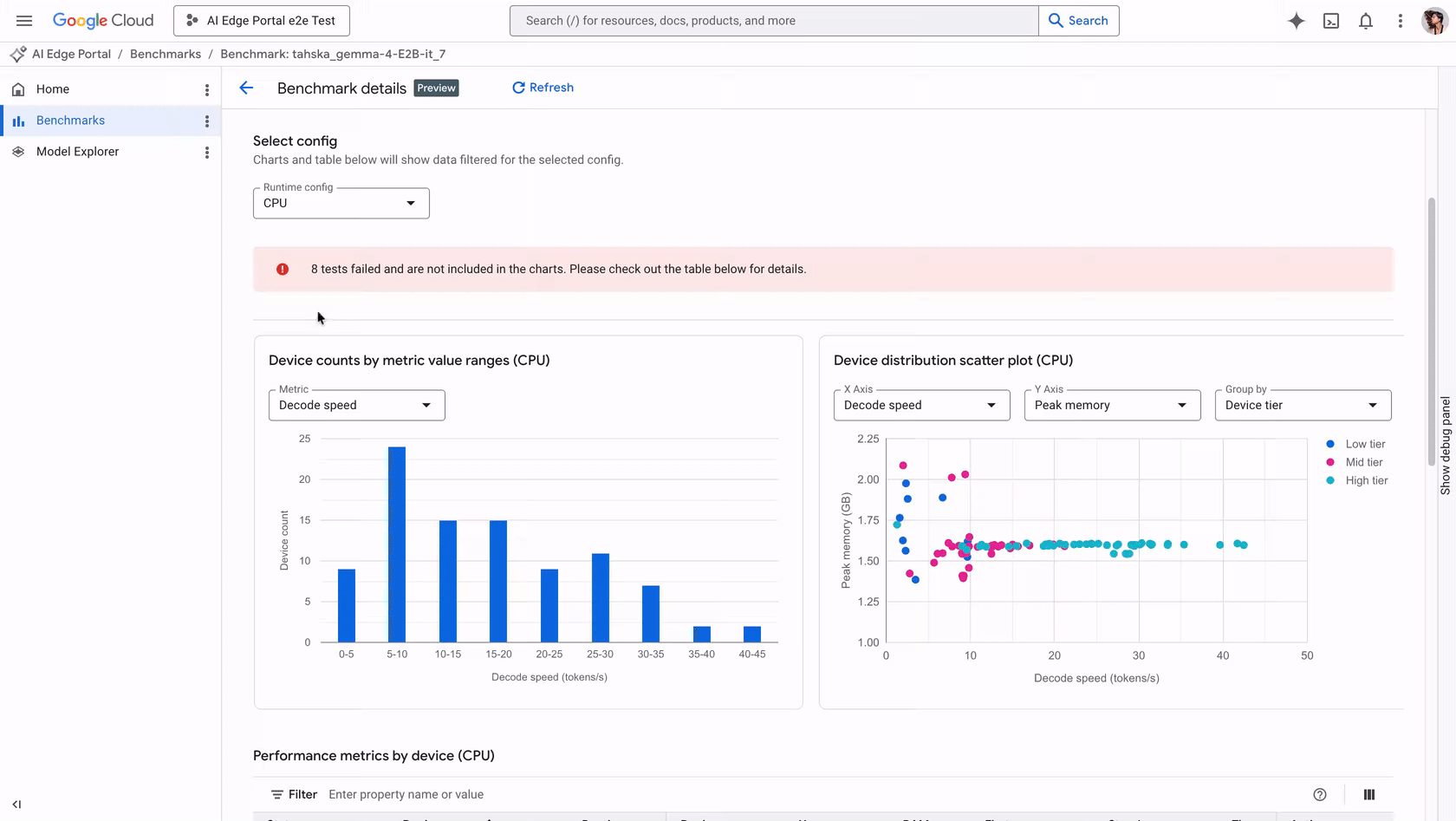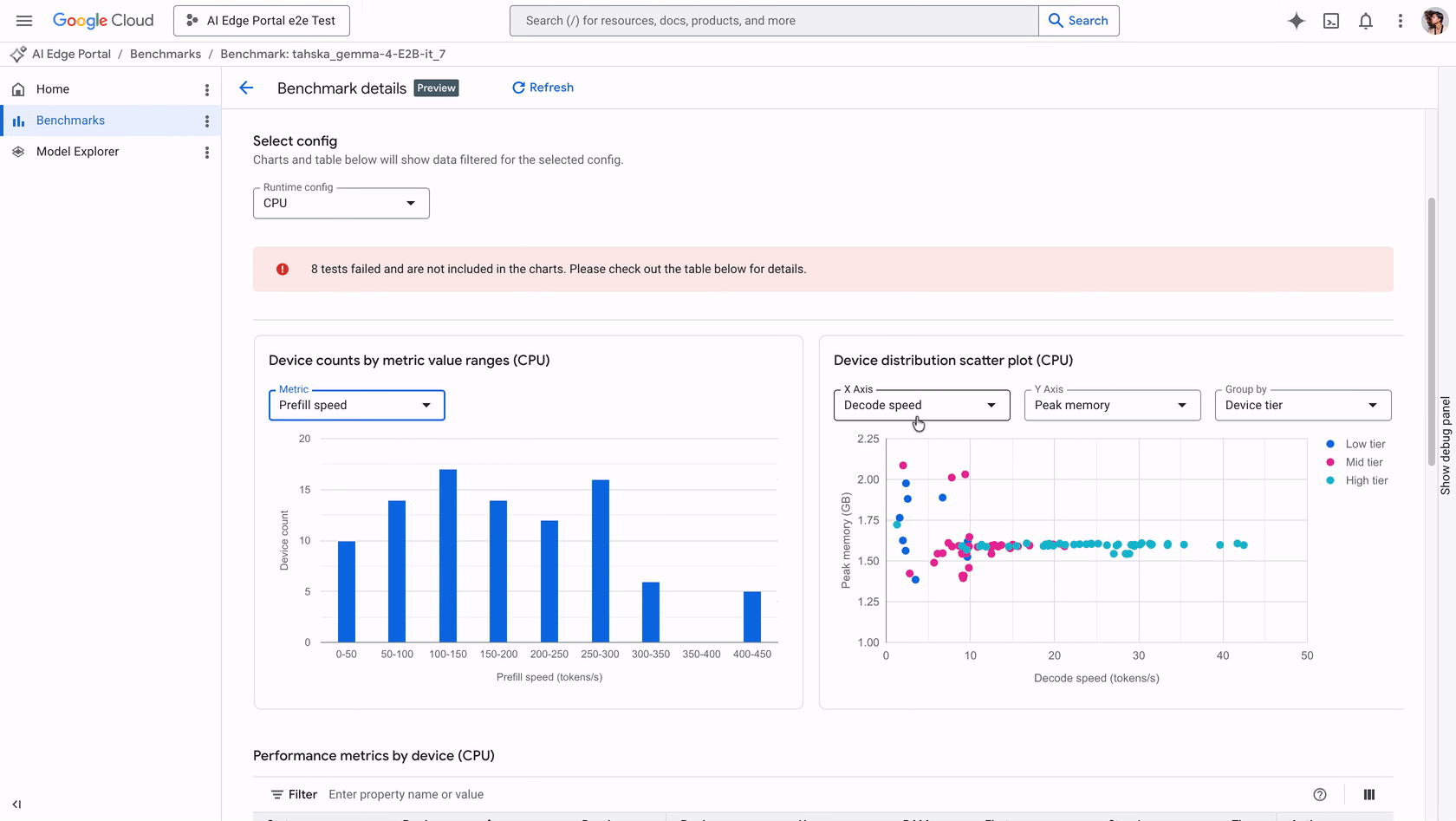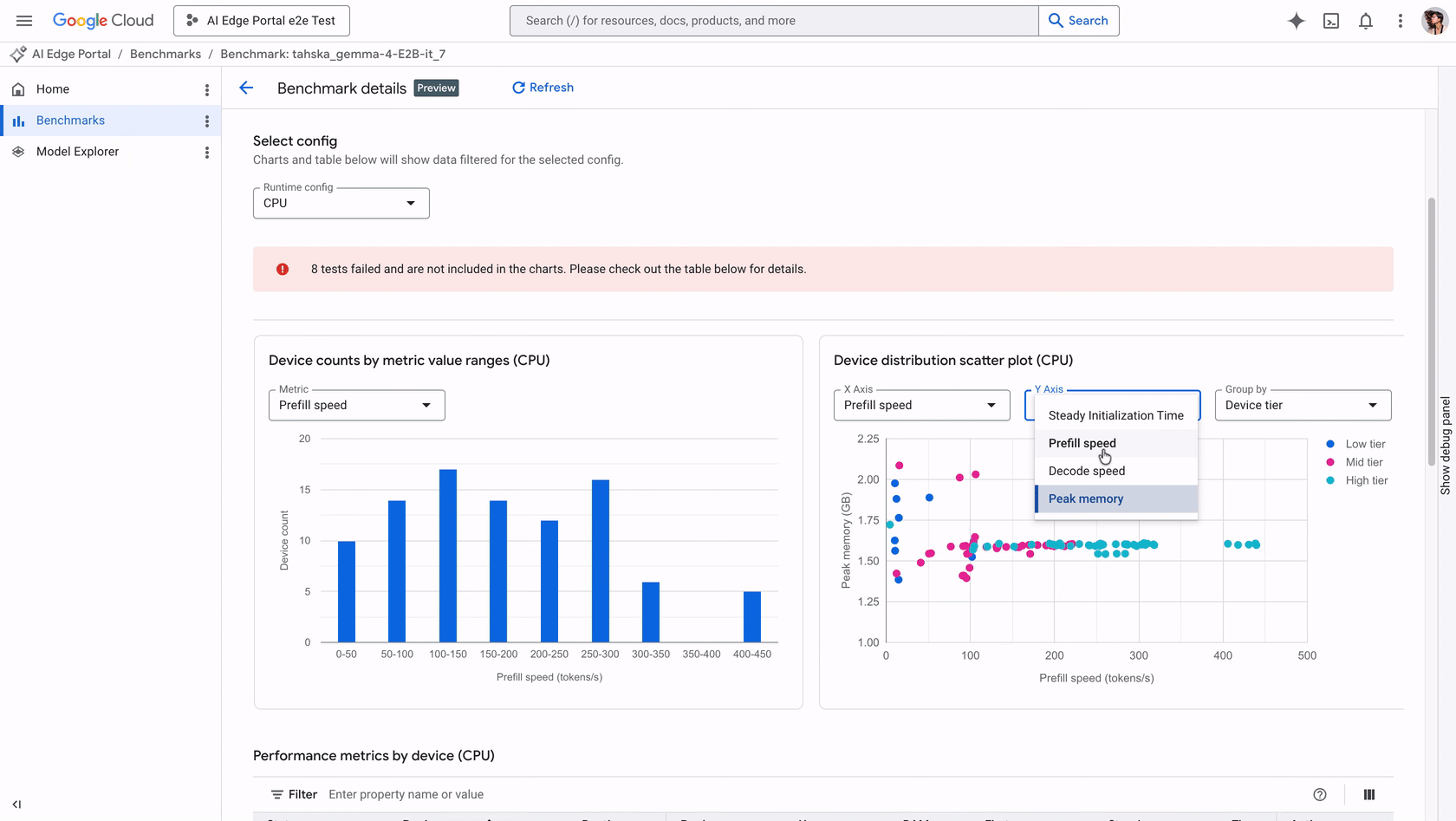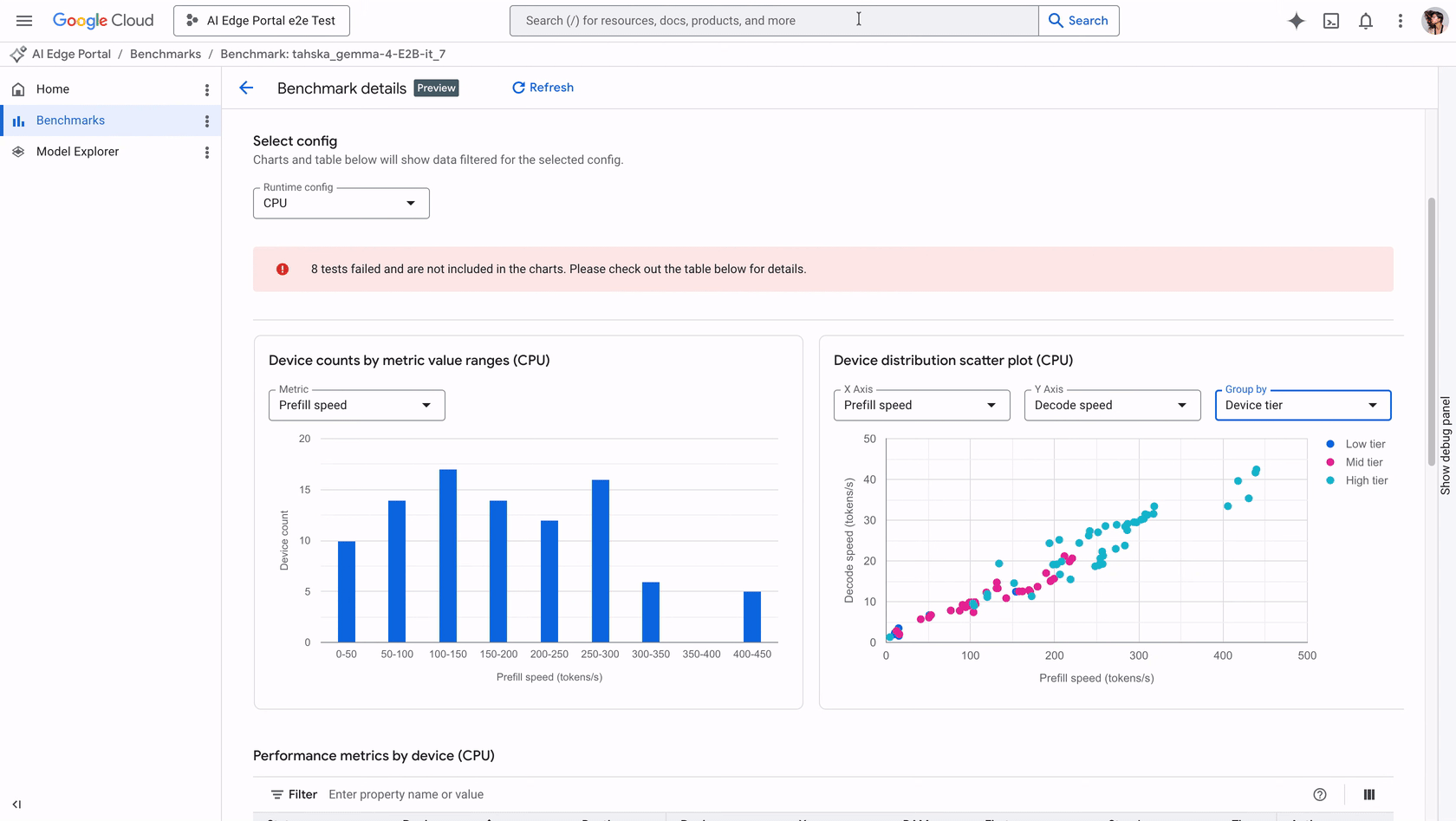
Ao executar um job de benchmark, a solução profile as métricas fundamentais que ditam a experiência do usuário:
| Métrica | O que mede? | Impacto no Negócio |
|---|---|---|
| Initialization time | Tempo de carga do modelo na memória. | Evita delays críticos ou congelamento do UI no startup. |
| Prefill speed | Velocidade de processamento do prompt. | Define o tempo de espera inicial antes da resposta. |
| Decode speed | Velocidade de geração de tokens. | Determina a fluidez da resposta final ao usuário. |
| Peak memory | Uso máximo de RAM. | Previne o risco de crash por falta de memória (OOM). |
Como otimizar a performance com o Model Explorer?
