

O gargalo invisível: Quando o compute não acompanha a velocidade do dado
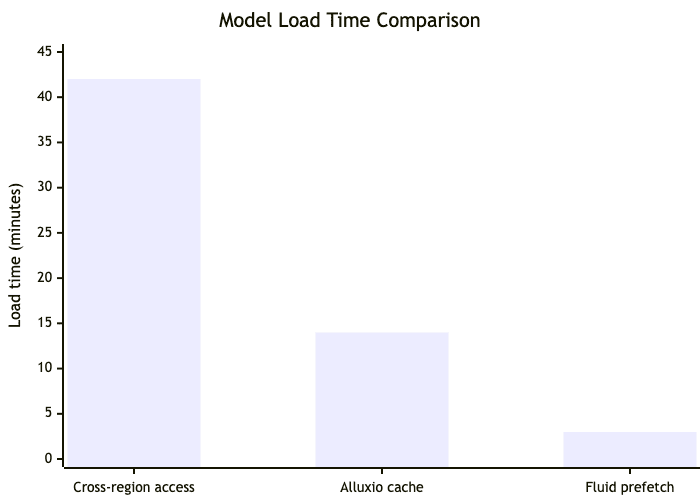
Este artigo analisa como a NetEase Games superou latências proibitivas em inferência de LLMs no Kubernetes, movendo o foco do poder computacional para a orquestração de dados. A conclusão é que o autoscaling de GPUs é ineficaz se o acesso aos pesos do modelo for lento. Ao adotar o framework Fluid para gerenciar o cache de datasets, a empresa reduziu tempos de carregamento de 42 minutos para menos de 30 segundos, otimizando custos e eficiência operacional.
A equipe de engenharia da NetEase Games identificou um desafio crítico: a infraestrutura serverless para GPUs, embora atraente para cargas de trabalho de IA, falha quando o gargalo é o data path. Em modelos de 70B parâmetros, trazer centenas de gigabytes de pesos de um armazenamento remoto para os nós de inferência tornava o autoscaling irrelevante devido ao tempo total do deployment.
“Elastic compute is only useful if data can move just as fast.”
O problema de Day 2: Cold starts e fragmentação
Operacionalmente, a plataforma Tmax, baseada em Kubernetes, enfrentou três desafios que impediam a escalabilidade eficiente:
- Escassez e heterogeneidade de GPUs: Manter capacidade provisionada para cenários de pico em diferentes títulos (jogos) era financeiramente insustentável.
- Tráfego não uniforme: A provisão estática elevava o desperdício em janelas de baixa demanda.
- Custo do cold start: O carregamento do modelo tornava-se o fator dominante no tempo de resposta, mesmo com recursos de computação disponíveis.
Fluid: Simplificando a orquestração de dados
Em vez de gerenciar clusters de armazenamento isolados, a escolha pelo Fluid permitiu que a organização tratasse datasets como objetos de primeira classe no Kubernetes. A tabela abaixo resume as mudanças operacionais:
| Dimensão | Desafios com Alluxio puro | Benefícios com Fluid |
| Integração K8s | Gerenciamento manual de pods/masters | Automação de ciclo de vida e agendamento data-aware |
| Otimização LLM | Customização complexa de warmup | Workflow de prefetching nativo e otimização para vLLM |
| Compartilhamento | Configuração manual entre namespaces | Isolamento lógico e reuso seguro de modelos |
O impacto real em produção
Essa mudança foi disruptiva. A otimização através do prefetching e do cache compartilhado reduziu o tempo de startup de 42 minutos para aproximadamente 30 segundos. Para gestores de TI, isso significa que a estratégia de "scaling-to-zero" torna-se viável, permitindo um uso de infraestrutura mais agressivo e, consequentemente, uma redução direta na conta de nuvem.
Onde investir o esforço?
A lição fundamental aqui não é sobre a tecnologia de storage em si, mas sobre a orquestração. Se o seu desafio de MLOps envolve prefetching, escalabilidade e multi-tenancy, o modelo de abstração do Fluid é um caminho mais robusto do que manter manualmente camadas de cache sobrepostas ao Kubernetes.
Perguntas Frequentes
-
Por que o autoscaling de GPUs falha ao carregar LLMs?
O autoscaling responde rapidamente à demanda de compute, mas se o pipeline de dados (o carregamento dos pesos do modelo) for lento, o Pod permanece em estado de 'cold start' por minutos, tornando a elasticidade inútil para picos de tráfego repentinos. -
Qual a principal vantagem de usar o Fluid sobre o Alluxio puro?
O Fluid provê uma camada de abstração K8s-native que automatiza o ciclo de vida do cache e permite o prefetching inteligente, enquanto o Alluxio sozinho exige gerenciamento manual severo entre namespaces e falta integração nativa com o agendamento de recursos do Kubernetes. -
Como o compartilhamento de datasets via Fluid impacta os custos?
Ao permitir o compartilhamento de modelos base entre múltiplos namespaces, o Fluid reduz o consumo redundante de memória de cache, evitando caches duplicados do mesmo modelo para times diferentes.
Artigo originalmente publicado por Haifeng Liao, Senior Infrastructure Engineer at NetEase Games and Xiang Zhang, Head of AI Infrastructure at NetEase Games em Cloud Native Computing Foundation.