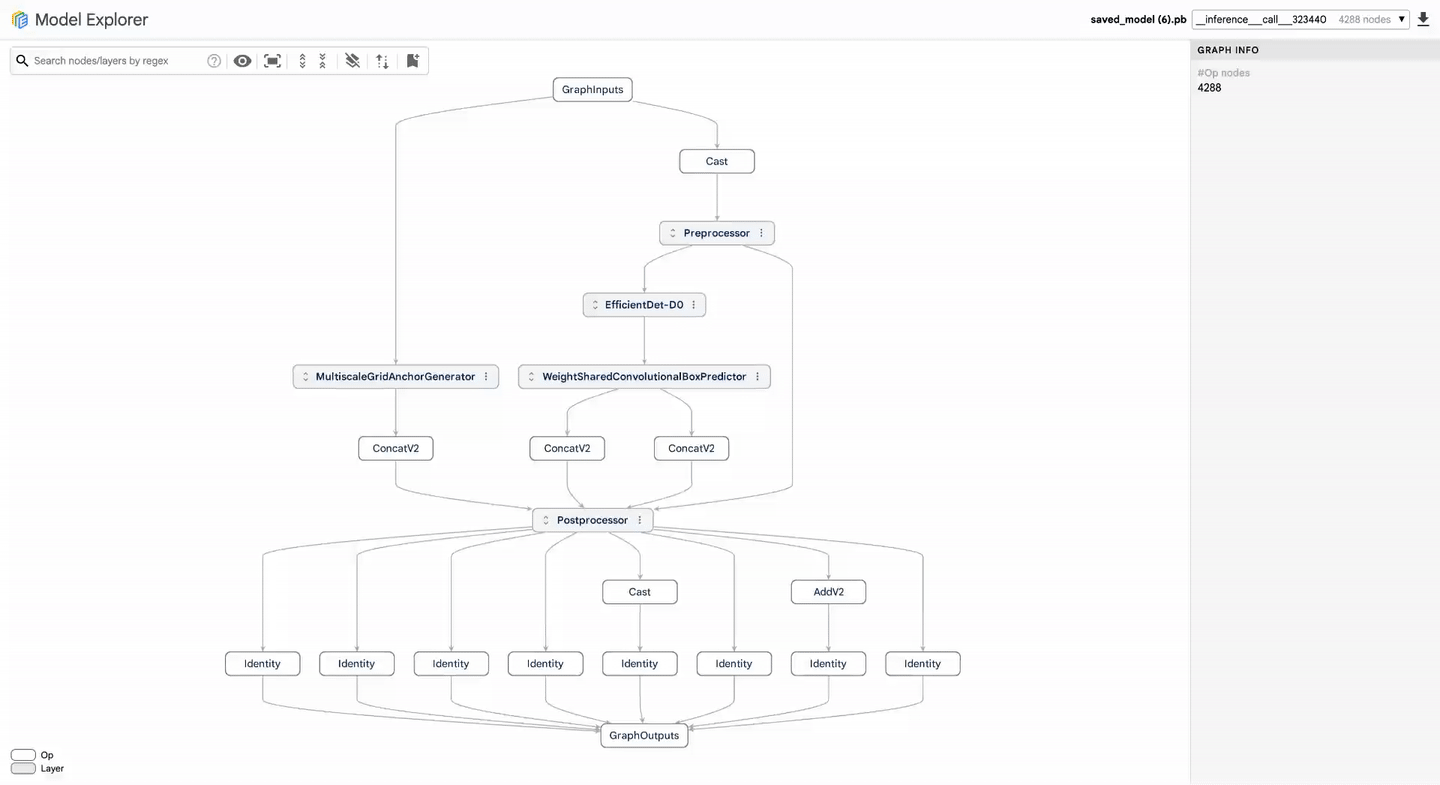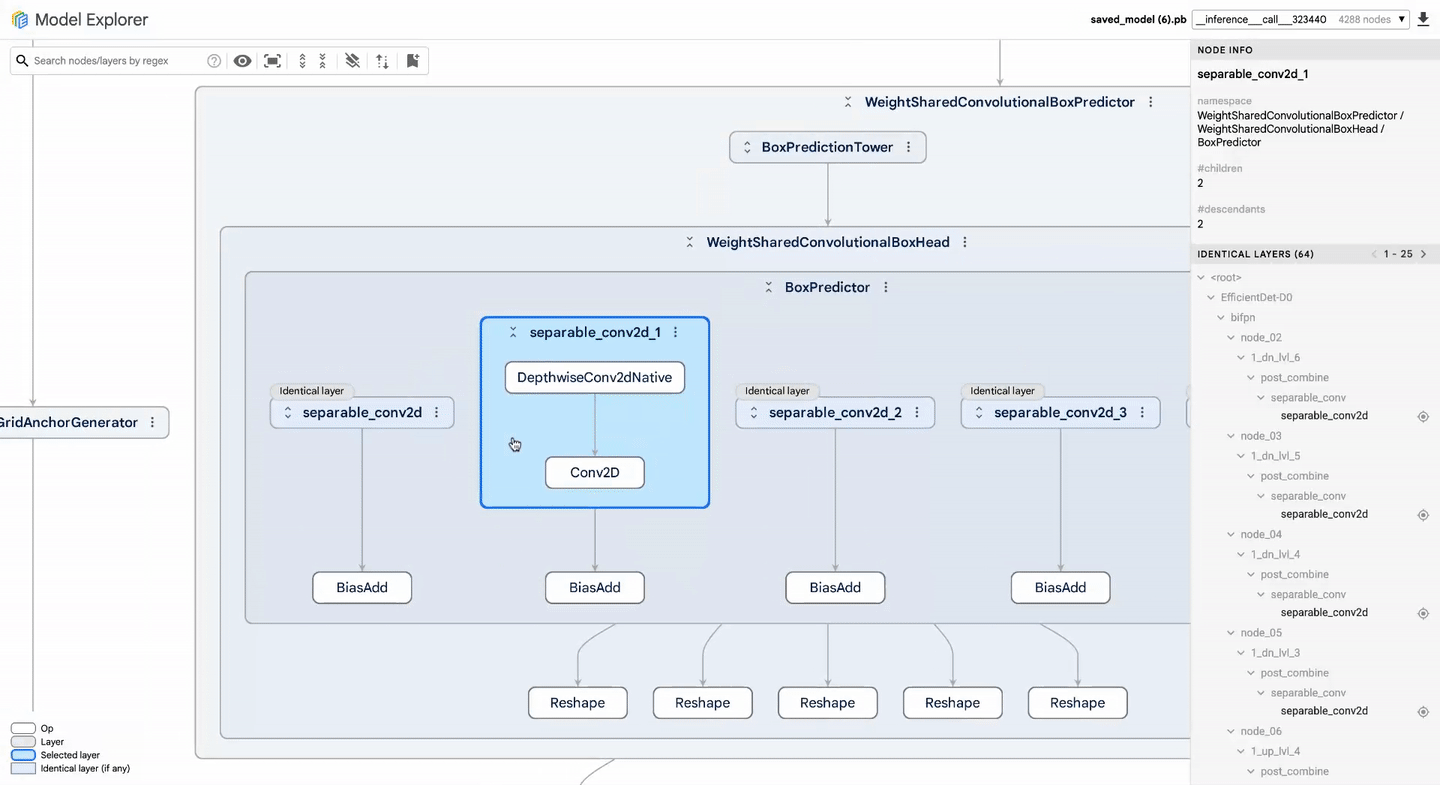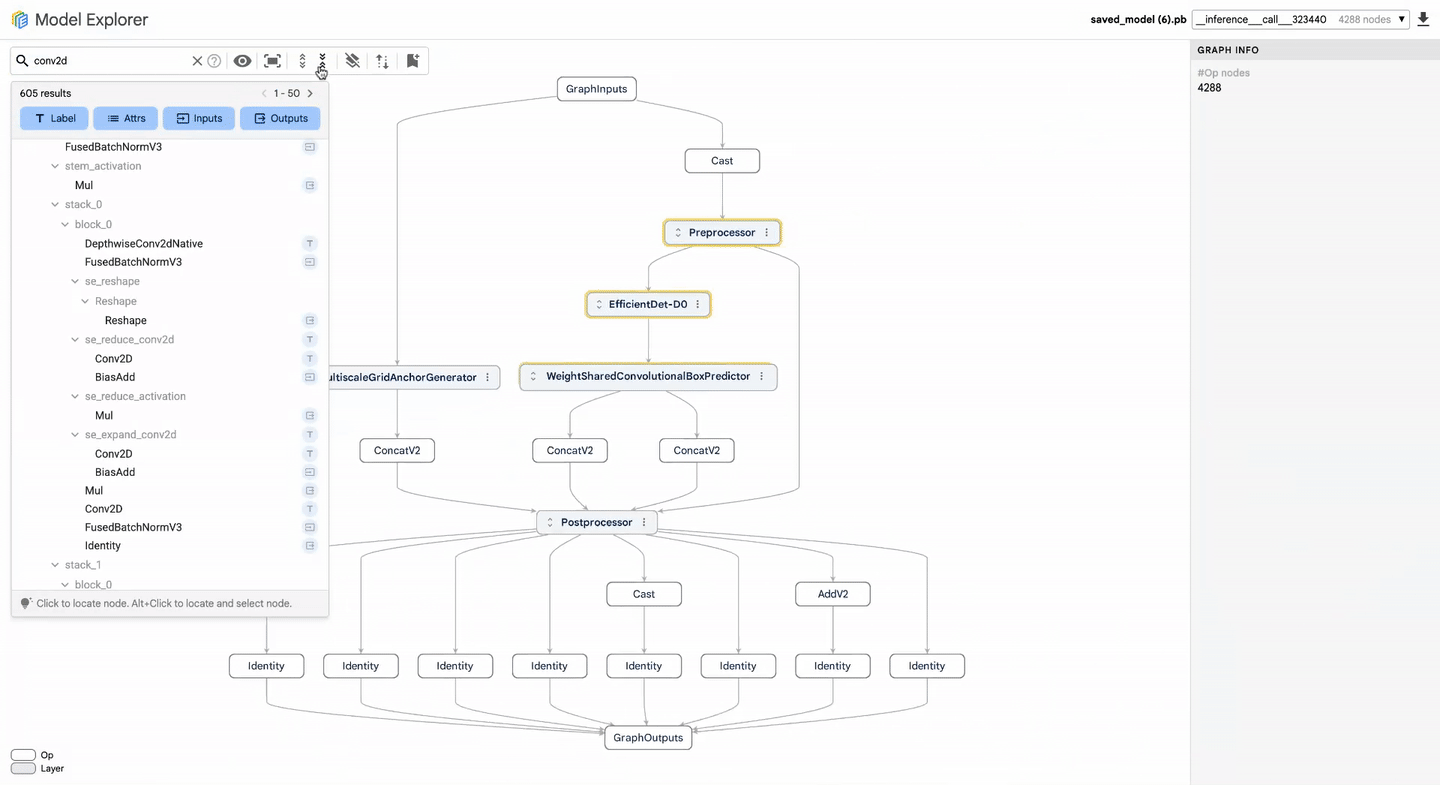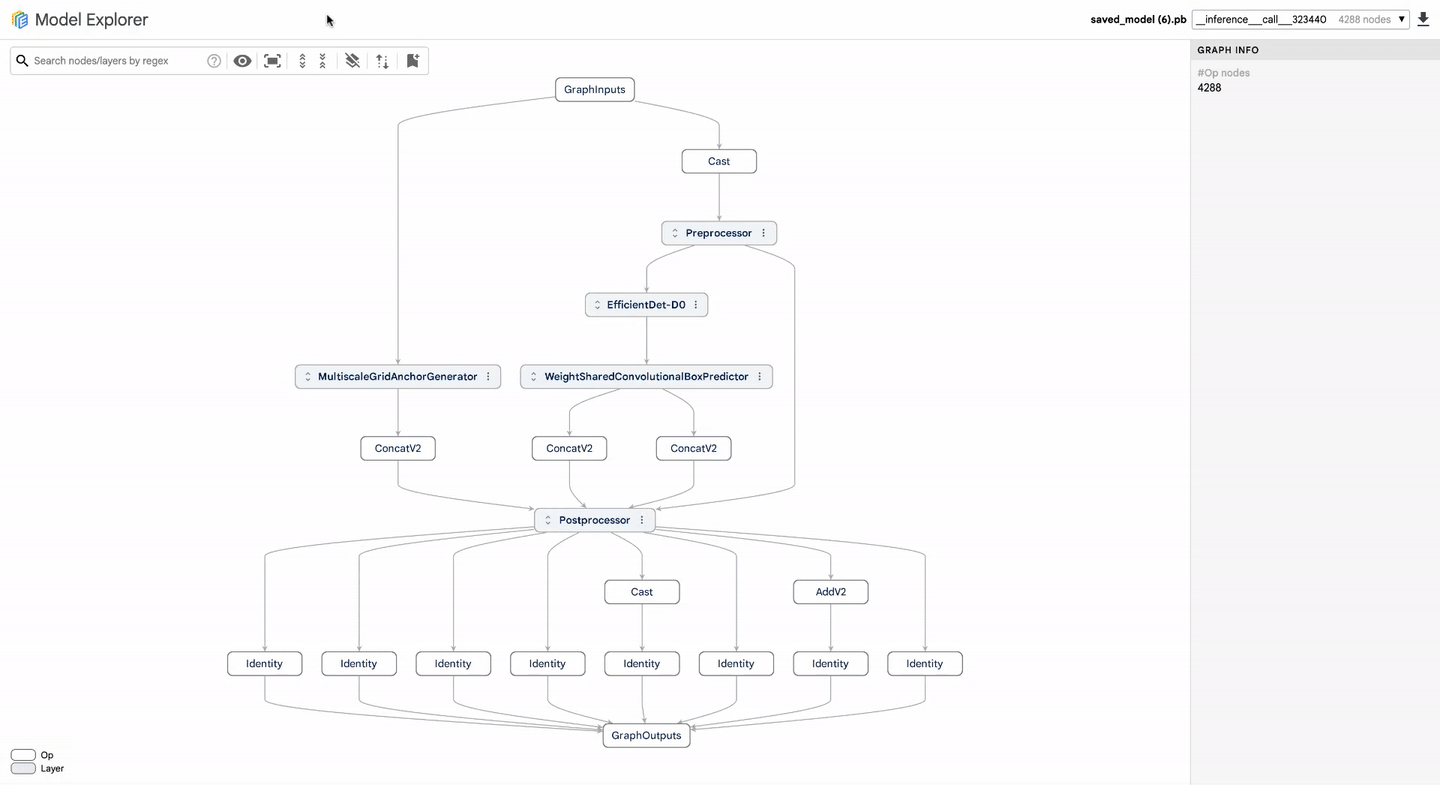
Identificar que um modelo está lento é o primeiro passo; localizar o gargalo dentro de um grafo de milhares de nós é o desafio real. Para reduzir o tempo de debugging de dias para horas, o Google integrou o Model Explorer.
Essa ferramenta de visualização permite comparar grafos lado a lado, facilitando diagnósticos em:
- Conversion: Analisar dependências internas e nós estruturais ao expandir ou colapsar camadas do modelo.
- Quantization: Identificar operações onde a compressão afeta a performance negativa, comparando métricas de erro para atingir o equilíbrio ideal entre tamanho de modelo e precisão.
- Optimization: Visualizar a compatibilidade do hardware e organizar operações por latência, comparando comportamentos entre diferentes aceleradores.
Próximos passos para o seu stack de IA
A era das LLMs on-device exige uma mudança de mentalidade no fluxo de CI/CD: o teste não termina no servidor; ele termina no hardware do usuário final. Para empresas que dependem de aplicações de IA escaláveis, o uso de ferramentas de automação como o AI Edge Portal será um diferencial competitivo na oferta de uma experiência estável e performática.
Atualmente em private preview, o serviço já está disponível para clientes permitidos no Google Cloud. Para times de engenharia no Brasil, a recomendação é iniciar o mapeamento dos hardwares mais utilizados pelos seus usuários finais para quando essa capacidade estiver disponível para o público geral.
Perguntas Frequentes
-
Quais métricas de performance o Google AI Edge Portal disponibiliza?
O portal mensura métricas fundamentais como Initialization time (carga na memória), Prefill speed (processamento de tokens de prompt), Decode speed (geração da resposta) e Peak memory (uso máximo de RAM durante a execução). -
Como o Model Explorer ajuda na correção de falhas em modelos?
Ele permite a visualização e comparação de grafos de modelos, oferecendo busca por nós específicos, análise de shapes de tensores e identificação de problemas de quantização ou compatibilidade de hardware entre camadas. -
O acesso ao Google AI Edge Portal é aberto para qualquer desenvolvedor?
O serviço está atualmente disponível apenas em private preview para clientes Google Cloud selecionados (allowlisted), sem custo adicional durante esta fase de testes.
Artigo originalmente publicado por Derek BekebredeProduct Manager, Google em Cloud Blog.
